
こんにちは。 DSOC R&D グループの高橋寛治です。
社内の研究開発部勉強会にて、Texthero が便利だという話を聞きかじりました。
Texthero は、テキストの前処理から変換、可視化までを pandas 上でうまく扱える Python パッケージです。 現状では、英語のみ対応しているパッケージです。
本記事では、日本語を解析できるように追加でコードを書いて使ってみたので紹介します。
Texthero のコードを読む
Texthero は GitHub 上で公開されています。 Version 1.0.9 をベースに日本語処理を実装する観点でコードを読みます。
texthero パッケージ配下には、いくつかのスクリプトが含まれています。
この中で、トークナイズや固有表現抽出は nlp.py、前処理は preprocessing.py に含まれています。
nlp.py を詳しく見てみると、固有表現抽出(named_entities) と複合名詞抽出(noun_chunks) が記述されています。
これらの関数は、引数および戻り値に pandas.Series を取ります。
README.md に記載がある通り、pandas の pipe で利用できるように書かれているということですね。
関数内では spacy を用いて、固有表現抽出や複合名詞抽出を行っています。
spacy のモデル en_core_web_sm がハードコーディングされていますので、基本は英語前提のコードとなります。
日本語を解析できるように準備する
日本語において、spacy で利用可能な素晴らしいツール GiNZA が公開されています。 こちらを利用して、日本語の解析を行います。
利用イメージとしては、以下を想定します。
df["tfidf"] = ( df['text'] .pipe(ja_hero.tokenize) .pipe(hero.tfidf) )
関連するライブラリのバージョンを記しておきます。
- ginza==4.0.6
- texthero==1.0.9
- gensim==3.8.3
また、今回書くコードは ja_texthero というパッケージとして書いています。
以下は、__init__.py に記述している内容です(実装していない箇所は、適宜コメントアウトしてください)。
from .nlp import named_entities from .preprocessing import tokenize
さて、具体的にやることは、入力文のトークン化(分かち書き)です。
次のように関数を準備します(ja_texthero/preprocessing.py)。
import spacy import pandas as pd def tokenize(s: pd.Series) -> pd.Series: nlp = spacy.load('ja_ginza') tokens = [] for doc in nlp.pipe(s.astype("unicode").values, batch_size=32): tokens.append(" ".join([token.text for token in doc])) return pd.Series(tokens, index=s.index)
Series を受け取り、スペース区切りで分かち書きされた結果を返却します。
>>> s = pd.Series(["これはテストです。"]) >>> tokenize(s) 0 これ は テスト です 。 dtype: object
パイプラインとして使う
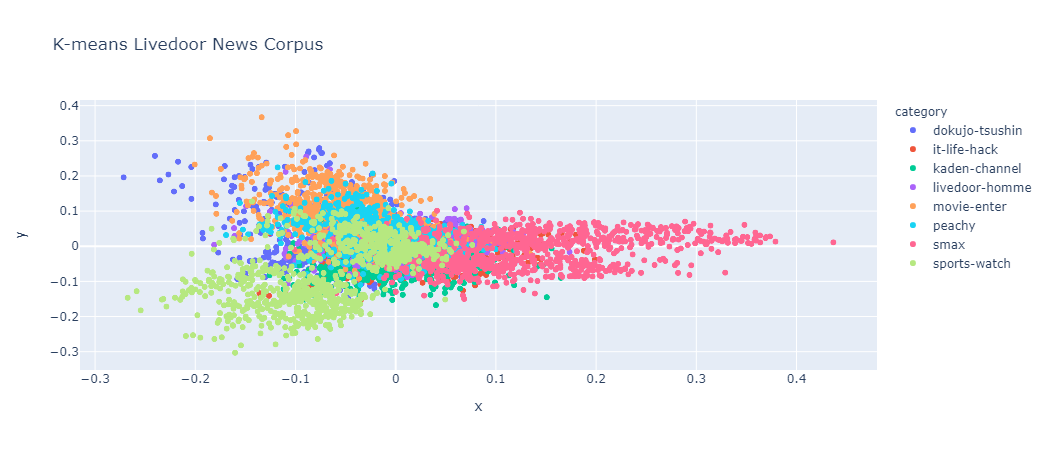
サンプルで上げられている例を日本語で行います。 TF-IDF 行列を PCA で可視化しやすいよう 2次元に次元削減し、K-means 結果とともにプロットします。
データセットには、livedoor ニュースコーパスを利用いたします。 まずは、データセットを適当に展開した後に、DataFrame として読み込みます。 なお、ここでは解析対象とするテキストは、タイトルのみとします。 Jupyter Notebook 上で対話的に解析を行います。
