
研究開発部 Architectグループにてデータエンジニアとしてデータ基盤の開発・運用を担当しているジャン(a.k.a jc)です。 データ基盤の構築はETL処理の実装やパイプラインの監視だけでなく、セキュリティ、データアクセス制御管理もデータエンジニアリングライフサイクルの一環として、重要な存在になっています*1。データ基盤の第四弾となる今回は、BigQuery上に構築したデータ基盤におけるGoogleグループ・IAMによるアクセス制御を中心に紹介したいと思います。
また、過去のデータ基盤関連の記事も併せてお読みいただければと思います。
- 【R&D DevOps通信】データ基盤におけるGitHub Actionsを使ったTerraformとCloud ComposerのCI/CD - Sansan Tech Blog
- 【R&D DevOps通信】Cloud Composerを用いたデータ基盤の転送パイプライン構築 - Sansan Tech Blog
- 【R&D DevOps通信】Cloud ComposerのDAGでデータ基盤の転送パイプラインを監視 - Sansan Tech Blog
Googleグループによるアクセス制御
Googleグループはメーリングリストでメール送信、会議への招待やGoogleドライブ特定のファイル・フォルダーのアクセス制御などの場面ではよく利用されています。 データ基盤のアクセス制御にも役立ちます。
個人単位で必要とするデータセットが異なるため、部署単位でグループを作ることが現実的ではありません。 図に示しているように、グループとBigQueryデータセットを1対1で対応させ、アクセス予定のデータセットに対応しているグループにデータ利用者を追加すると、データセットにアクセス・クエリ実行ができるようになります。(メタデータは全員確認できます)
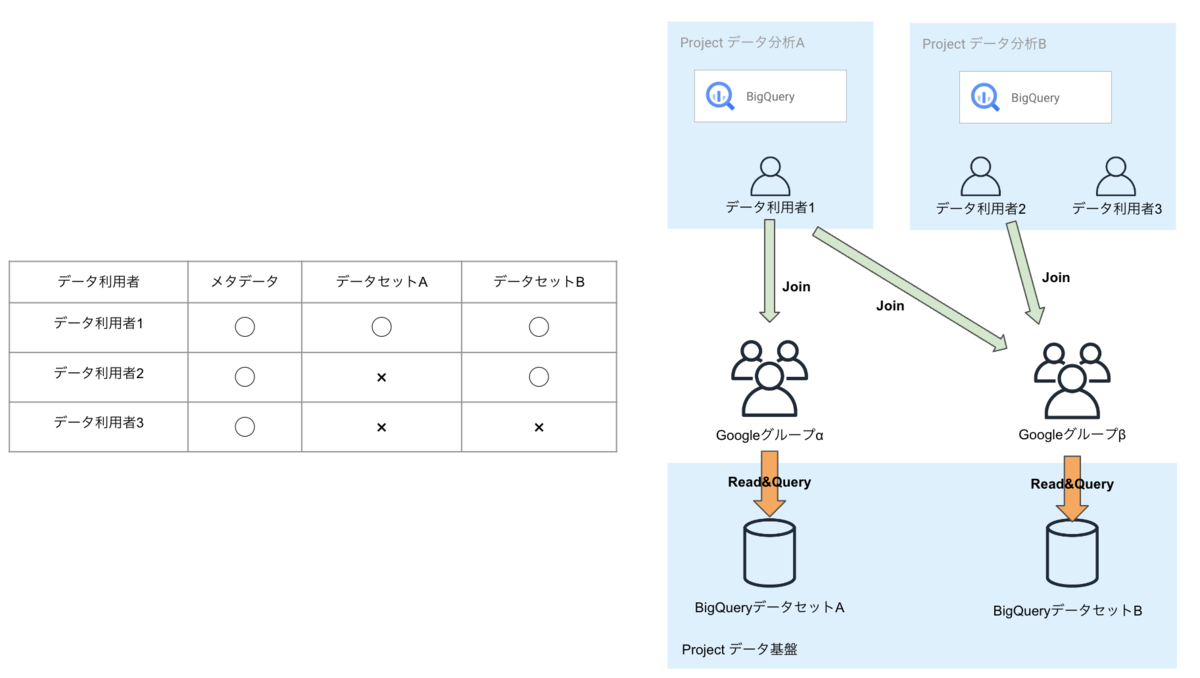
つまり、権限は利用者ではなくグループに付与します。Googleグループに当該するデータセットにロールBigQuery Viewerをデータセットレベルでアタッチすると、データセットにアクセスできるようになります。また、クエリ実行はBigQuery Job Userが必要で、BigQueryのSDKを利用してクエリ結果の取得はさらにBigQuery Read Session UserとService Usage Consumerを追加する必要があります。
データ分析プロジェクトを分離する理由としては
- コスト面:GCP費用の社内精算において部署ごとに明確にする必要があり、プロジェクトを分離することでBigQueryクエリ料金の負担額を算出しやすいため
- BQのパフォーマンス面:定額料金(BigQuery Reservation)においてプロジェクトごとにスロットを割り当てることで、データ基盤へのクエリジョブを保護するため
