
こんにちは。研究開発部 Architectグループにてデータエンジニアとしてデータ基盤の開発・運用を担当しているジャン(a.k.a jc)です。 4月1日に入社してから、全社横断データ基盤のCI/CD自動化、承認システムの実装、監視の強化やリファクタリングなどの業務を取り組んでおり、かなり濃厚な4カ月を過ごしました。 今回は【R&D DevOps通信】連載の11回目、弊チームの鈴木が紹介してくれた「Cloud Composerを用いたデータ基盤の転送パイプライン構築」
の続編として、データ基盤の監視について紹介しようと思います。
背景
全社横断データ基盤の開発のみならず、運用・保守も担当している弊チームは日々さまざまな障害と向き合っています。データ基盤の品質・信頼性を担保し、問題が発生した場合、一刻も早く問題を特定して対応できるような監視が不可欠だと我々は考えています。
具体的に言うと、現在構築中のデータ基盤では、Cloud Composerで日次・週次実行されているデータ転送のパイプラインはnotify_error_to_slackというタスクが組み込まれており、DAG内全てのタスクのエラーが発生した場合、指定したSlackチャンネルにアラートを上げることができます(詳細はこちらの記事をご覧ください)。
しかしながら、そもそも転送されているテーブルが空(データが0件)、もしくはデータの転送が予定時刻より遅延が発生した場合、障害が出たにも関わらず、DAG内のタスクは全て正常終了になります。これらの障害を検出するために、別途監視の仕組みを構築することにしました。一方、開発とメンテナンスの利便性を考慮して、監視用のパイプラインもデータ基盤の転送パイプラインと同じくAirflowのDAGとして追加し、Cloud Composerで管理しています。
監視項目
チーム内で議論した結果、下記の優先度の高い監視項目を洗い出しました。
- テーブルが空になっているか
- 日次・週次処理が遅れているか
- データ量は前日と比べて激減(増)したか
- Cloud Composer (Airflow)自体が正常に動いているか
監視用のメタ情報はBigQueryが提供しているDATASET_ID.INFORMATION_SCHEMA.PARTITIONSというINFORMATION_SCHEMAのビューから取得しています。
INFORMATION_SCHEMA.PARTITIONSからある時点において、各パーティション(パーティションがない場合はテーブル)の更新時刻、行数やバイト数などを監視するための必要情報を簡単に取得できます。
テーブルが空になっているか
転送パイプラインが一見して問題なく実行されたが、データソース側が何らかの原因によって実際に転送されているテーブルが空になっている場合は、以下の簡単なクエリで発見できます。
ORDER BYとLIMIT 1追加する理由としては、日付でパーティションを切っているテーブルの場合、DATASET_ID.INFORMATION_SCHEMA.PARTITIONSのレコードは複数あり、最新のレコードのみに着目するためです。
SELECT total_rows FROM ${dataset_id}.INFORMATION_SCHEMA.PARTITIONS WHERE table_name = '${table_name}' ORDER BY last_modified_time DESC LIMIT 1;
日次・週次処理が遅れているか
データソース側あるいはCloud Composerの遅延によって日次・週次処理が遅れる障害がしばしば起きています。
INFORMATION_SCHEMA.PARTITIONSのカラムlast_modified_timeはデータがBigQueryに取り込まれた時刻なので、転送パイプライン(バッチ処理)の終了時刻に近似できます。
処理開始してからn時間(事前に定義した値で、転送遅れをやや許容する)以内に終了したかを監視することで、遅延を発見できます。
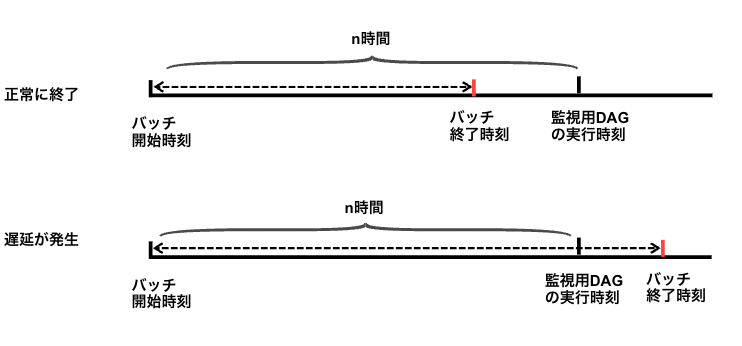
last_modified_timeのMAXを取っている理由としては、「テーブルが空になっているか」と同じく、パーティションテーブルを対応するためです。
SELECT DATETIME(MAX(last_modified_time)) > DATE_SUB(CURRENT_DATETIME(), INTERVAL ${ interval_hours } HOUR) FROM ${dataset_id}.INFORMATION_SCHEMA.PARTITIONS WHERE table_name = '${table_name}';
データ量は前日と比べて激減(増)したのか
何らかの操作ミスあるいは変換ミスによってデータ量は前日と比べて激減(増)したのを監視します。ただし、INFORMATION_SCHEMA.PARTITIONSは当日のデータしか取得できないため、
