こんにちは、DSOC R&Dグループ インターンの笛木正雄です。大学院では離散最適化の研究室に所属しています。インターンでは、日々、知らないことだらけで、色々なことを経験させていただき、伸びしろを実感する毎日です。
現在は、SansanやEightのニュース配信に使用されている固有表現抽出(文章中から組織名を抽出するために使用)と呼ばれる自然言語処理タスクに携わっています。今回は、これまで取り組んだ固有表現抽出における精度改善の手法を紹介したいと思います。ありがたいことに、この手法は現在、プロダクトで実際に稼働しているため、思い入れのある手法です。
また、今回の手法を含め、日本語固有表現抽出については、コード公開を予定しており、pipでインストールできるように現在進行中です。ご興味ある方は、お待ちいただき、合わせてご覧いただければ幸いです。
※弊社のニュース配信における固有表現抽出タスクの取り組みについて詳しくは以下のスライドをご覧ください。
目次
固有表現抽出(NER)とは
固有表現抽出(Named Entity Recognition: NER)とは、テキストから固有表現(人名、組織名、etc...)を抽出してくるタスクのことです。固有表現以外の単語には、O(その他)が付与されます。 例えば、以下のような単語を抽出することができます。
- 人名
- 寺田親弘
- 常樂諭
- etc...
- 組織名
- Sansan株式会社
- etc...
固有表現抽出の簡単な流れは、以下の図をご覧ください。

上記の3.に機械学習モデルが使用されています。 固有表現抽出は、機械学習タスクとして考えると、単語の系列(San / san / 株式会社 / は / ...)のそれぞれの単語(token)にラベルを割り当てるタスクのため、大きくtoken classification taskとも呼ばれます。token classification taskには、他にも文章中の単語の品詞を当てるタスク等が存在しています。
BERTを用いた固有表現抽出
BERTを使用した一番ナイーブだと思われる固有表現抽出モデル(BERT-Tagger)を紹介します。 BERT-Taggerを簡単に説明すると、BERTで得られたベクトルをほぼそのまま分類器に入力しているモデルです。
- 固有表現を抽出したい文章を分かち書きをして、単語の系列にする
- 単語の系列をBERTに入力し、単語の特徴量ベクトルの系列に変換する
- 各単語の特徴量ベクトルをラベル次元のベクトルに変換する
- 各単語について、ラベル次元のベクトルをSoftmax変換し、ラベルの帰属確率に変換する
- 各単語について、ラベルの帰属確率が一番高いラベルを割り当てる
