今年の4月に新卒入社した、DSOC R&D Groupの橋本です。前回はこちらの記事で登場しました。
今回は、通常の変分推論よりも高精度に事後分布を近似するアルゴリズムの1つである、Stein Variational Gradient Descentについて説明します。まず一般的な変分推論について説明します。
変分推論 (Variational Inference)
変分推論は、真の事後分布に対しパラメトリックな確率分布を仮定して事後分布を近似する手法です。Jensenの不等式を用いることで、対数周辺尤度の下限である変分下限が導出できます。入力を、確率モデルのパラメータを
とすると、
として変分下限 が得られます。ここで
は確率モデルの同時分布、
は変分パラメータ
を有する近似事後分布を表します。さらに、対数周辺尤度
と変分下限
の差をとると、
となり、真の事後分布 と近似事後分布
の近さを表す尺度であるKLダイバージェンス (Kullback-Leibler divergence) が得られます。したがって、対数周辺尤度は変分下限とKLダイバージェンスの和になることがわかります。ここで直接KLダイバージェンスを最小化すれば真の事後分布を最もよく近似する近似事後分布が得られるのですが、KLダイバージェンスにおいて真の事後分布は厳密な計算が不可能なので、直接最小化することは非常に困難です。一方で変分下限は計算が容易な確率モデルの同時分布と近似事後分布から導出できます。さらに、対数周辺尤度は
のみに依存する量であるため、
および
を動かしてもKLダイバージェンスと変分下限の和は常に一定です。以上から、最もよい近似事後分布を得るには、KLダイバージェンスを最小化する代わりに変分下限を最大化すれば良いことがわかります。しかし、近似事後分布にはさらに因子分解可能であるという仮定 (平均場近似など)を課す必要があるため、得られる近似事後分布の表現力は必然的に大きく制限されることになります。
Stein Variational Gradient Descent (SVGD)
概要
SVGDは、再生核ヒルベルト空間上における汎関数微分による勾配降下によって、近似事後分布と真の事後分布とのKLダイバージェンスを最小化するアルゴリズムです。*1 初めに紹介した通常の変分推論と比較すると、SVGDは真の事後分布に対してパラメトリックな確率分布や因子分解を仮定する必要がないため、近似事後分布の表現力が大きく向上しています。 本手法をはじめとする、サンプル集合をKLダイバージェンスを最小化するように更新する変分推論は Particle-based Variational Inference と呼ばれ、近年その近似精度の高さや最適輸送との繋がりが注目されています。*2
Kernelized Stein Discrepancy
まず、再生核ヒルベルト空間上での汎関数微分に基づく勾配降下とKLダイバージェンス最小化をつなぐ、Stein DiscrepancyおよびKernelized Stein Discrepancyについて説明します。
を
における連続確率変数とすると、連続かつ微分可能な分布
について、以下の式が成り立つことが知られています。
ここで であり、
をStein identityと言います。一方で
と異なる連続かつ微分可能な分布
を考えると、
の場合には分布
で期待値をとってもゼロにはなりません。しかし、分布
との不一致の尺度として考えることができ、これをStein Discrepancyと呼びます。Stein Discrepancyは
として定義されます。ここで、 は 有界なLipschitz normをもつ関数の集合です。Eq. (9) は
において汎関数
が最大となるように
を選ぶことを意味しているのですが、
自体は小さいほうが近似事後分布
と真の事後分布
が近いためよい、ということに注意してください。Eq. (9) の変分問題を解くにあたり、滑らかな関数
をどのように選ぶかが、
やその計算コストに大きく影響します。しかし、
を十分に広くとるには無限個の基底関数を使用する必要があり、Stein discrepancyの変分問題を解くのは計算コスト上極めて非効率であることが知られています。*3
そこで、再生核ヒルベルト空間 において変分問題を解くことを考えます。
上における Stein Discrepancyである Kernelized Stein Discrepancy (KSD) は次の式で定義されます。*4
この場合変分問題の最適解を与える上の関数
が得られ、
となります。 にはRBF (radial basis function) カーネルのように、滑らかかつ正定値性を満たすカーネル関数が用いられます。
Kernelized Stein DiscrepancyとKLダイバージェンス