事前にBigQueryのscheduled queries機能で日次で各テーブルの行数、バイト数などのメタ情報を収集して履歴テーブルtables_metadata_historiesを作成しておく必要があります。tables_metadata_historiesへデータ収集するクエリは下記の通りです。
SELECT table_catalog, table_schema, table_name, storage_tier, SUM(total_rows) AS total_rows, SUM(total_logical_bytes) AS total_logical_bytes, SUM(total_billable_bytes) AS total_billable_bytes, MAX(last_modified_time) AS last_modified_time, CURRENT_TIMESTAMP() AS saved_time FROM ${project_id}.${dataset_id}.INFORMATION_SCHEMA.PARTITIONS GROUP BY table_catalog, table_schema, table_name, storage_tier
履歴テーブルがあると、前日と比べて行数の増減数(率)、バイト数の増減数(率)を収集することが可能です。 増減しきい値の設定などすぐには難しいため、一旦下記のクエリで各テーブルの増減情報を収集しておきます。
SELECT table_schema, table_name, total_rows, total_logical_bytes, last_modified_time, saved_time, -- 前日と比べて行数の増減数 total_rows - LAG(total_rows) OVER (PARTITION BY table_schema, table_name ORDER BY saved_time ASC) AS total_rows_growth, -- 前日と比べて行数の増減率 (%) ROUND((total_rows / NULLIF((LAG(total_rows) OVER (PARTITION BY table_schema, table_name ORDER BY saved_time ASC)), 0) - 1) * 100.00, 2) AS total_rows_growth_rate, -- 前日と比べてバイト数の増減数 total_logical_bytes - LAG(total_logical_bytes) OVER (PARTITION BY table_schema, table_name ORDER BY saved_time ASC) AS total_logical_bytes_growth, -- 前日と比べてバイト数の増減率 (%) ROUND((total_logical_bytes / NULLIF((LAG(total_logical_bytes) OVER (PARTITION BY table_schema, table_name ORDER BY saved_time ASC)), 0) - 1) * 100.00, 2) AS total_logical_bytes_growth_rate FROM ${project_id}.${dataset_id}.tables_metadata_histories
Cloud Composer (Airflow)自体が正常に動いているか
上記クエリは最終的に監視用DAGに組み込むことになるため、Cloud Composerに依存しています。Cloud Composer自体が動いていなければ、転送パイプラインを監視する意味がありません。幸いなことにGCPのCloud Monitoringを利用すると、他のサービスを簡単に監視できるため、別途構築する必要がありません。
Cloud Composerが事前に用意してくれたairflow_monitoringというAirflowが正常に動いているかを監視するDAGがあります。
Cloud MonitoringにAlert Policyを追加し、さらにNotification ChannelにSlackを追加すれば、Airflowが止まった場合、アラートをSlackの指定チャンネルに投げられます。
監視用のDAGを構築
DAGの構築方法について紹介します。転送パイプラインごとに手作業でDAGを構築するのは大変なことになるので、一つのdag.pyファイルで全ての監視DAGを作成することにしました。
Cloud Composerのディレクトリ構成は以下のようになっています。データ基盤の転送パイプラインと同じ階層のディレクトリdags/s32bq_monitoringに監視用のDAGや設定ファイルを配置しています。
.