※ 細かい処理については省略しています。
こちらのモデルは、以下で使用できます。 huggingface.co
BERT-Taggerの問題点
BERT-Taggerは、単語それぞれを独立してラベル判定するため、「『B-組織名』の後には『I-製品名』は来てはいけない(『B-組織名』→『I-製品名』という遷移は起こらない)」ということを考慮することを苦手としています*1。この問題は、以下のような出力時に深刻化します。

後処理で、I-製品名の部分をI-組織名に置き換えることも考えられますが、異なる出力パターンにおいて後処理を考える必要があり、後処理のルールが複雑化してしまう可能性があります。
このように、アノテーションルールが守られていない出力が得られてしまうと、最終的な固有表現を出力するという本来の目的を達成することが困難になってしまいます。
そこで、アノテーションルールが守られている出力を得る(正しいラベル遷移が出力される)ために、BERT-CRFは、BERT-Taggerにラベルの遷移を学習するパラメータを加えたモデルになっています。
BERT-CRF
スコア関数
BERT-CRFでは、BERT-Taggerで出力される値をスコア関数に入力し、正解のラベル系列が高いスコアになるように学習します。
以下が今回使用したスコア関数です[1]。
: 系列長
: token系列
: ラベル系列
上記は、あるtoken系列とあるラベル系列
が与えられた時のスコアを計算する数式になっています。
例えば、スコア関数は、
= {Sansan, 株式会社, は, Eight, を, 運営, する}
{B-組織名, I-組織名, O, B-製品名, O, O, O}
{O, O, O, O, O, O, O}
を入力して、以下のようなスコアが与えられる関数です。
BERT-CRFでは、1.のように、正解のラベル系列の時はスコアが高く、2.のように、正解とは離れている系列の時にはスコアが低く出力するように、
と
を学習します。
と
は、それぞれ遷移と出力を表す行列です。
は、
番目のtokenのラベルから、
番目のtokenのラベルに遷移する起こりやすさを表しています。例えば、「『B-組織名』→『I-組織名』は起こりやすい。」を定量化しています。
は、
番目のtokenをラベル
と出力する確率(のようなもの)を表しています。具体的には、BERT-Taggerの出力を使用します。
BERT-CRF
BERT-CRFは、以下の数式で表すことができます[1]。
: ラベル系列の集合
- 系列長とラベル数の重複順列分だけ要素が存在
上記からわかる通り、の要素数は膨大な数になりうるため、
を最大化するラベル系列
