こんにちは。研究開発部 Architectグループの中村です。
本記事は Sansan Advent Calendar 2023 の16日目の記事です。
今回は、私達のチームで開発&運用している全社横断データ分析基盤のデータレイヤの再設計、及びdbtの導入を進めているという事例について紹介します。
既存のデータ基盤に対して、dbtの導入を検討されている方の参考になれば幸いです。
(本稿ではdbtとはについては触れませんので、ご了承ください)
TL;DR
- 2021年からデータサイロの解消を目的として、全社横断のデータ基盤を開発中
- 立ち上げ期に量産したデータマートの依存関係が複雑であり、品質も担保出来ていない→拡大期の今、負債となりつつある
- データレイヤの再設計&dbt導入により、高速に高品質なデータモデルを作れるように試行錯誤中
歴史的経緯
本題の前に、Sansanの歴史とデータマネジメントの取り組みについて少し触れておきます。
全社横断データ基盤が生まれる前
Sansan(株)は2007年の創業以降、主にSansanとEightという2プロダクトを展開してきました。
データ基盤としては各プロダクトで独立した分析基盤があり、それぞれの基盤で独立してデータを分析していました。
また、それらに加え、研究開発部(企業データの収集&名寄せ、OCR技術などの研究開発を担当する部門)でのデータ基盤や営業担当者用データ基盤(各種CRMデータ)などが存在していました。
そして、2020年には新規事業のBill Oneの立ち上げ以降、マルチプロダクト体制へとシフトしていく中で、データ基盤の散在による課題が顕在化してきました。
(複数のデータ基盤で同じデータコピーが起きている。部門をまたいだ際のデータアクセスに制約がある。など)
そこで2021年上旬頃から全社横断のデータ基盤の構築プロジェクトが発足しました。
全社横断データ基盤 立ち上げ期
プロジェクトとして、まずは既存の基盤上にあるのデータのコピーを中央集権の全社横断データ基盤に集約するという事を目指していきました。
データ基盤の構成は以下のようになっています。
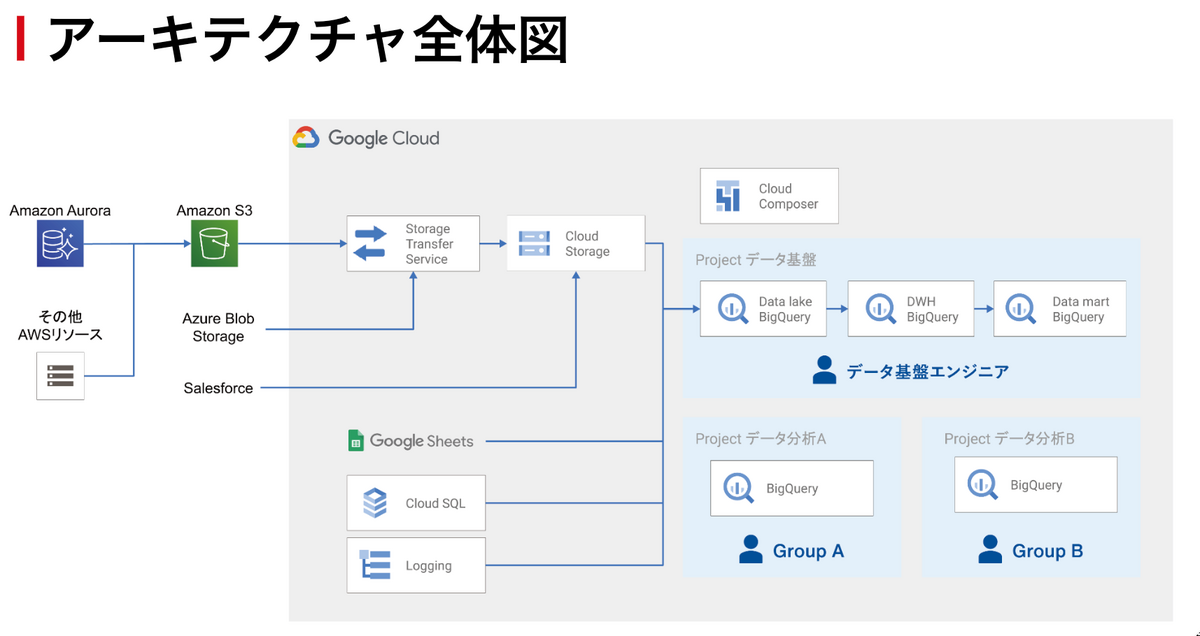
また、データガバナンス(アクセス制御)については、
①データセットごとにViewerアクセス可能なGoogleグループを紐づける
②承認システムを用いて利用者の部門長の承認を得ることで利用可能になる(個人単位での権限付与)
としています。
詳しくは過去の記事をご参照ください。