├── Dockerfile
├── Makefile
├── README.md
├── docker-compose.yml
├── config
│ ├── ...
├── dags
├── s32bq
├── ...
├── s32bq_monitoring
├── dag.py
├── utils.py
├── settings.yml
続いて設定用のyamlファイルを見ていきましょう。
interval_hours遅延の許容時間airflow_ui_url監視対象のDAGのurl(の一部)check_data_presence_sql「テーブルが空になっているか」を監視するクエリcheck_data_delay_sql「データ量は前日と比べて激減(増)したのか」を監視するクエリ
「データ量は前日と比べて激減(増)したのか」については、激減(増)のしきい値の設定が必要で長期間のデータを収集しないと難しいため、今回は割愛します。
interval_hours: 2 airflow_ui_url: https://hogehoge-dot-asia-northeast1.composer.googleusercontent.com/tree?dag_id= check_data_presence_sql: | SELECT total_rows FROM ${dataset_id}.INFORMATION_SCHEMA.PARTITIONS WHERE table_name = '${table_name}' ORDER BY last_modified_time DESC LIMIT 1; check_data_delay_sql: | SELECT DATETIME(MAX(last_modified_time)) > DATE_SUB(CURRENT_DATETIME(), INTERVAL {{ params.interval_hours }} HOUR) FROM ${dataset_id}.INFORMATION_SCHEMA.PARTITIONS WHERE table_name = '${table_name}';
パイプラインの構成
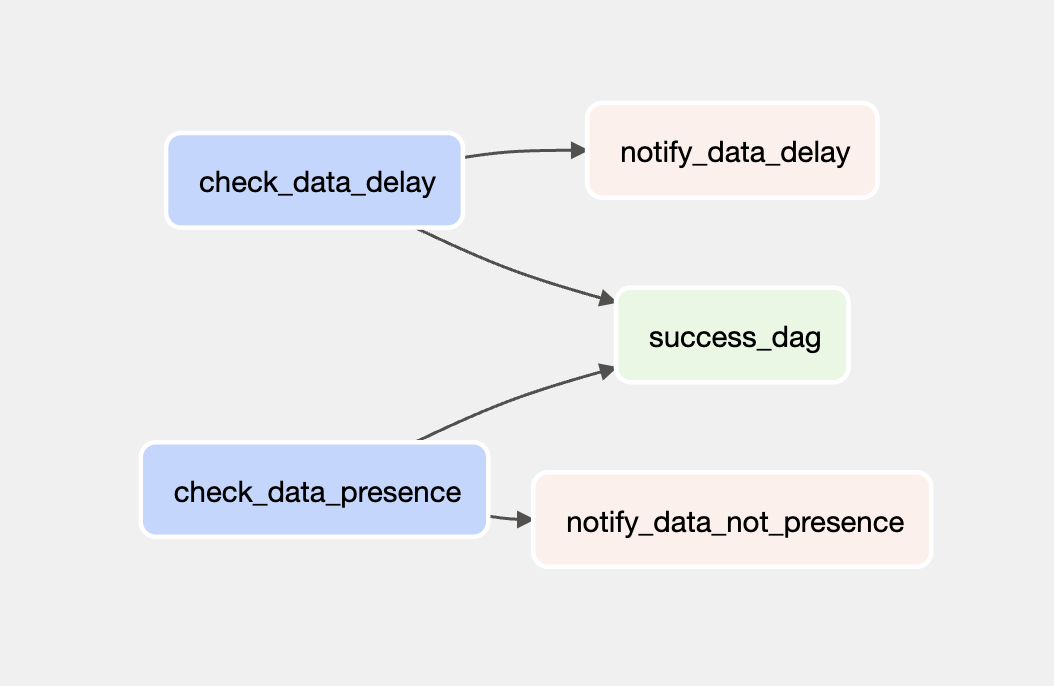
最終的に構築したシンプルな監視パイプラインは以下になります。
- check_data_delay 日次・週次処理が遅れているかをチェックする
- check_data_presence テーブルが空になっているかをチェックする
- notify_data_delay 日次・週次処理が遅れた場合、slackにアラートを上げる
- notify_data_not_presence テーブルが空になった場合、slackにアラートを上げる
- success_dag: DAGの実行が成功したのを表す
Airflowが提供しているAPIBigQueryCheckOperatorを利用して、クエリの返し値がtrueかfalseかを判断できます。
check_data_presence = BigQueryCheckOperator(
task_id="check_data_presence",
sql=monitoring_setting["check_data_presence_sql"],
use_legacy_sql=False,
params={
"bq_suffix": Variable.get("bq_suffix"),
"dataset": setting.bq.dataset,
"table": setting.bq.table_name,
},
location="asia-northeast1",
)
# データ転送が遅れている場合、失敗となる
check_data_delay = BigQueryCheckOperator(
task_id="check_data_delay",
sql=monitoring_setting["check_data_delay_sql"],
use_legacy_sql=False,
params={
