Hi, I'm Juan Martínez, Researcher at Sansan's R&D Department.
During the last year our team has been building a growing number of applications that leverage the power of Large Language Models (LLMs) to activate the business data of Sansan users through our experimental applications platform Sansan Labs.
Experimenting with LLMs has helped us understand their use cases and learn new techniques to overcome their limitations. You can learn more about the Generative AI apps we offer to our users here (in Japanese).
As LLMs become more popular, they are also becoming more accessible. There's a great variety of Open Weights models out there that can be used for free, and some of those are scoring very closely to the best models in several key benchmarks.
In this article I'd like to introduce an easy way of employing LLMs to automate daily tasks on your Mac computer using the Shortcuts feature in macOS with Ollama.
We will build a Shortcut that uses an LLM to extract information about the websites you open on Safari. I will also show you how to run an LLM task at a given schedule with Shortcuts and crontab Let's get into it!
About Shortcuts on macOS
Have you ever opened the Shortcuts app on your Mac? For some reason most of the people I know haven't.
It seems like Shortcuts is one of those less known features of macOS that happen to be super useful. According to Apple's documentation:
A shortcut provides a quick way to get things done with your apps, with just a click or by asking Siri.
Shortcuts can automate a wide variety of things—for example, getting directions to the next event on your Calendar, moving text from one app to another, generating expense reports, and more.
In short, Shortcuts is the way you program your Mac to perform custom tasks. Shortcuts are created by chaining Actions together. For example, consider the following Shortcut made out of three actions:
Send GIF
- Get the latest 5 photos from your gallery
- Turn them into a GIF
- Send the GIF to some of your contacts via Messages
Now imagine that you can do that with a single Siri command or keyboard combination. That's a macOS Shortcut!
There are a LOT of actions that you can use to build your Shortcuts: opening a web browser window, printing, locking your screen, making requests to an arbitrary API, etc.
Check out the docs here:
About Ollama
Ollama is a tool that allows you to run LLMs on your machine. It is available for macOS, Windows and Linux, and supports many of the most popular language models, such as LLama 3, Google's Gemma, the Mistral models, and many more.
You can get it from here:
Downloading and using a language model is as easy as running ollama run llama2 on your terminal. Ollama is nice because it makes it very easy to use language models for free on your own machine.
Besides the command line interface, Ollama also runs in the background a local web server that you can access through HTTP requests to generate text using the language model of your choice.
Using Ollama on your Shortcuts
Since Shortcuts support actions for calling web APIs, and Ollama exposes an API on your computer, it is quite easy to make LLMs cooperate with the other apps and features on your Apple machine. Let's go step by step:
Preparing your LLM
This part is super easy. Just go to Ollama's website, click the install button and follow the instructions.
Once it's installed and running, you should be able to point your web browser to http://localhost:11434/, and see a message telling you that Ollama is running.
Now we're going to download the Language Model. You have many choices, so choose the one that fits your needs and your resources best. *1
Given the memory available on my system, my choice is mixtral, a Sparse Mixture of Experts LLM, which is memory-efficient, fast and performs well in general.
You can download it by running ollama pull mixtral on your terminal. The 8x7b version of Mixtral is 26 GB, so it takes a bit of time.
More about Mixtral here:
Building Your Shortcut
Now's when the fun begins. We will create a Shortcut that lets you make questions about a web page you have opened in Safari. I tried this flow in Ollama 0.1.32 with macOS Sonoma.
