研究開発部 Architect Groupの大澤秀一です。ブログ寄稿は約2年ぶりです。半年ぐらい前からランニングを始めて、先日フルマラソン完走してきました。おかげで足はボロボロです(笑)。
さて、私たちはBigQueryを中心とした、全社横断データ基盤(以下、データ基盤)の構築とデータ基盤をもとに社内のデータ利活用を推進しています。データ利活用の推進についてチームメンバーが最近登壇した資料をご参照ください。
データ基盤を拡大していくにあたって、社内の利用者から自部門のデータをアップロードしてデータ基盤上でアドホックに分析したいという要望がありました。また、利用者自身が自由にテーブルとビューを作りたいという声があがりました。
今回は、そうしたことができる環境を構築したので仕組みについてご紹介します。
なお、本記事はSansan Advent Calendar 2023の8日目の記事です。
実現するまでに解決しなければならないこと
利用者が自由にデータ基盤上にデータをアップロードしたり、テーブル・ビューを作成するためにクリアしなければならない課題がいくつかありました。
1. データガバナンスの維持
データガバナンスの観点から、データ基盤を運用している私たちのチーム(以下、Data Direction Team)がデータ基盤を管理・運用しています。そのため、利用者はデータ基盤に対してデータアップロードやテーブル・ビュー作成などの変更を加えることはできず、Data Direction Teamに依頼する流れとなります。
しかし、データ基盤として永続的なリソースを管理したいと思う一方で、利用者はアドホックかつ気軽にデータを自分たちのペースで使いたいため、データライフサイクルや管理方法が異なります。利用者にデータ基盤への編集権限を付与すると、データ基盤チームによって管理していたリソースに影響を与え、ガバナンスの崩壊が懸念されます。また、利用者によって作成したテーブル・ビューが常態化するとサイロ化が発生する可能性もでてきます。
2. 機密データの取り扱い・アクセス制御
データ基盤ではGoogleグループによってデータセット単位でアクセス制御しており、Slackアプリで申請および承認できる仕組みを提供しています。詳しくは過去の記事をご参照ください。
こうした仕組みをもとにデータ基盤では機密データを含めていますが、利用者が機密データをアップロードしたときにそのリスクヘッジを取れるのかが論点になります。また、「全社横断」データ基盤であるため、部門をまたがるデータ利用が想定されます。インシデントが発生したときにどの部署が責任を持つのか、ガイドラインを策定して利用部門と合意する必要があります。
3. コスト
当社はGCPプロジェクト単位で費用負担する部門が決められており、1つの基盤でデータが混在すると部門単位に按分する必要が出てくるため、コスト管理が面倒になります。
システム構成
上記のような課題に対してどのような仕組みを構築したのかについて説明します。次の図は全体の構成図です。
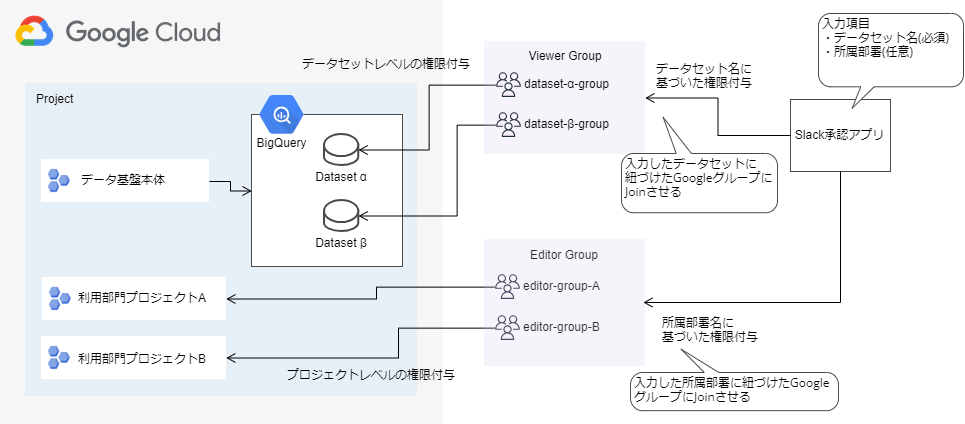
データ基盤上のデータアクセス
Slackアプリで利用したいデータセットを選択して承認されると、データセットが紐づいたGoogleグループにジョインされ、データアクセスできます。この箇所については以前のブログで解説しているのでご参照ください。
【R&D DevOps通信】データ基盤におけるGoogleグループ・IAMによるアクセス制御 - Sansan Tech Blog
利用部門用のGCPプロジェクト