を求めるのは計算量的に困難ですが、ビタビアルゴリズム(動的計画法)を用いることで、効率的に求めることができます。
BERT-CRFの初期パラメータの設定について
上述でもあるとおり、BERT-CRFでは、ラベルの遷移確率に該当する学習パラメータがあるため、初めから遷移しないことがわかっているパラメータに関しては、確率が0になる(実際は確率ではないため、非常に大きい負の値)ように初期化すれば、その部分に関して学習する必要がなくなり、効率的ではないのかと考えました。
実際、上記を行うと、あり得ない遷移部分について、非常に大きい負の値でスコア関数の
を初期化するため、学習の初期から、あり得ないラベル系列を出力をしにくくなります。
BERT-CRFにおいて、上記のような初期パラメータを設定した方が、精度が高くなり、サンプル数を少なくしても頑健であることが複数のデータセットによる実験で明らかになりました。ここでは、その中のwikipediaを使用して作成したデータセットによる結果を紹介したいと思います。
x軸の左から、学習データセットを100%(504文)使用、50%(252文)、25%(126文)のように、サンプリングし、精度を比較しました。
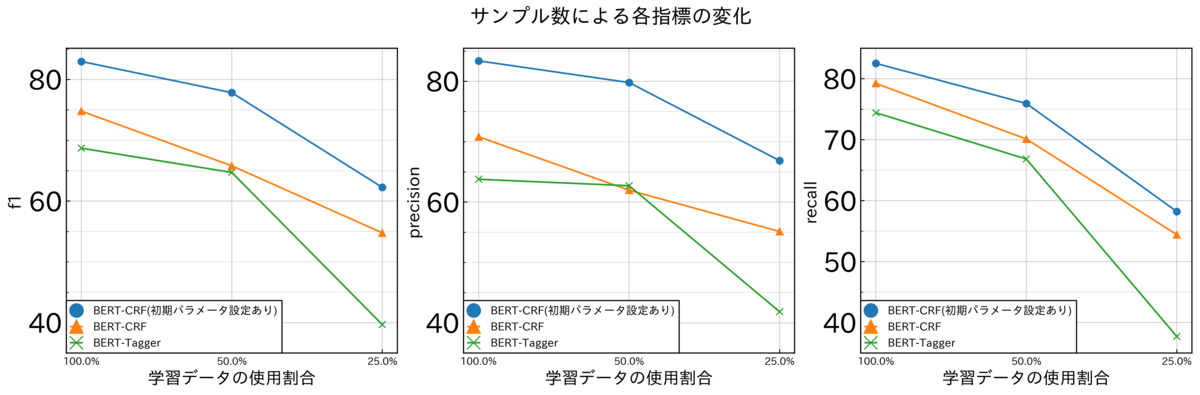
性能検証
ここでも上記の実験と同じく、wikipediaを使用した実験用データセット(学習データ504文、テストデータ100文)を用いて、小さいデータセットでの実験結果をご紹介します。
精度
以下の表から、1. BERT-CRF、2. CRFの初期パラメータの適切な設定 の2点に効果があることが実験的にわかりました。
特に、precisionに関して、非常に効果があることがわかりました。

抽出例
ここでは、テストデータセットで、BERT-CRFとBERT-Taggerの違いがはっきりわかる出力例を紹介します。
以下の例では、BERT-Taggerにおいて、「の」の部分をO(その他)であると判定しています。これは、前後のラベル情報を考慮せずに、一般的に「の」が製品名であるより、O(その他)である確率が高いと判断した結果であると推測できます。一方で、BERT-CRFでは、ラベル単体ではなく、「O(その他)→I-製品名」という遷移はない(非常に起こりにくい)と、学習しているため、正しく出力していると考えられます。
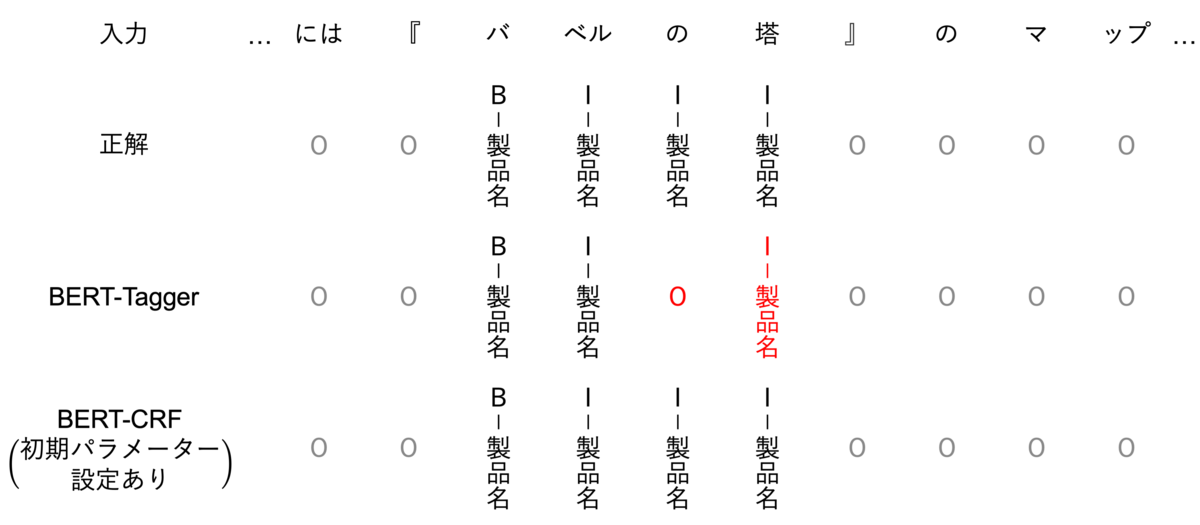
他の出力についても観察すると、もちろん、BERT-TaggerやBERT-CRFでもミスしている例も存在していますが、BERT-CRF(初期パラメータ設定あり)の場合、例え抽出する必要がない単語を間違えて抽出していたとしても、アノテーションのルール(B-◯◯→I-□□という遷移はない)を守って出力しています。一方で、BERT-Taggerの場合は、各tokenをそれぞれが自由にあり得そうなラベルを出力してしまっていました。