そして2023年中旬にはおおよそ主要なプロダクトのデータや&CRMのデータはデータレイクとして集約されました。
また、利用者のユースケースに応じてデータマートも提供し、各種定期レポーティング業務/分析/BI/MLバッチ処理などで参照されています。
(データボリュームとして、レイクは1200テーブル、マートは200テーブル、BigQueryストレージ容量は50TB程度でした。)
そして、ここからが本題です。
課題
現在、全社横断データ基盤は立ち上げ期を終え、利用拡大期に入っています。
拡大期の今、抱えている課題について説明します。
立ち上げ期に作られたデータマートがカオスに・・・
基盤立ち上げ期では、データマートの作成を利用者からの要望ベース(このSQLでテーブルを作ってください!)で行っていました。
そのため、最低限のクエリ整形やデータガバナンス(個人情報が削除されているか)の確認は行ったものの、データマートの仕様そのものや、複雑なSQL内のビジネスロジックの理解が十分に行われていない状態でのマート作成が多くなってしまいました。
結果として、
- 同じようなCTEが複数のSQLに出現
- データの依存関係の複雑化(別のマートを参照してしまっているマートの出現)によりリカバリ範囲の特定工数がかかる
- データマートでの品質担保が行えていない(そもそも正常の定義が出来ていない)
など、データ品質や運用面での課題が顕在化してきました。
基盤立ち上げ期は、試行錯誤しつつビジネス価値を出すことを最優先としていた時期でありましたが、今後の利用者の拡大を考えるとこの状態でデータ基盤やデータ活用を推進していくのは厳しいと考えました。
ちょうど2023年の上旬から私を含めデータエンジニアチームにメンバーが増えてきたことや、データ提供者&利用者との協働を進めることでチーム内にデータやビジネスドメイン知識が少しずつ蓄積され、各ドメインにおける共通指標が見えててきたこともあり、改めてデータモデル及びレイヤの整理に踏み切りました。
課題の解決に向けて
本セクションでは、課題解決のための「データレイヤの再設計」と「dbtの導入」について詳しく説明します。
データレイヤの再設計
既存のデータレイヤとしてはレイク→マートと単純な2層の構造としていましたが、再設計後は以下のように4層構造としました。
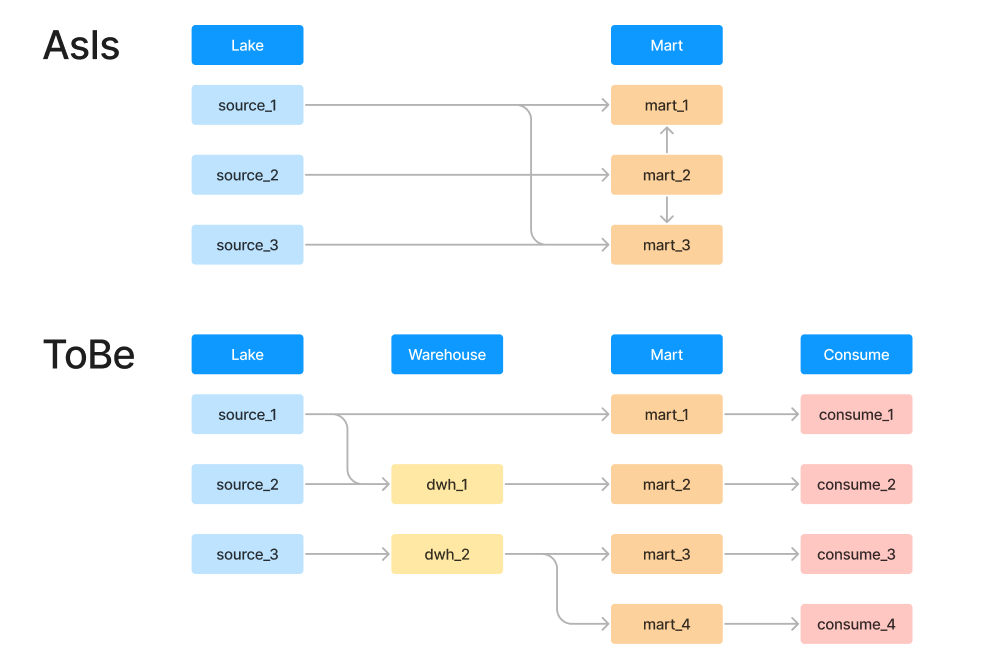
- Lake
- 各種データソースからの生データを格納するレイヤ
- Warehouse
- データ型や物理名を正規化した上で共通指標を集約し、再利用可能なデータを格納するレイヤ