First open your Shortcuts app. It's the one with an icon like this one:
![]()
Now, follow the instructions here to create a new Shortcut and replicate the following chain of actions:
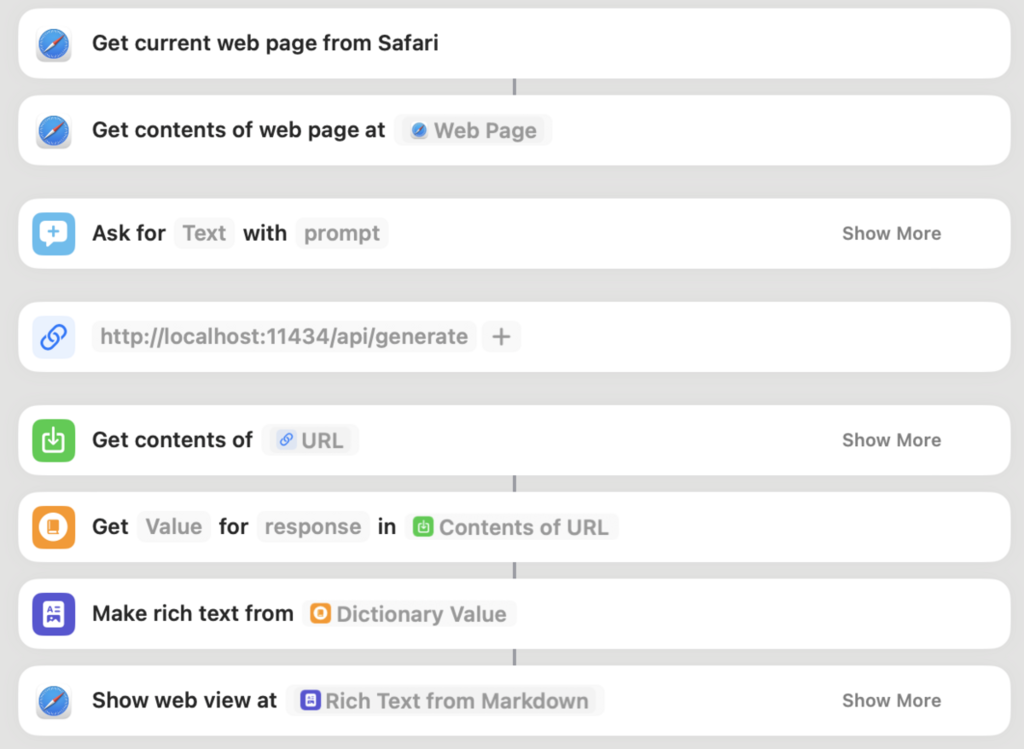
There are eight actions chained together. Let me explain them in order:
- Get current page from Safari: obtain a reference to the active Safari tab.
- Get contents of web page at
Web Page: this one retrieves the text content of the web page. - Ask for
Textwithprompt: this one displays a text input window to the user. You will use it to input your question. - URL: This one contains a reference to
http://localhost:11434/api/generate. This is Ollama's API endpoint for generating text using a given LLM. - Get contents of
URL: here's where you specify the method and the body of your request. More on this in a second. - Get value for
responseinContents of URL: This action receives the response from the API, which is a JSON object containing a key calledresult, which is where the text generated by the LLM is contained. - Make rich text from
Dictionary Value: as you'll see in a second, we're asking the LLM to respond in Markdown. We turn that content into a format that can be displayed in a web view using this action. - Show web view at
Rich Text from Markdown: Displays the LLMs response on a web browser window.
About the request to Ollama's API:
Now let's see the details of Action 5, the HTTP request:

You can see that we use the POST method and that the request's body is formatted as JSON. The body contains three arguments: the model, the prompt and a streaming flag.
The model is mixtral, and streaming is set to False (for simplicity, we want to wait for the whole response before passing the result to the next action).
As for the prompt, you can employ the following text:
Respond to the user's question or instruction based on the context provided. Your response should be brief and be formatted as valid Markdown. The context:【Contents of Web Page】. The question:【Provided Input】. Your response:
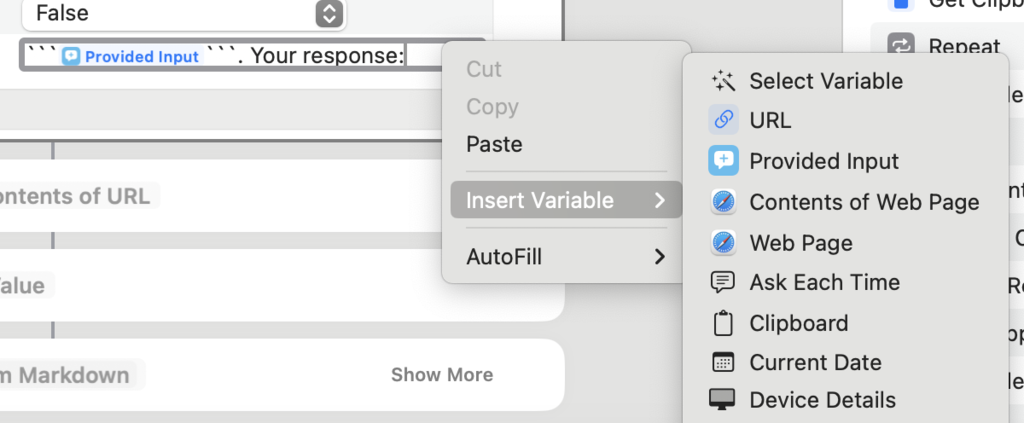
Where the【Contents of Web Page】variable refers to the contents extracted from Action 2, and 【Provided Input】refers to the question introduced by the user in Action 3.