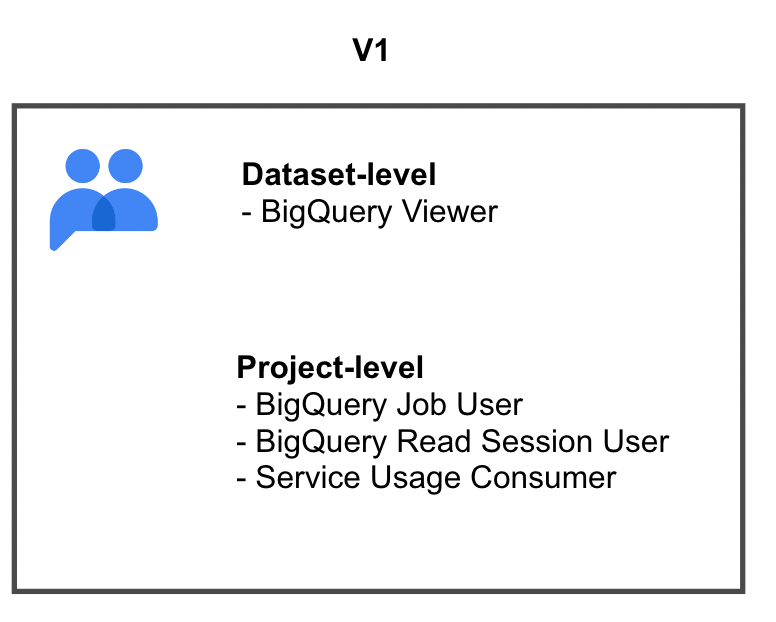
利用者に権限を付与せず、抽象的なグループに権限を付与するメリットをまとめてみましょう。
- グループに権限を付与すると複数利用者を一括で管理できる
- 入社、異動や退職に伴い、利用者に個別でIAM権限を付与・剥奪する必要がなくなり、グループに追加・削除だけで済む
- メンバーシップ有効期限*2を利用すると時間制限を設け自動的にGoogleグループから削除できるため、時間制限付きのアクセス制御は簡単に実装できる
先日のGoogle Cloud Next’22「データ活用から管理までを知るエキスパートが語る BigQuery 使いこなしの秘訣 〜初入門の方法からこれからのデータ基盤運用まで〜 」でも熱く議論されたほど、Googleグループによるアクセス制御はもはやデータ基盤のベストプラクティスになりつつあります。 ただし、弊社のアクセス制御の要件がやや複雑のため、実際にアクセス制御を設計・実装する際に課題が見つかりました。
課題
必要とする権限は個人単位で異なるため、利用者によって異なる権限(例えばViewer, Analyst, Editor)を付与したい場合はひたすらグループを作成する必要があります。 例えばデータ基盤内に10個データセットが格納されており、それぞれのデータセットにViewer, Analyst, Editor3種類のロールを分けたいという要件があると仮定しましょう。少なくとも10*3個(デカルト積)のGoogleグループを作る必要があります。グループ作成するのはともかく管理がややこしくなり、DRY (Don't Repeat Yourself)という思想に程遠いです。
解決法
我々が考えた解決法としては、カスタムロールを作成し(↓に参照)、データセットレベルとプロジェクトレベルのIAM権限を分けて、GoogleグループにアタッチしているロールはCustomer Viewerのみ、 利用者にロールBigQuery Job Userを直接アタッチしています。必要であれば、利用者にロールCustomer Analyst, Customer Editorをアタッチします。
- Customer Viewer
- bigquery.datasets.get
- bigquery.tables.get
- bigquery.tables.getData
- bigquery.tables.list
- Customer Analyst
- bigquery.tables.createSnapshot
- bigquery.tables.export
- bigquery.readsessions.create
- bigquery.readsessions.getData