- viewやephemeralモデルを活用し、無駄のないデータレイヤを目指す
- Mart
- 特定のユースケースに応じて加工済みのデータを格納するレイヤ
- はじめは既存のモデルをすべてこのレイヤに格納し、徐々にWarehouseに分割&整備していく
- Consume
- ユーザが直接参照するレイヤ
- 原則Tableで提供
- Martのモデルを直接参照する
- 部門(≒ユースケース)毎にデータセットを分離しアクセス制御を行う
Consumeレイヤを分離する理由としては、
- 開発側の関心事を権限のみに絞る
- Consumeレイヤ内でのデータの再利用を防ぎ、リネージの複雑性を抑える
ことを目的としています。
Transformツールの選定
この4層構造のデータレイヤに分割し、中間のモデルを量産していくことになりますが、依存関係を考慮してモデルを更新する必要があります。
そこで、Transformツールの比較検討をし、最終的に既存のCloud Composer上で動かすdbt(OSS)を導入することにしました。
Transformツールの導入候補としては他にもDataformやdbt Cloudもあるかと思います。
それぞれについての導入しなかった理由としては以下の通りです。
Dataformを導入しなかった理由
- dbtと比較して、導入事例も多くないため情報収集がし辛い
- GCPのデータ系サービスとの親和性は高いが、他のOSSのツールとの組み合わせがしづらい
(とはいえ、今後Duet AI連携などの機能がより充実していくと考えられるため、今後の動向に注目しています。)
dbt Cloudを導入しなかった理由
- dbt(OSS)ならGCP内で完結するため、データが外部に出ることがない
- 機密情報が含まれるデータを扱う場合もあるため安全に倒しました
- 既にCloud Composerというジョブ実行環境があったため、dbt(OSS)でも環境構築の手間は少ない&ジョブ管理とELTの責務が閉じる
dbtへの移行戦略
前述の通り、Consumeレイヤではユースケース毎にデータセットを分けています。
ユーザが参照するテーブルであるため、直感的で分かりやすいテーブル名にしたいのですが、dbtでは${モデル名}=${テーブル名}であり、さらにモデル名は一意である必要があります。
これを回避するため、generate_schema_name及びgenerate_alias_nameマクロをオーバーライドし、${モデル名}=${データセット名}___${テーブル名}となるようにしました。