import glob import pandas as pd categories = [ "dokujo-tsushin", "it-life-hack", "kaden-channel", "livedoor-homme", "movie-enter", "peachy", "smax", "sports-watch", ] corpus = [] for category in categories: for textfile_path in glob.glob(f"./data/text/{ category }/*.txt"): try: with open(textfile_path, "rt") as fin: document = { "category": category, "text": fin.read().strip().split("\n")[2], # タイトルは2行目 } corpus.append(document) except: continue df = pd.DataFrame(corpus)
これで df には、カテゴリとタイトルテキストが入った状態となります。
ここからは TF-IDF および K-means によるクラスタリング、そして PCA による次元削減を行います。
import texthero as hero import ja_texthero as ja_hero df["tfidf"] = ( df['text'] .pipe(ja_hero.tokenize) .pipe(hero.tfidf) ) df['kmeans_labels'] = ( df['tfidf'] .pipe(hero.kmeans, n_clusters=8) .astype(str) ) df['pca'] = df['tfidf'].pipe(hero.pca) hero.scatterplot(df, 'pca', color='category', title="K-means Livedoor News Corpus")
2次元に削減された TF-IDF をプロットし、色には K-means のクラスタリング結果を利用します。 この空間内だとカテゴリごとに近くにありそうなのが、数行のコードでわかりました。
固有表現抽出もやってみる
GiNZA で実装されている固有表現抽出を利用し、結果を取得する関数を用意します。
こちら(ja_texthero/nlp.py)は、texthero の nlp.py にある named_entities で利用するモデルを変更したのみです。
import spacy import pandas as pd def named_entities(s: pd.Series) -> pd.Series: entities = [] nlp = spacy.load('ja_ginza') for doc in nlp.pipe(s.astype("unicode").values, batch_size=32): entities.append( [(ent.text, ent.label_, ent.start_char, ent.end_char) for ent in doc.ents] ) return pd.Series(entities, index=s.index)
お試しで日付が固有表現として抽出されるか確認します。
>>> import ja_texthero as ja_hero >>> s = pd.Series(["本記事は2021年6月21日に記述されました。"]) >>> ja_hero.named_entities(s) 0 [(2021年6月21日, Date, 4, 14)] dtype: object
問題なく取得できています。
なお、今回のコードは、自分のレポジトリにまとめていますので、参考にお使いください。
おわりに
DataFrame の pipe がすごく便利だと感じました。 また、ここに目をつけた texthero は、DataFrame に慣れ親しんだ人に対してテキスト処理をかなり身近にするものだと思います。
別の可視化手法やストップワードは実装してみたいと思いました。
執筆者プロフィール
高橋寛治 Sansan株式会社 DSOC (Data Strategy & Operation Center) 研究開発部 研究員
阿南工業高等専門学校卒業後に、長岡技術科学大学に編入学。同大学大学院電気電子情報工学専攻修了。在学中は、自然言語処理の研究に取り組み、解析ツールの開発や機械翻訳に関連する研究を行う。大学院を卒業後、2017年にSansan株式会社に入社。キーワード抽出など自然言語処理を生かした研究開発に取り組む。
▼本連載のほかの記事はこちら