こんにちは、ニューラルネット老人こと糟谷勇児です。
最近はメルカリでアンモナイトが入っている(かもしれない)北海道の石を買って化石発掘を子どもと一緒にやっています。
売っているアンモナイト化石はどれも立派なんですが、実際自分で掘ってみると1mmぐらいのアンモナイトとかもあったり、きれいに掘れなくてぶっ壊れたりしてリアル感があります。


化石もGPGPUも自分でやってみるとリアル感が分かっていいですね。
そんなわけで今回もGPGPUをやっていきます。
CUDAをやるには
C#でGPGPUをしたいと思っていたんですが、まずは生のCUDAを使ってみたいと思いましてC++でやってみたいと思います。
Visual StudioでCUDA開発する場合はCUDA Toolkitをインストールすると動かすことができます。
developer.nvidia.com
さて、読者の皆様は新しいライブラリを使うときはどうしていますか?
私はまずは最小限の機能だけを自分のプログラムから動かして使えるかどうかを確かめます。
そんなわけでqiita等からコードをコピペして動かしてみたりするのですが、CUDAはバージョンアップが激しく、ネット上にあるコードはあまり役に立ちません。qiitaなどにあるコードはオフィシャルなものと比べるとあまり体裁を気にしなくていいのでコメントやエラー処理がなかったりしてシンプルでそれはそれでいいんですけどね。
まずはオフィシャルなサンプルを動かすことにします。
CUDAのサンプルはToolkitに同梱されていて、そのパスはこちらに記載されています。
docs.nvidia.com
CUDAのサンプルにあるVisual Studioのソリューションを起動するとすごくたくさんのプロジェクトが出てきて、私の環境では特にエラーなく動かすことができました。
ただし、画像を表示するものはそのまま動かそうとするとエラーになるようです。
というのもCUDAのサンプルではなるべく効率化するために、計算用にGPUメモリに置いた画像をデータをそのまま描画に使おうとします。しかし、私が使用しているGCPのインスタンスは計算用のGPUとは別で描画用のGPUを持っているのでそのまま使い回せないという事情があります。
引数で画像を表示しないオプションを選べば動かすことができます。

CUDAを自分のプロジェクトで動かす
さて、サンプルが動くことはわかりましたが、自分のプログラムから動かせるかはまだわかっていません。
早速自分で作ったプロジェクトに移植していきたいです。今回は最もシンプルでディープラーニングに有用な行列の掛け算を行うMatrixMulを試します。これと画像にフィルタをかける処理だけわかればディープラーニングのCUDA化はほぼできるんじゃないかなと思います。
MatrixMulは行列の掛け算、すなわち
行列C=行列A×行列B
を行うプログラムです。
こちらのサンプルですが、かなり多数のhelper関数をincludeして使用しています。しかし全部持ってくると何が動いているかわからないので本当に必要なものだけをコピペして使います。