そうすることでテーブル名としてはシンプルにしつつ、モデル名の一意性を担保しています。
既存View/Tableのdbtへの移行戦略としては単純コピー→並行稼働→リプレイス という方針で進めています。
ただし、単純コピーの際には最低限、以下のルールに則るようにしています。(カラム名や型の標準化は既存の利用者へも影響が出るため一旦保留としています。)
- 解読できる範囲でコメントを残す
- 統一的なSQLフォーマットルールを作成し、それに従う
- 予約語は小文字、可読性を上げるためサブクエリはなるべくCTEに変換する など
- (並行稼働→リプレースとするため)モデル名のsuffixに
_dbtをつける - 既存のデータチェック処理があれば、dbtでもtestを行う
そしてブログ執筆中の今、絶賛移行中です。
その他dbt移行におけるTips
チームでの開発の標準化
データエンジニアチームは現在全5名で、基本的にはVSCode上で開発しています。 dbtのモデル開発時には以下のツールを利用&モブプロでナレッジトランスファーすることにより、開発生産性を高めています。
個人的にはこの1-2年でこのあたりのツールが揃ってきたおかげで、dbtの開発が非常にやりやすくなったと感じています。
(その分、データの探索と理解に時間を割くことがより重要になっている気がします。)
Cosmosの導入検証
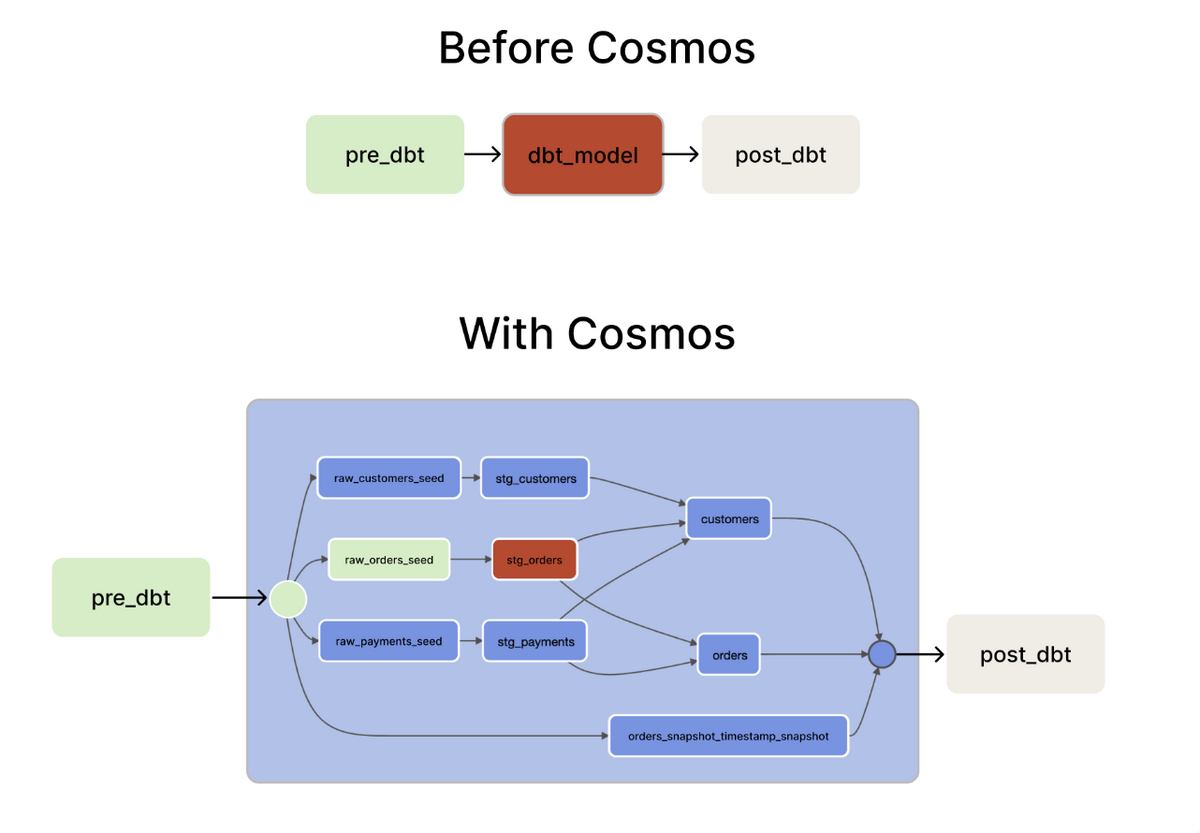
dbtをCloud Composer上で実行する際の障壁となるのが、途中のモデルの更新が失敗した際に、最上流のモデルから実行し直す必要があるということです。
そこで、途中のモデルからの再実行が可能となるようにCosmosの導入を検討しました。(検証時点で利用しているバージョンはv1.2.0です。)
Cosmosについては、以下の記事が参考になります。
zenn.dev engineering.linecorp.com
導入するメリットとしては、上に挙げた記事にもあるように 、
- DAGを解析し、モデル単位で
dbt runを行うTaskが自動生成されるため、リカバリ時などで途中のモデル更新Taskからのリランが容易 - 各モデル更新後に対象モデルへの
dbt testが行えるため、上流モデルでのデータ異常検知時にパイプラインを止められる
ことが挙げられます。
(AirflowUIでモデルごとの更新される様子が見ていて気持ち良い というのもあります。)
ただ、検証していく中で以下のような課題があったことから、導入を(一時的に)断念しました。
