こんにちは、Sansan Engineering Unit マスターデータグループの金子です。
私たちが開発しているシステムの中に、MongoDBを採用しているシステムがあります。私自身NoSQLを使用しているシステムの開発に携わるのは初めてなので、毎日いろいろな学びを得ています。 ある時、そのシステムで大量のデータをDBに書き込む処理を行うと、MongoDBのoplog関連のエラーが出てしまったことがありました。今回はその時の原因と対応について紹介し、MongoDBのoplogについて理解を深められた話をします。
環境
- MongoDB 5.0
- MongoDB Atlas
発生したエラー
エラーの文言はこちらです。
PlanExecutor error during aggregation :: caused by :: Resume of change stream was not possible, as the resume point may no longer be in the oplog.
直訳すると、「再開ポイントはもうoplogの中にないから、change streamの再開が不可能だよ」となります。
システム構成
エラーの文言の中にchange streamという単語が出てきました。これはMongoDBの機能の1つです。
Change Streams - Database Manual - MongoDB Docs
この機能を使うと、DBへの変更を逐一受け取り、それを受けて何かしらの処理を行えます。私たちが開発しているシステムでは、会社の情報や事業所の情報などを編集できます。その際、どの情報を誰が編集したかなどの編集履歴を残すことが重要になります。 そこで、そのシステムではchange streamを使い、会社や事業所などデータの性質に関わらず、すべてのデータを編集履歴コレクションに保存します。そしてその保存で発生したchange streamを使い、データごとのコレクションのデータを更新する、といった構成を取っています。
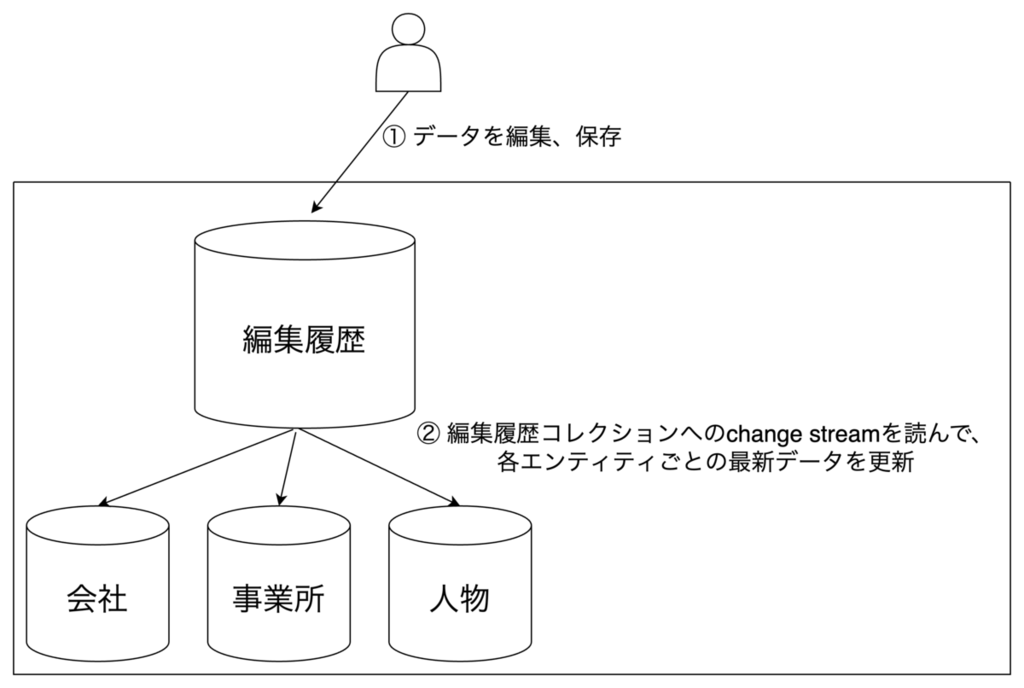
MongoDBのoplogとは何か
MongoDBのoplogとは、operation log、つまりDBへのオペレーションを記録したログです。
Replica Set Oplog - Database Manual - MongoDB Docs
オペレーションというのは、DBへのデータの挿入や削除といった操作を指します。MongoDBでは、プライマリからセカンダリへのレプリケーションや、先ほど紹介したchange streamなど、さまざまな機能がoplogを使って実現されています。 注目すべき点は、oplogがcapped collection、つまり、固定長であることです。すべてのオペレーションのログを保存しているわけではなく、あらかじめ割り当てられたメモリを超過した場合、古いものから消されていきます。
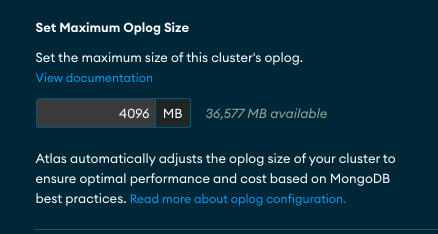
以下は、そのシステムのステージング環境での設定例です。oplogの容量として、4096MBが設定されていました。
エラーの原因調査
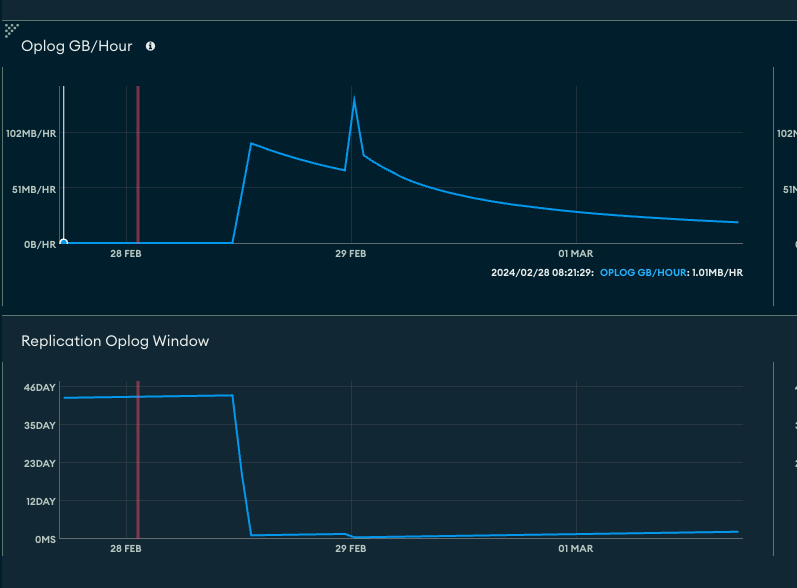
change streamの裏で働くoplogについて理解ができたところで、該当の処理を行った際のメトリクスを確認しました。すると、該当の処理実行中、Oplog GB/hourは大幅に上昇し、Replication Oplog Windowは急激に減少していました。
Oplog Windowとは
MongoDBのoplogには、Oplog Windowの概念があります。
Replica Set Oplog - Database Manual - MongoDB Docs