先ほど示したKSDと、変分推論において最小化されるKLダイバージェンスにどのような関係があるのでしょうか。微小数を とし、 恒等写像に摂動を与えた変換
を考えると、次の定理が成立します。
Theorem 3.1. [Q. Liu et.al., 2017]
、
である
において

が成り立つ。
証明は [Q. Liu et.al., 2017] のAppendixに書かれていますので、そちらを御覧ください。
Eq. (12)において、右辺はEq.(9) で最大化される量と同じであることがわかります。右辺を最大化する場合、先程と同様に再生核ヒルベルト空間を考えるとKSDになることがわかります。つまり、近似事後分布と真の事後分布のKLダイバージェンスを最も大きく減少させるようにサンプルの位置が更新され、その減少幅はKSDと一致するようになります。*5
SVGDのアルゴリズム
アルゴリズムとしては非常に簡単です。初期分布からサンプルを取得し、 に従ってサンプルの位置を更新するだけです。ただ、
は実際にはイテレーション
時点でのサンプルを用いた近似値
を使います。
Algorithm 1: Stein Variational Gradient Descent [Q. Liu et.al., 2017]
入力: イテレーション数
、初期分布
からの
個のサンプル集合

出力: 目的の分布を近似するサンプル集合
where
SVGDの実装と検証
簡単な例ではありますが、実際にSVGDを用いて初期分布からのサンプルを混合ガウス分布に近づけてみます。初期分布からのサンプルが実際に混合ガウス分布を構成するように動き、真の分布に近づくにつれてサンプルの位置の変化が小さくなっていくのがわかりますね。
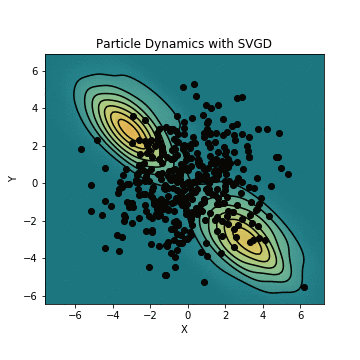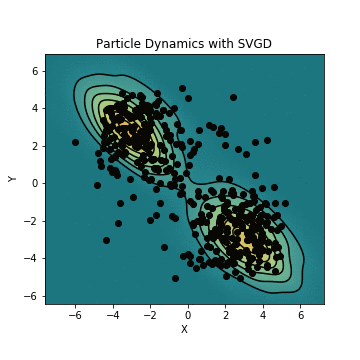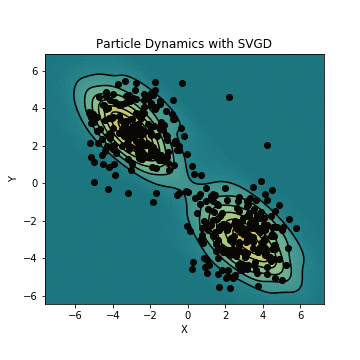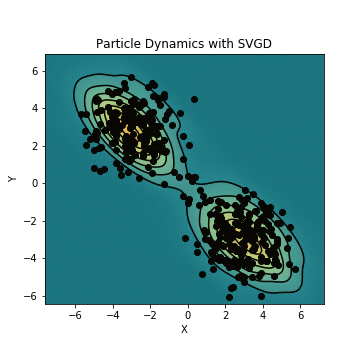
SVGDおよびそのアニメーションを生成するコードはこちらのリポジトリに置いていますので、興味がある方は御覧ください。
最後に
今回はSVGDという、再生核ヒルベルト空間上における汎関数微分に基づく勾配降下を用いた変分推論のアルゴリズムを紹介しました。ベイズ推論では一般的にMarkov Chain Monte Carlo (MCMC) と変分推論が使われるのですが、一般的にMCMCは理論的に真の事後分布が得られる一方で推論が遅く、一方で変分推論は近似精度はMCMCと比べると劣るのですが、高速に近似事後分布が得られるという特徴があります。実務の観点から言うと、近似精度が高くかつ高速に確率分布を推論する手法に興味があるため、MCMCをより高速にしたり変分推論の近似精度を向上させる試みについて、もっと調べてみたいですね。
1: Q. Liu, and D. Wang, "Stein Variational Gradient Descent: A General Purpose Bayesian Inference Algorithm", in NIPS, 2017. Stein Variational Gradient Descent: A General Purpose Bayesian Inference Algorithm
2: C. Liu, J. Zhuo, P. Cheng, R. Zhang, and J. Zhu, "Understanding and Accelerating Particle-Based Variational Inference", in ICML, 2019. Understanding and Accelerating Particle-Based Variational Inference
3: J. Gorham, and L. Mackey, "Measuring Sample Quality with Stein's Method", in NIPS, 2015. Measuring Sample Quality with Stein's Method
4: Q. Liu, J. D. Lee, and M. I. Jordan,"A Kernelized Stein Discrepancy for Goodness-of-fit Tests and Model Evaluation", in ICML, 2016.
5: こちらの短いノートのFigure 2に、KSDと他のダイバージェンスとの関連がまとめられています。http://www.cs.utexas.edu/~lqiang/PDF/ksd_short.pdf