- DAG実行時のワーカーが思うようにスケールせず、Taskがキューに溜まったまま捌けない
- モデル単位でTaskが作られるのですが、Taskの実行時間以上にキューイングの時間がかかりました。こちらについてはCloud Composer側の設定を色々試したものの解決しませんでした。
- 個々のTask名がモデルのalias(=テーブル名)で生成される
- 1DAGで同じaliasのモデルを更新する場合があったためTask名重複によるエラーが起きる
- ただし、こちらについてはv1.2.5で解消済みのようです。
そのため、現在はBashOperatorで直接cliとしてdbtコマンドを叩く(全体run→全体test)という形を取っています。
データカタログのホスティング
dbtの強みの1つであるデータカタログ機能ですが、社内のユーザが閲覧できるように、以下の記事を参考にGoogle App Engineでホスティングする仕組みを構築しました。
記載するメタデータについては、既存のドキュメント資産があるため、そちらへのリンクを貼るなどしていますが、最終的にはどちらかに寄せられるようにしたいと考えています。
まとめ
今回は全社横断データ基盤の歴史とdbt導入を進めている事例についてご紹介いたしました。
基本的な仕組みは出来たものの、これからモデルを共通パーツに分解してテストを入れて...とやるべきことはまだまだあります。
そのためには、よりプロダクト/ビジネスサイドとの連携を強めて、ナレッジや要望をデータ基盤に還元し続けていく活動が重要です。
また、長期的なビジョンとしては、
- データマート作成の委譲
- データ基盤のユーザ(アナリスト/研究員...)がデータマートのモデル開発をしてデータエンジニアがレビューできる仕組み/体制作り
- 既存のデータ分析基盤上の加工パイプラインの集約または責務の明確化 *既存のデータ基盤から加工済みのデータをコピーしている箇所があり、さらにそれぞれの責任分界(どの処理をどこで行うか)を明示的に決めていないため、それらの加工処理を全社横断データ基盤に集約するか、責務を明確にする
を目指しています。
私たちのチームではデータエンジニアおよびアナリティクスエンジニアを募集しています。データエンジニアリングからデータマネジメントまで一気通貫で体験できます。
研究開発部門 データエンジニア [全社横断データ分析基盤] / Sansan株式会社.
研究開発部門 アナリティクスエンジニア[全社横断データ分析基盤] / Sansan株式会社