#include <assert.h> #include <stdio.h> #include <cuda_runtime.h> #include <math.h> #include <stdlib.h> static const char* _cudaGetErrorEnum(cudaError_t error) { return cudaGetErrorName(error); } template <typename T> void check(T result, char const* const func, const char* const file, int const line) { if (result) { fprintf(stderr, "CUDA error at %s:%d code=%d(%s) \"%s\" \n", file, line, static_cast<unsigned int>(result), _cudaGetErrorEnum(result), func); exit(EXIT_FAILURE); } } #define checkCudaErrors(val) check((val), #val, __FILE__, __LINE__) template <int BLOCK_SIZE> __global__ void MatrixMulCUDA(float* C, float* A, float* B, int wA, int wB) { int bx = blockIdx.x; int by = blockIdx.y; int tx = threadIdx.x; int ty = threadIdx.y; int aBegin = wA * BLOCK_SIZE * by; int aEnd = aBegin + wA - 1; int aStep = BLOCK_SIZE; int bBegin = BLOCK_SIZE * bx; int bStep = BLOCK_SIZE * wB; float Csub = 0; for (int a = aBegin, b = bBegin; a <= aEnd; a += aStep, b += bStep) { __shared__ float As[BLOCK_SIZE][BLOCK_SIZE]; __shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE]; As[ty][tx] = A[a + wA * ty + tx]; Bs[ty][tx] = B[b + wB * ty + tx]; __syncthreads(); #pragma unroll for (int k = 0; k < BLOCK_SIZE; ++k) { Csub += As[ty][k] * Bs[k][tx]; } __syncthreads(); } //if (Csub < 0) Csub = 0; int c = wB * BLOCK_SIZE * by + BLOCK_SIZE * bx; C[c + wB * ty + tx] = Csub; } void ConstantInit(float* data, int size, float val) { for (int i = 0; i < size; ++i) { data[i] = val; } } int MatrixMultiply(int argc, char** argv, int block_size, const dim3& dimsA, const dim3& dimsB) { unsigned int size_A = dimsA.x * dimsA.y; unsigned int mem_size_A = sizeof(float) * size_A; float* h_A; checkCudaErrors(cudaMallocHost(&h_A, mem_size_A)); unsigned int size_B = dimsB.x * dimsB.y; unsigned int mem_size_B = sizeof(float) * size_B; float* h_B; cudaMallocHost(&h_B, mem_size_B); cudaStream_t stream; const float valB = 0.01f; ConstantInit(h_A, size_A, 1.0f); ConstantInit(h_B, size_B, valB); float* d_A, * d_B, * d_C; dim3 dimsC(dimsB.x, dimsA.y, 1); unsigned int mem_size_C = dimsC.x * dimsC.y * sizeof(float); float* h_C; cudaMallocHost(&h_C, mem_size_C); if (h_C == NULL) { fprintf(stderr, "Failed to allocate host matrix C!\n"); return 0; } cudaMalloc(reinterpret_cast<void**>(&d_A), mem_size_A); cudaMalloc(reinterpret_cast<void**>(&d_B), mem_size_B); cudaMalloc(reinterpret_cast<void**>(&d_C), mem_size_C); cudaEvent_t start, stop; cudaEventCreate(&start); cudaEventCreate(&stop); cudaStreamCreateWithFlags(&stream, cudaStreamNonBlocking); cudaEventRecord(start, stream);//time from cudaMemcpyAsync