"bq_suffix": Variable.get("bq_suffix"),
"dataset": setting.bq.dataset,
"table": setting.bq.table_name,
"interval_hours": monitoring_setting["interval_hours"],
},
location="asia-northeast1",
)
失敗した場合(BigQueryCheckOperatorがfalseになった場合)、Slackにアラートを上げます。
また、障害が起きたDAGを検索する手間を省くために、監視対象のurlもSlackに上げるメッセージに含めます。
def notify_error_to_slack( message: str, airflow_ui_url: str, dag_id: str, **context ) -> None: webhook = WebhookClient(Variable.get("slack_webhook_access_token")) webhook.send( text="alert", blocks=[ { "type": "section", "text": { "type": "mrkdwn", "text": f"Failed Task: s32bq monitoring\nDAG ID: {context['dag'].dag_id}", }, } ], attachments=[ { "color": "#ff0000", "blocks": [ { "type": "section", "text": { "type": "mrkdwn", "text": f"<{airflow_ui_url}{dag_id}|*{dag_id}*>\n{message}", }, } ], } ], ) notify_data_not_presence = PythonOperator( task_id="notify_data_not_presence", python_callable=notify_error_to_slack, op_kwargs={ "message": "対象テーブルが空になっています", "airflow_ui_url": monitoring_setting["airflow_ui_url"], "dag_id": setting.job.dag_name, }, provide_context=True, trigger_rule=TriggerRule.ONE_FAILED, ) notify_data_delay = PythonOperator( task_id="notify_data_delay", python_callable=notify_error_to_slack, op_kwargs={ "message": "データ転送が遅れています", "airflow_ui_url": monitoring_setting["airflow_ui_url"], "dag_id": setting.job.dag_name, }, provide_context=True, trigger_rule=TriggerRule.ONE_FAILED, )
アラートのメッセージは以下となります。 Slackメッセージのattachmentにエラー内容が含まれており、DAG IDをクリックするとAirflow UIから監視対象となる転送パイプラインを確認できます。

おわりに
- データ基盤の転送パイプラインの監視する仕組み実装しました。
- 監視用のパイプラインもデータ基盤の転送パイプラインと同じくAirflowのDAGとして追加し、Cloud Composerで管理しています。
- 「テーブルが空になっているか」、「日次・週次処理が遅れているか」、「データ量は前日と比べて激減(増)したか」などの項目を監視することでデータ基盤の品質担保につながります。
以上、最後まで読んでいただきありがとうございました。
Architectグループでは一緒に働く仲間を募集しています。