こんにちは。DSOC 研究開発部の鈴木碩人です。21卒で今年の4月にSansanに入社しました。
今回は11/5に開催された「Sansan Builders Stage 2021」に参加したのでその中の、私も所属する研究開発部から、高橋が発表した「継続して改善する固有表現抽出」と齋藤が発表した「Eightにおけるニュース配信の取り組み」をピックアップして紹介したいと思います!
継続して改善する固有表現抽出

研究開発部の高橋が「継続して改善する固有表現抽出」と題して登壇しました。
私も一個人として視聴しましたが、 最初タイトルを見た時に固有表現抽出がメインの発表なのかと思いきや継続して改善するがメインテーマでした!「継続して改善する=初期の作成者以外も改善に関わることが可能である状態」と定義されており、機械学習プロジェクトをメンテナンスしやすくする仕組みづくりについて解説しています!
発表の流れとしては、
- 前半:固有表現抽出とは何か・どうサービス利用しているか
- 後半:固有表現抽出タスクを具体例として、機械学習プロジェクトの運用・改善のサイクルを速くするための工夫
となっています。
固有表現抽出そのものに興味のある方は下記の記事をご参照ください。
- 実務で使う固有表現抽出 / Practical Use of Named Entity Recognition - Speaker Deck
- 【Techの道も一歩から】第26回「BERTで日本語固有表現抽出器を作ってみた」 - Sansan Builders Blog
- 【Techの道も一歩から】第27回「BERTで作ってみた日本語固有表現抽出器の推論部分を書く」 - Sansan Builders Blog
- BERTによる日本語固有表現抽出の精度改善 〜BERT-CRFの紹介〜 - Sansan Builders Blog
本記事では後半部分について重点的に紹介していきたいと思います。
チームとして機械学習プロジェクトを効率よく改善・運用するためにはどうすればいいのか、高橋は以下3つの工夫を紹介しています。
- 学習データを効率良く作るための工夫
- 試行錯誤を行いやすくする工夫
- フィードバックをもらいやすくする工夫
1. 学習データを効率良く作るための工夫
機械学習プロジェクトにおいてしばしば律速段階となる学習データ作成フェーズ。これを効率化するために3つの工夫を実践しているそうです。
- アノテーションガイドラインの作成
スプレッドシートにアノテーション例とそのようにアノテーションした理由などをまとめておきます。これによりアノテーターごとの正解の揺らぎが少なくなります。面倒臭くてもドキュメント書くのは大事ですよね。
- モデルで推論 -> 人手で修正
モデルの精度がある程度信頼できるようになってきたら使える技。1から人手でアノテーションするよりもずっと楽そうです。
- 能動学習
モデルが効率良く学習できるデータを能動学習と呼ばれるアルゴリズムを使って選定します。アノテーターさんに依頼すると時間もお金もかかるので、アノテーションに必要なデータ量が少なくなると嬉しいですよね。 詳細はこちらの論文をご参照ください。
2. 試行錯誤を行いやすくする工夫
モデルの学習・パラメータチューニング・前後処理などを変更しやすくすることで試行錯誤の速度を上げています。 具体的には
- コードのディレクトリ構成を統一する
- モデルの記述を統一する
- 前後処理はファクトリーパターンにするなどして、後から処理の追加・削除をしやすい設計にする
などです。
3. フィードバックをもらいやすくする工夫
実際に利用してもらうことでモデルの改善点が見えてきます。たくさん使ってもらい、たくさんフィードバックをもらうための工夫について解説しています。 具体的には、
- pythonパッケージにしておくことで他プロジェクトに導入しやすくする
- SageMakerでAPI化し, AWS SDKから利用できるようにする
- 推論結果をサンプリングし、推論が正しいか人手でクオリティーチェックをするような性能観測体制を整える
などです。
以上、「継続して改善する固有表現抽出」のレポートでした。
発表で明示されていたわけではないのですが、そもそもの課題感は機械学習プロジェクトの属人化ではないかと推察します。最初にモデルを学習・実装した人は全てをわかっていても、他の人から見るとデータセットの作成基準が不透明、モデル開発の実験環境が独創的すぎてコードレビューしずらい、最初の設計者の力量によっては後々のコードの拡張性が低いなどなど、継続的な改善がやりにくくなる落とし穴が多数存在します。チームとして機械学習プロジェクトを効率よく改善・運用するための工夫が詳細にまとまっていて、とても勉強になりました。
Eightにおけるニュース配信の取り組み