cudaMemcpyAsync(d_A, h_A, mem_size_A, cudaMemcpyHostToDevice, stream); cudaMemcpyAsync(d_B, h_B, mem_size_B, cudaMemcpyHostToDevice, stream); dim3 threads(block_size, block_size); dim3 grid(dimsB.x / threads.x, dimsA.y / threads.y); MatrixMulCUDA<32> <<<grid, threads, 0, stream >>> (d_C, d_A, d_B, dimsA.x, dimsB.x); cudaMemcpyAsync(h_C, d_C, mem_size_C, cudaMemcpyDeviceToHost, stream); cudaEventRecord(stop, stream);// end first calc cudaEventSynchronize(stop); printf("done\n"); cudaStreamSynchronize(stream); float msecTotal = 0.0f; cudaEventElapsedTime(&msecTotal, start, stop); printf("First Time= %.3f msecn",msecTotal); cudaEventRecord(start, stream);//start time for average calc int nIter = 300; for (int j = 0; j < nIter; j++) { MatrixMulCUDA<32> <<<grid, threads, 0, stream >>> (d_C, d_A, d_B, dimsA.x, dimsB.x); } cudaEventRecord(stop, stream); cudaEventSynchronize(stop); msecTotal = 0.0f; cudaEventElapsedTime(&msecTotal, start, stop); float msecPerMatrixMul = msecTotal / nIter; double flopsPerMatrixMul = 2.0 * static_cast<double>(dimsA.x) * static_cast<double>(dimsA.y) * static_cast<double>(dimsB.x); double gigaFlops = (flopsPerMatrixMul * 1.0e-9f) / (msecPerMatrixMul / 1000.0f); printf( "Performance= %.2f GFlop/s, Time= %.3f msec, Size= %.0f Ops," " WorkgroupSize= %u threads/block\n", gigaFlops, msecPerMatrixMul, flopsPerMatrixMul, threads.x * threads.y); cudaMemcpyAsync(h_C, d_C, mem_size_C, cudaMemcpyDeviceToHost, stream); cudaStreamSynchronize(stream); // Clean up memory cudaFreeHost(h_A); cudaFreeHost(h_B); cudaFreeHost(h_C); cudaFree(d_A); cudaFree(d_B); cudaFree(d_C); cudaEventDestroy(start); cudaEventDestroy(stop); } int main(int argc, char** argv) { printf("[Matrix Multiply Using CUDA] - Starting...\n"); int devID = 0; cudaSetDevice(devID); int major = 0, minor = 0; cudaDeviceGetAttribute(&major, cudaDevAttrComputeCapabilityMajor, devID); cudaDeviceGetAttribute(&minor, cudaDevAttrComputeCapabilityMinor, devID); printf("GPU Device %d: with compute capability %d.%d\n\n", devID, major, minor); int block_size = 32; int ratio = 4; dim3 dimsA(5 * ratio * block_size, 5 * ratio * block_size, 1); dim3 dimsB(5 * ratio * block_size, 5 * ratio * block_size, 1); printf("MatrixA(%d,%d), MatrixB(%d,%d)\n", dimsA.x, dimsA.y, dimsB.x,dimsB.y); int matrix_result = MatrixMultiply(argc, argv, block_size, dimsA, dimsB); exit(matrix_result); }
こんな感じです。このコードもバージョンアップですぐ使えなくなると思いますが。
なんかエラーは出るんですがコンパイルは通ります。
ビルドのためのCUDA C/C++というところの設定はサンプルと同じにします。
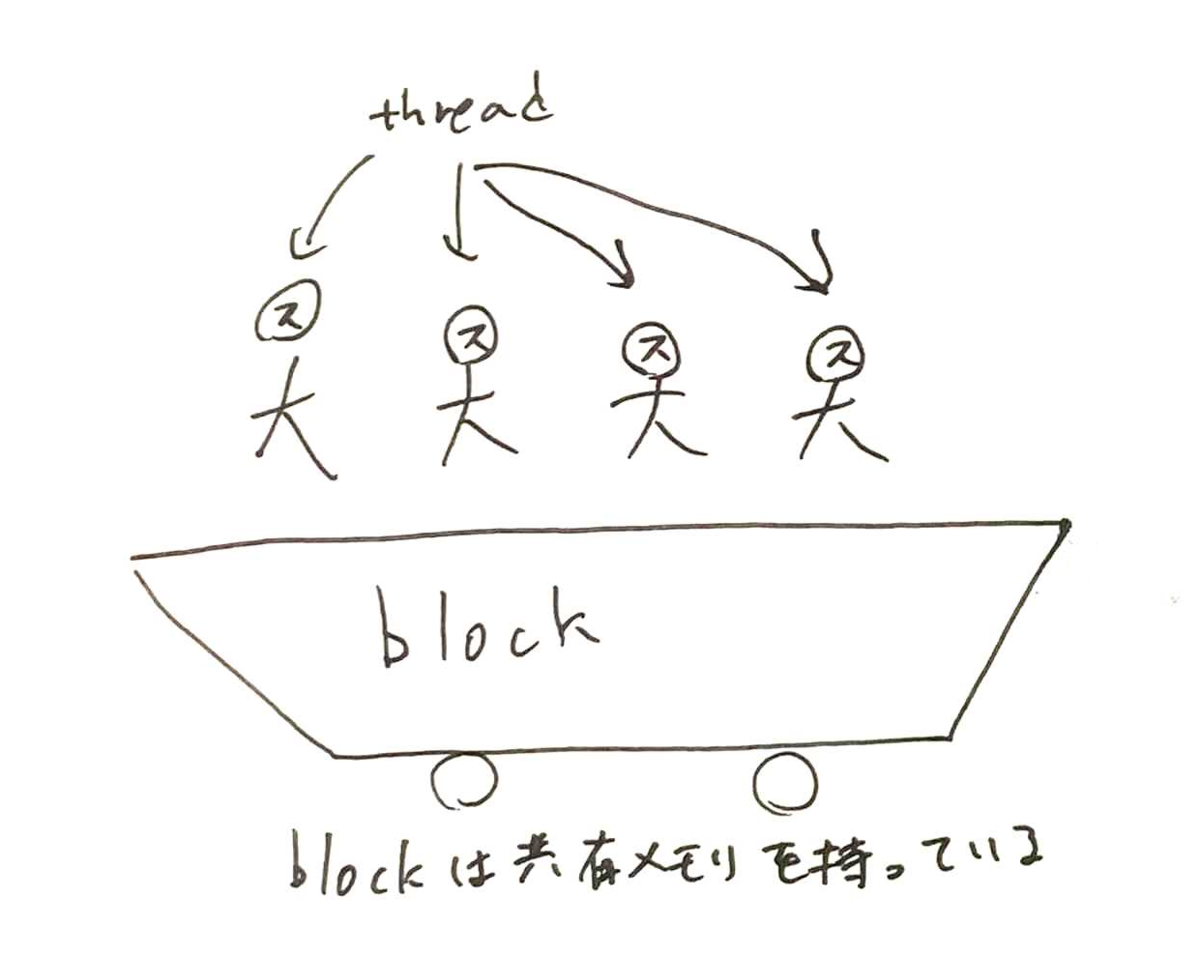
コードから読み解いた行列計算の仕組みはこんな感じです。
まず、CUDAにはThreadとBlockという概念があります。Threadは他のプログラミングのThreadと大体同じような概念で、それを束ねるのがBlockです。Blockは共有のメモリを持っていて、ここはそのBlockに属するThreadであれば高速に出し入れ出来ます。
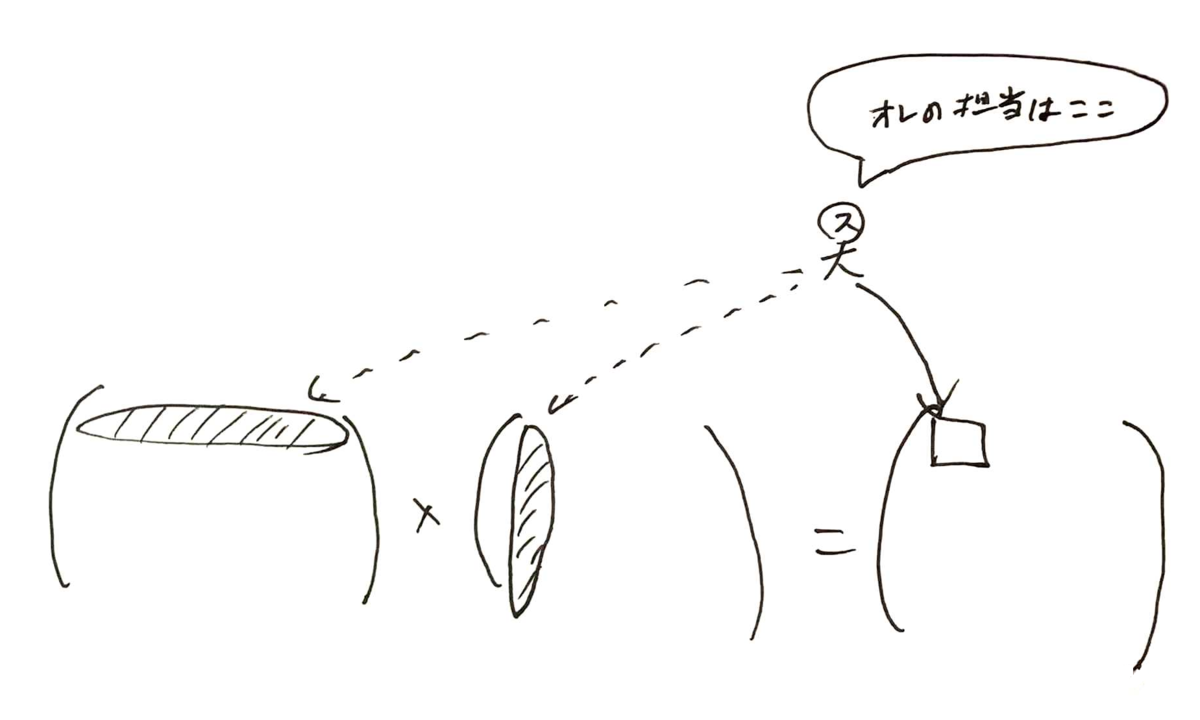