- bigquery.readsessions.update
- resourcemanager.projects.get
- serviceusage.services.get
- serviceusage.services.list
- serviceusage.services.use
- serviceusage.quotas.get
- Customer Editor
- bigquery.tables.create
- bigquery.tables.createIndex
- bigquery.tables.update
- bigquery.tables.updateData
- bigquery.tables.updateTag
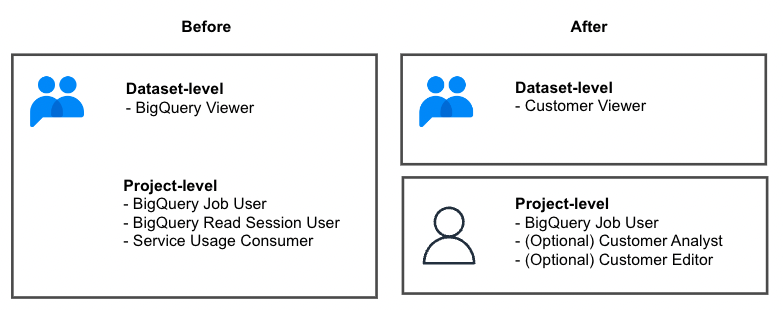
ご注目していただきたいのはロールCustomer Viewer, Customer Analyst, Customer Editorは包含関係ではなく、それぞれ独立しているため、閲覧者、分析者、編集者になるのに必要なロールは以下となります。
- 閲覧者(データ閲覧・クエリ実行):Customer Viewer, BigQuery Job User
- 分析者(閲覧者の権限 + データのエクスポート):Customer Viewer, Customer Analyst, BigQuery Job User
- 編集者(分析者の権限 + テーブル・ビューの作成):Customer Viewer, Customer Analyst, Customer Editor, BigQuery Job User
ベースとなるロールCustomer Viewerがなければ、他のロールがアタッチされていてもBigQueryにアクセスできません。 その結果、Googleグループによるアクセスを制御するメリットを得ながら、利用者によって異なる権限を付与することが可能になります。
おわりに
- Googleグループを用いるとデータ基盤のアクセス制御するのは多数のメリットがあります。
- しかし、利用者によって異なる権限を付与したい場合、大量なグループを作成する必要があるという課題が残っています。
- データセットレベルの権限(Viewer)をグループに、プロジェクトレベル権限を利用者に付与することでこの課題を解決できます。
ご参考になれば幸いです。 実装の話はまだ触れていないので、次回の記事にご期待ください。
弊社研究開発部Architectグループでは一緒に働く仲間を募集しています。
*1:Joe Reis & Matt Housley, Fundamentals of Data Engineering
*2:https://cloud.google.com/identity/docs/how-to/manage-expirations