研究開発部の齋藤が「Eightにおけるニュース配信の取り組み」と題して登壇しました。
Sansan株式会社は、法人向けクラウド名刺管理サービス「Sansan」だけではなく、名刺アプリ「Eight」などを提供しています。本発表はEight内でユーザーにビジネスニュースを配信するためのアルゴリズムについて解説しています。
Eightはご存知ない方はこちらのサービス詳細をご覧ください。
Eight - 名刺でつながる、ビジネスのためのSNS
発表の流れは
- ニュース配信のモチベーション
- ニュース配信のアルゴリズム
- ニュース候補の抽出と選別
- ジャンル判定
- プレスリリース判定
- 必要記事判定
- 重複記事判定
- ユーザーごとのパーソナライズ
- ニュース候補の抽出と選別
となっています。「適切な」ニュースを配信するために様々な工夫が必要なんですね。以下一つずつ紹介していきます。
ニュース配信のモチベーション
「Eightが配信したいニュース」かつ「ユーザーが見たいニュース」の両方を満たすニュースを配信する必要があります。
EightはニュースアプリではなくビジネスSNSを目指しているので、「ユーザーが見たいニュース」であってもおもしろニュースやエンタメ系のニュースを配信するわけにはいきません。ビジネスに関係するニュースを選別する必要があります。
ニュース配信のアルゴリズム
ジャンル判定
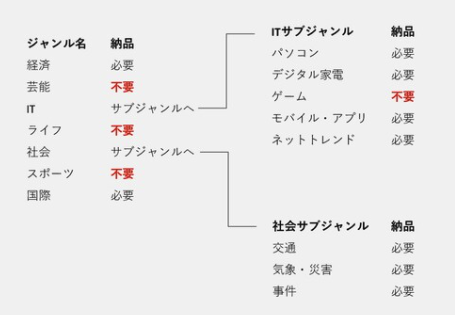
様々なジャンルのニュースが納品される中でビジネスに関係するニュースを選別します。
特定のジャンルについてはもう一段階分類モデルを適用することでビジネスに関係するジャンルだけを抽出できるように工夫しています。
プレスリリース判定
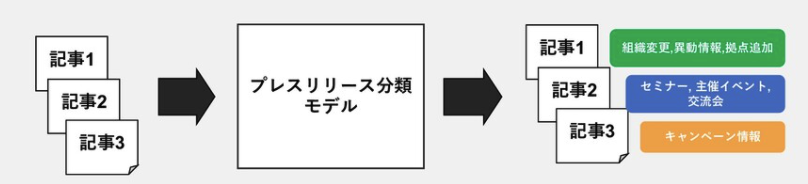
ニュース候補になりそうなプレスリリースを選別します。ジャンル判定と同様ですね。
ただこちらはジャンル判定よりも配信する・しないの線引きが難しそうです。例えば組織変更情報への敏感さは業界やユーザーによって異なる可能性が高いですよね?
必要記事判定
 ジャンル判定・プレスリリース判定ですでにニュースを選別しているのですが、よりEightに適したニュースのみを配信するために、自社で作成した基準で記事をアノテーションし、学習した分類器を用いているようです。
ジャンル判定・プレスリリース判定ですでにニュースを選別しているのですが、よりEightに適したニュースのみを配信するために、自社で作成した基準で記事をアノテーションし、学習した分類器を用いているようです。
重複記事判定
似ているニュースを配信しないようにするための判定モデルです。文書の類似度はJaccard係数による単語の一致度を用いているようです。
パーソナライズ

ユーザーが過去に閲覧したニュースと似ているニュースを配信するアルゴリズムです。 特定の企業や技術に興味を持っている方に特化した配信ができるようになります。
以上「Eightにおけるニュース配信の取り組み」のレポートでした。
「ニュースを配信する」という1機能に対してここまで多くの工夫が存在することに驚きました。クオリティチェックを何重にも行う仕組みはSansanらしいですね。また「ビジネスに関係するニュース」という定義不明な要望を現実的な機械学習タスクに落とし込むノウハウもとても勉強になりました。
この後も本ブログでは同じ21卒メンバーによるセッションレポートを公開しますので、そちらもお楽しみに!