行列計算なので、横×縦になるわけですが、1つのThreadは出力となる行列の1つの要素を作るイメージです。
この高速な共有メモリをうまく活用するため、一行全部を一度に計算せず、部分ごとに計算していきます。
まずはThreadみんなで共有メモリにデータを入れます。
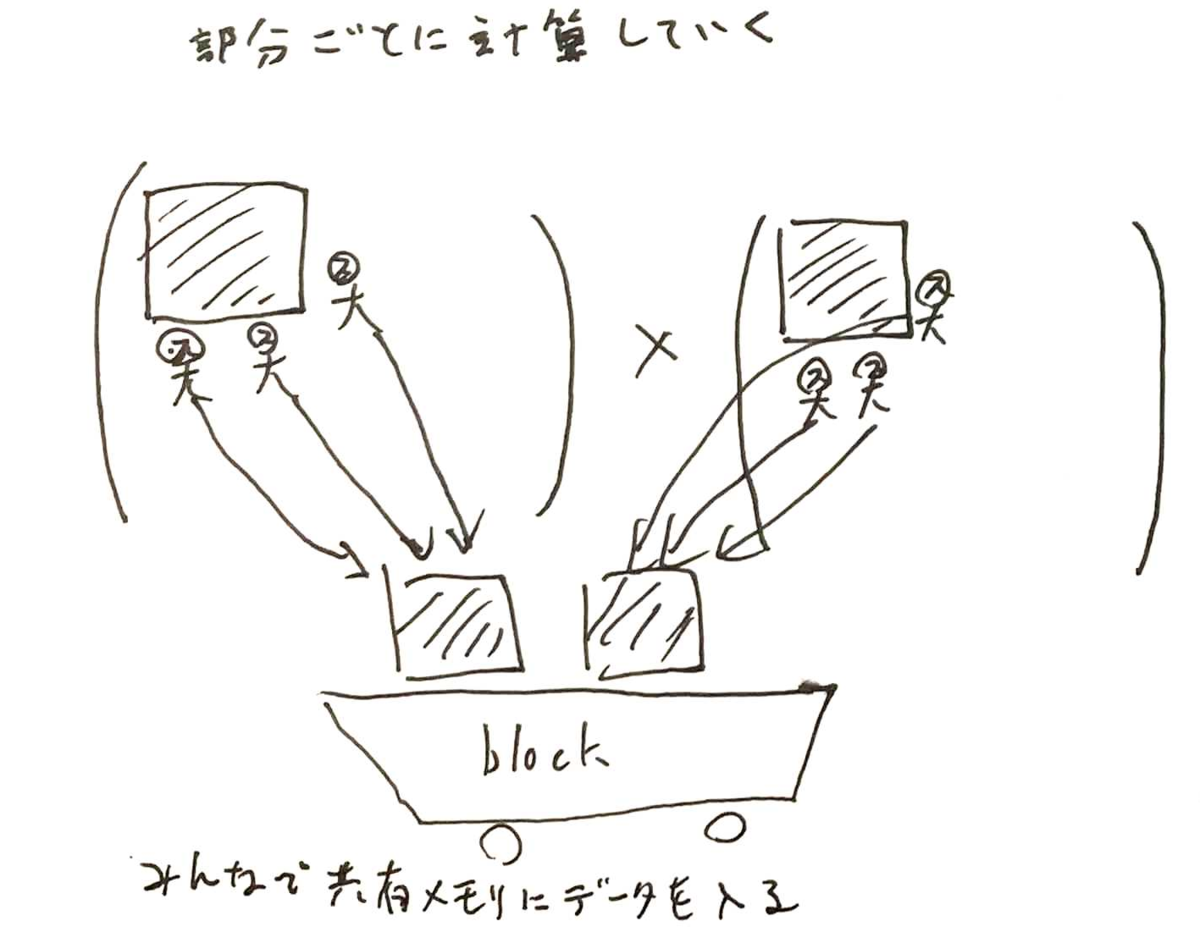
共有メモリに積んだデータから各Threadは自分の担当領域を計算して足し合わせていきます。
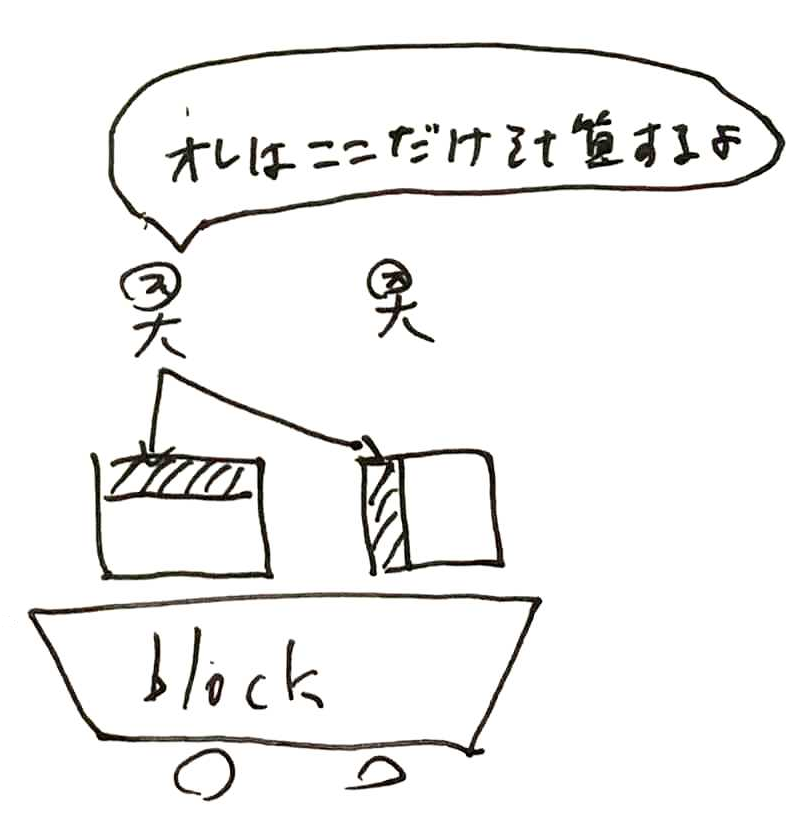
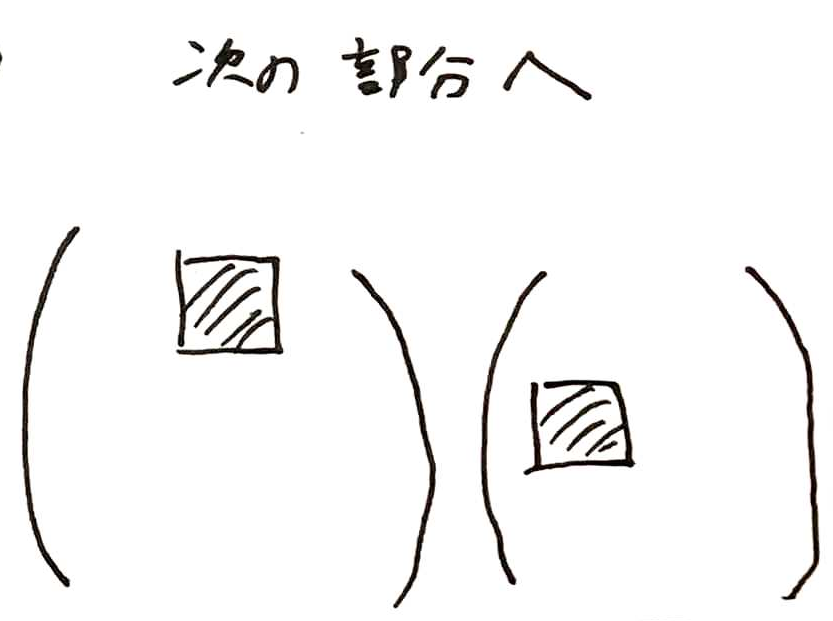
そして、次の部分行列にも同じ計算をしていきます。
全部終わったら完了です。Blockは一つではなく多数のBlockが同時並行で処理しているので高速に計算が終わります。
実験CUDAで行列の掛け算をすると速いのか
では最後にCPUで行列計算をするのとGPUでするので比較してみます。
行列はそれぞれ640*640, 1280*1280, 2560*2560の行列二つを掛け算します。
表にGPUを使用した場合とCPUを使用した場合のそれぞれの処理時間を記載します。
また、CPU/GPU時間比は時間が何倍になったかという比を計算しています。時間の比が90ということは簡単に言えば90倍速いということです。

当たり前かもしれませんが、GPUは行列のサイズが大きければ大きいほどCPUと比較した際の高速化力が高いと言えます。
十分小さい行列ならCPUのほうが処理は速いでしょう。
また、GPUでの計算はGPUデバイスに計算データをメモリ転送する必要があります。そのオーバーヘッドを入れた場合と計算のみの場合それぞれで出しています。また、CPUでの行列計算にはEigenというライブラリを使ってみました。CPUでの処理は並列化していないため、10倍程度は今より速くできると思います。
それでもオーバーヘッド込みで100倍から200倍の差があるので、10~20倍は速くなります。
計算だけの比較なら50倍の差があるので、うまくデータをGPUの中で使いまわせればかなりの高速化が可能になります。
ちなみにGPUはifでの分岐に弱いという話もあります。しかし、DeepLearningではReLUなどifを使いたくなるケースもあります。なので行列計算には不要ですが、試しに一つの要素の結果を計算する直前で、
if (Csub < 0) Csub = 0;
という一文を入れてみましたが、計算時間に影響はありませんでした。また、シグモイド関数やソフトマックス関数のためにexp()を使うことも考えられます。こちらもやってみましたが計算時間に影響はありませんでした。
まとめ
CUDAの処理が少しずつ分かってきました。GPUは思ったより速かったです。オーバーヘッドを入れても結構速いとすれば重い部分だけGPU化すれば速くできる可能性もあるので、意外と自作DeepLearningに取り入れられるのかもしれません。次は画像にフィルタをかける処理を学んでいきたいと思います。