データ基盤構築の初期段階から、データ基盤を利用する部門ごとに作成したGCPプロジェクト(以下、部門用プロジェクト)があります。データ基盤本体と部門用プロジェクトを分けた理由は次の2点です。
- BigQueryのスロットを利用部門ごとに割り当てできる
- コスト按分が容易になる
今回の構成では、部門用プロジェクトにデータアップロードおよびテーブル・ビュー作成ができる権限を付与することで、データ基盤本体に影響を及ぼさない形でデータ利用できるようにしました。
具体的には次の2点を行いました。それぞれ説明していきます。
- 部門用プロジェクトに対して編集権限の付与
- BigQueryデータセット、GCSバケットの作成
編集権限の付与
利用部門プロジェクトに対して編集権限を付与したGoogleグループ(以下、Editorグループ)を作成し、部門に所属する社員をEditorグループにジョインさせます。ジョインさせる仕組みはSlackアプリの承認システムを拡張し、Slackでの申請時にEditorグループを選択できるようにしています。
Editorグループに所属した社員は、利用部門プロジェクト内でテーブル・ビューの作成・削除およびGCSオブジェクトの作成・削除ができるようになります。これらの作成・削除は付与せず、あらかじめ作成したものを利用してもらいます。データセットとバケットについては後述します。
GCPのデフォルトで提供されているロールではデータセットとバケットの作成・削除ができてしまうため、カスタムロールを作成しました。
BigQueryデータセット、GCSバケットの作成
利用部門プロジェクトで次のデータセットとバケットを作成しています。
- 機密データを扱える
- BigQueryデータセット: defaultTableExpirationMs を90日に設定
- GCSバケット: ライフサイクルで90日後に削除
- 機密情報を扱わない
- BigQueryデータセット: defaultTableExpirationMs を365日に設定
- GCSバケット: ライフサイクルで365日後に削除
今回の仕組みはあくまで一時的な利用として位置づけし、保持期間を定めることでデータやテーブル・ビューが常態化するのを防ぎます。
責任境界について
データ基盤本体はData Direction Teamが管轄となり、利用部門プロジェクトは各部門が管轄となります。したがって問題が発生した箇所によって、責任を持つ部門が異なります。機密データについては全社で定期的に実施する棚卸し作業があり、各部門は利用部門プロジェクト内にあるデータリソースをチェックしてもらいます。Data Direction Teamで開発しているリソース棚卸しツールがあるので必要に応じて導入してもらいます。
権限の境界については、先ほど書いたように本構成は一時的な利用であるため、BigQueryのスケジューリングクエリやDataformなどのETL処理もできないようにしています。長期的な利用およびデータ連携、ETL処理が必要となった場合は、Data Direction Teamに依頼して対応します。
また、サービスアカウントやIAM権限の拡張についてもData Direction Teamに相談して必要に応じて対応する流れとなります。
まとめ
本記事では、BigQueryを中心としたデータ基盤において、利用者がデータアップロードしたりテーブル・ビュー作成できる仕組みについてご紹介しました。
当社のPremiseである「セキュリティと利便性を両立させる」が根底にあり、社内のデータ利活用を推進する活動を日々行っております。
私たちのチームではデータエンジニアおよびアナリティクスエンジニアを募集しています。データエンジニアリングからデータマネジメントまで一気通貫で体験できます。