These two variables can be added by using the Insert Variable menu that appears when you right click on the field where you set the value of the prompt property.
When you're done recreating the Shortcut above, name it Webpage Q&A.
Let's try it!
If you followed all the instructions without problem, you should now be able to use your LLM to ask questions about your web pages.
First, open a Safari window and open Ollama's blog:
https://ollama.com/blog
Now go back to the Shortcuts app and open your Shortcut. Press the Run button on the top right of the app to start your Shortcut.
After about one or two seconds a small window asking you to introduce some text will be displayed:
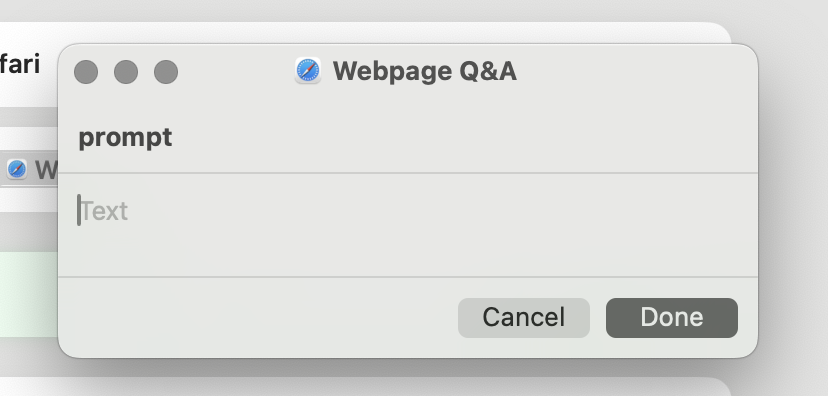
Introduce your question and press Submit. My question was: "I'm an Economist. Please suggest a blog post that I might be interested in and explain why."
After a few seconds (depending on the specs of your Mac), you should finally be able to see a response appear on the web view just like below:
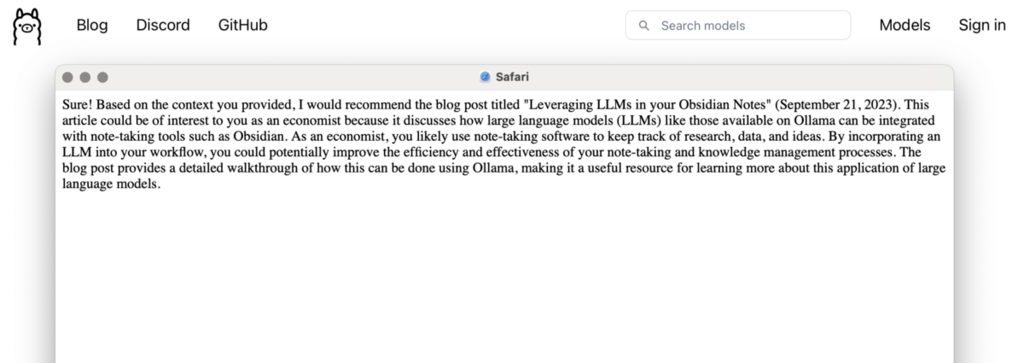
It recommended the following article:
Leveraging LLMs in your Obsidian Notes · Ollama Blog
Indeed, taking notes and keeping them organized are important tasks for a researcher, so maybe I should read it. Also, I didn't know about about Obsidian, but it looks very useful, maybe I will try it. Thank you so much, Mixtral!
One More Thing...
Shortcuts can be run from the terminal. For example, running the following command will execute your Website Q&A shortcut:
shortcuts run "Webpage Q&A"
This means that you can run your Shortcut periodically at a scheduled time!
For example, imagine that you routinely visit several websites or blogs to catch up with the news every morning. You could automate that task by creating a Shortcut that opens the websites and uses your LLM to create a personalized newsletter that gets sent to you by email. Call it "Custom Newsletter".
Now you can use crontab -e to add a cron job that runs your Shortcut every day at 9 am like in the example below:
0 9 * * * shortcuts run "Custom Newsletter"
And that's it! Now you have your own automated newsletter written with an LLM totally locally and for free!
I hope you found this article useful. I'm sure that you will find many ways of improving your workflows.
Happy prompting!
*1:Also have in mind that you will need enough RAM depending on the size of the model you choose. Apple Silicon chips, such as M1 and M2, have great GPU capabilities as long as you can fit the whole LLM on it. On the opposite side, if you don't have enough available memory, inference will run completely on CPU and will be way slower.