考察として、BERT-CRFでは、「株」のようないかにも組織名として抽出されそうなtokenがあったとしても、前後のtokenを考慮して、ラベルを判定するということが起因して、精度が向上したのではないかと考えられます(逆も然り)。
【おまけ】精度向上に貢献しなかった工夫
ここでは、おまけとして、試してみたが精度向上に貢献しなかった取り組みの一つをご紹介します。 ※ あくまで、今回のデータセットで実験した場合での話であることをご了承ください。
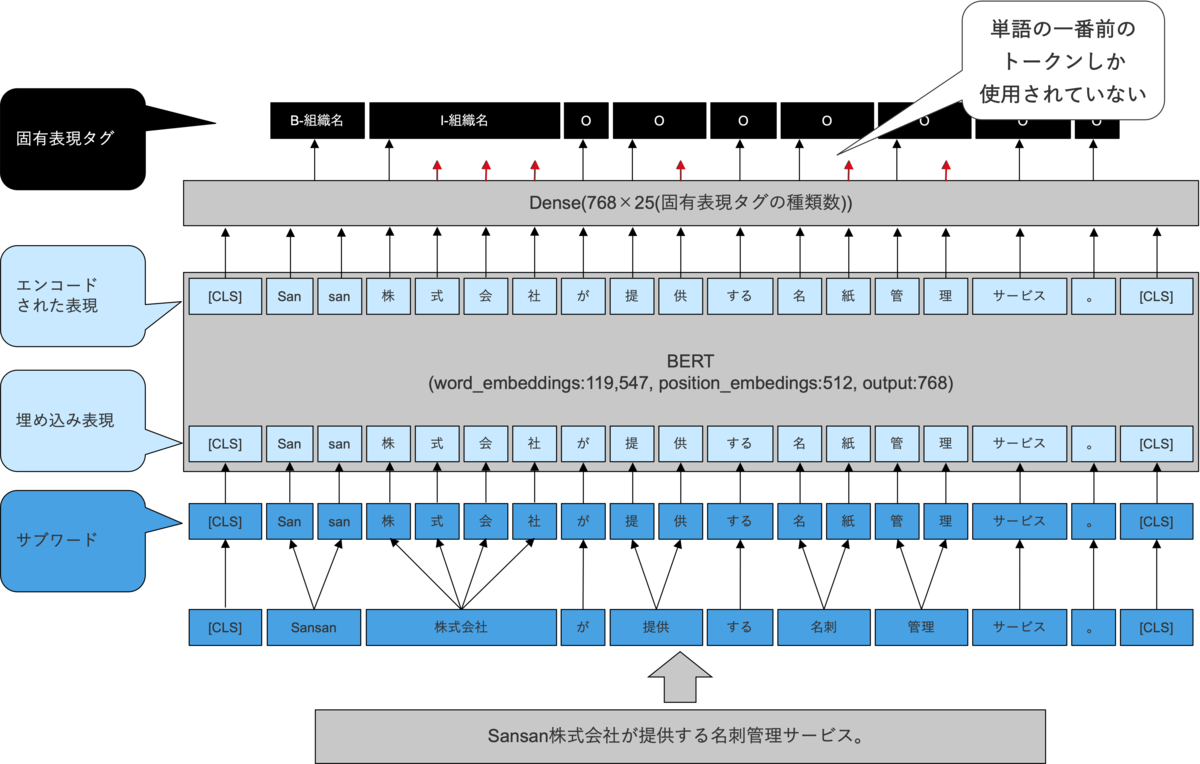
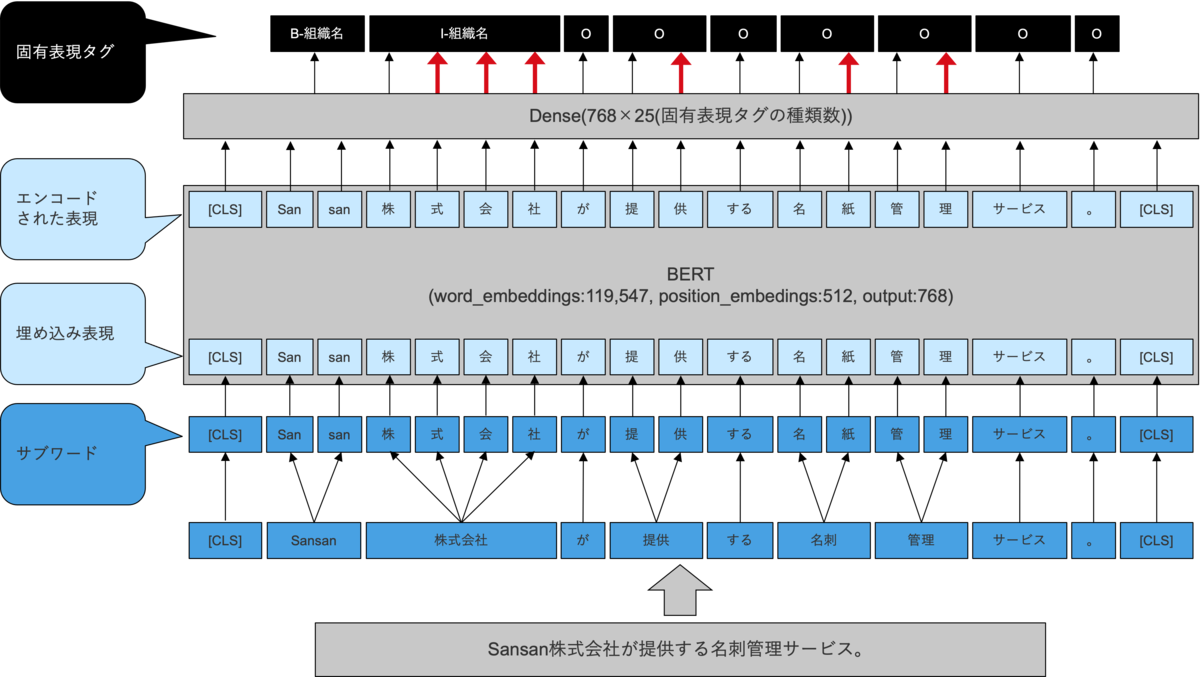
以下の図のように、「株式会社」は、BERTに入力される前に、さらに分割され、「株」「式」「会」「社」に分割されるとします。このとき、知りたいことは、「株式会社」のラベルであり、「株」「式」「会」「社」それぞれのラベルではありません。既存の手法では、分割した後の「株」の特徴量を使用して、「株式会社」のラベルを予測していました。
ここで、「式」「会」「社」の部分も使って予測すれば、情報量が増えて、精度向上すると考えて、実験により確かめてみたのですが、残念ながら、精度はむしろ悪化してしまいました。
おわりに
自然言語処理タスクに、ここまで取り組んだことは今回が初めてで、はじめはtransformersというパッケージに慣れるところからのスタートでした。さらには、プロダクトで動作するようにコードを整備するということもあり、pythonの綺麗な書き方やGit等の使い方も改めて勉強しました。課題への取り組み方が今までとは全く異なっていて、進め方に戸惑う部分も多かったのですが、メンターの黒木や高橋寛治をはじめ、多くの研究員の方にご協力いただき、精度改善、プロダクトに反映させることができました。 今後ともプロダクトに貢献できるような精度改善に邁進していきます!
参考文献
[1] Souza, F., Nogueira, R., and Lotufo, R. (2019). Portuguese named entity recognition using bert-crf. arXiv:1909.10649.
*1:大規模な学習データセットがあれば、そのようなパターンを学習できるのかもしれませんが、固有表現抽出のアノテーション作業はコストが高く、小さいデータセットでも上記のような問題を解消したいというモチベーションがあります。