oplogにはタイムスタンプが記録されており、最も古いオペレーションと、最も新しいオペレーションのタイムスタンプの差がOplog Windowとなります。これが減少しているということは、最新のoplogと最古のoplogのタイムスタンプにほとんど差がない、つまり大量のオペレーションが短期間に流れたことを意味します。
ここまでで、エラーの原因については当たりがつきました。 大量のデータを短期間で書き込んだために、oplogには一気に大量のオペレーションが流れます。change streamは先頭から1件ずつ、再開ポイントを記録しながらデータを処理しますが、再開ポイントが大量のデータに押し出されてしまい、再開する術を失ってしまったと考えられます。
実際に行った対応
エラーの原因について見当がついたところで、対応策を考えました。
- 短期間に大量のデータの書き込みを行わないように、アプリケーション側の実装を変更する。
- oplog sizeを大量に確保し、再開ポイントが押し出されないようにする。
- Minimum Oplog Window を設定し、設定した期間のうちはchange streamが再開ポイントを見失わないようにする。
選択肢1の「実装を変更する」は、大がかりな工事になってしまうので選択できませんでした。必然的に選択肢は2か3の二択になります。どちらも、大規模なデータの処理に必要なoplogをどのように確保するかという話になります。エラーの調査を行なっていくにつれて、oplogを確保するには2通りの方法があることが分かりました。
1つは選択肢2の「oplogのメモリ容量を大量に割り当てること」、もう1つは選択肢3の「Minimum Oplog Windowを設定すること」です。後者はOplog Windowの最低値を設定することで、設定した時間中はchange streamを再開できるようにする方法です。例えば、3時間で設定しておけば、どれだけ大量のオペレーションが流れたとしても3時間の間は再開ポイントを見失わずに済みます。
この挙動を踏まえて、選択肢2と選択肢3を比較しました。該当の処理において、oplogのメモリ容量がどれほど必要かを見積もることは難しいですが、少なくとも何時間以内に終わるかは分かりました。そこで、私たちのチームでは選択肢3を取ることにしました。処理は少なくとも3時間もあれば完了するので、余裕を持ってMinimum Oplog Windowを12時間に設定しました。
その後、再度同じ処理を行うと、同じエラーが再現せずに無事にデータ更新を完了できました🙌
注意点
この対応ではMinimum Oplog Windowを12時間に設定しました。この設定によって意図せずoplogのサイズが肥大化してしまう可能性があることにはご注意ください。
また、MongoDB Atlasでは、Minimum Oplog Windowの設定はオートスケーリングを有効にしている際にしか設定できません。
Configure Additional Settings - Atlas - MongoDB Docs
まとめ
このエラー調査、対応を通して、私は以下のことを学びました。
- MongoDBのoplog、change streamの挙動について
- エラーに対して手当たり次第に考えられる手段を試すのではなく、メトリクスを確認して根本原因を探ること
- エラー対応を考える際には複数案を挙げ、どれが最も適しているか検討すること
今後も「推測するな、計測せよ」の精神で物事に当たっていきたいです。
最後に、私たちのチームではWebアプリ開発エンジニアを募集しています。Webアプリ開発だけではなくデータエンジニアリングなど、幅広い業務を経験できます!ぜひ私たちと一緒に働きましょう!
学生向けインターンも募集中です!
https://open.talentio.com/r/1/c/sansan/pages/76521open.talentio.com
