はじめに
研究開発部の今井海人です。
普段は画像復元や画像の品質評価といった分野に携わっています。
今年はVision-Language Model(VLM)の発展が特筆すべきトレンドだったかと思います。特にGPT-4Vの登場により、画像品質評価におけるアプローチも大きく変わる可能性が示唆されています。最新のベンチマークにおいて、GPT-4Vが人間の画像品質評価に匹敵するほどの精度に到達しており、新時代の幕開けを感じさせます。この記事では、画像品質評価におけるVLMを中心に、いくつかの関連論文をピックアップして紹介していきます。
なお、本記事はSansan Advent Calendar 2023の15日目の記事です。
画像品質評価とは
画像品質評価(Image Quality Assessment, IQA)は、写真や生成画像が人間にとってどの程度好ましいかや、美しいのかを評価することが目的です。例えば、撮影した写真が明るく鮮明であるのかや、生成された画像が本物にどれだけ近いのかということを評価します。しかし、実応用で全ての画像を人手で評価することは、コストの観点で非常に困難です。弊社でも社内のオペレーターさんと協働して、画像補正モデルの品質評価を実施していますが、目視で評価できる枚数には限度があります。
そのため、IQAでは図のように画像ごとの人による評価の平均(Mean Opinion Score, MOS)を収集し、MOSを推定するように深層学習モデルを訓練するアプローチが主流となっています。近年では、MUSIQ[Ke+,ICCV2021]やMANIQA [Yang+, CVPRW2022]といった新しい評価手法が提案されています。

実応用における既存のIQAの課題
既存のIQA手法の多くは、特定のデータセットに対して追加学習を前提にしており、汎化性能という点において課題が存在します。例えば、名刺のような学習データに含まれていないドメインにおいては、性能が著しく低下する傾向にあります。実際に一般的な画像におけるIQAデータセットKonIQ-10Kと、ドキュメント画像品質データセットSCIDを、Zero-shot IQA手法(BRISQUE、 CLIP-IQA、CLIP-IQA++)と最先端の学習済みIQA手法(MANIQA)と比較した結果が下表になります。結果から、MANIQAは学習していないドキュメントデータにおいて、性能が低下していることが分かります。
| Method/Dataset | ↑KonIQ-10K [Hosu+,TIP2020] | ↑SCID[Ni+, ISPACS2017] |
|---|---|---|
| BRISQUE [Mittal+, TIP2012] |
0.3910 | 0.4758 |
| CLIP-IQA [Wang+, AAAI2023] |
0.6890 | 0.5570 |
| CLIP-IQA++ [Imai+, MIRU2023] |
0.8150 | 0.6360 |
| MANIQA [Yang+, CVPRW2022] |
0.8934 | 0.5744 |
このような性能低下を改善するためには、新たなドメインに合わせたデータセットの作成が有効です。しかし、コストやその他の制約からこれが困難な場合も多いです。また、学習に適したデータセットを作成すること自体が難題であり、専門家でない評価者でも画像を適切に評価できるような設計が必要です。このため、画像品質評価においても、高い汎化性能を持つIQA手法が求められています。
CLIPによる画像品質評価
CLIP
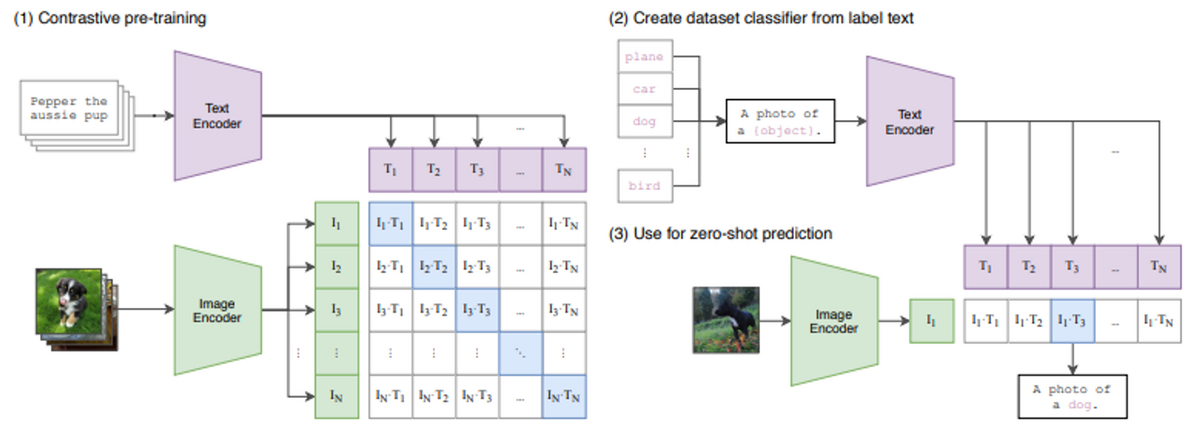
CLIP (Contrastive Language-Image Pre-Training)[Radford+,2021]は、大量のテキストと画像のペアを用いて、テキストと画像の意味的関係を事前学習したモデルです。驚くべきことに、CLIPは新しいタスクに対しても追加学習をせず直接適用(Zero-shot)できます。CLIPの応用範囲は非常に広く、画像生成技術である拡散モデルの学習においては、指定されたテキスト(プロンプト)と生成された画像の類似度を評価する損失関数として使用されています。
{kind=link}
CLIPのプロンプトと画像との類似度は、以下のOpenAIのサンプルコードのように計算できます。サンプルでは、入力としてCLIP構成図の画像と、プロンプトとして「図形、犬、猫」を与え、画像とそれぞれのプロンプトとの類似度を出力します。
import torch import clip from PIL import Image device = "cuda" if torch.cuda.is_available() else "cpu" model, preprocess = clip.load("ViT-B/32", device=device) image = preprocess(Image.open("CLIP.png")).unsqueeze(0).to(device) text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device) with torch.no_grad(): image_features = model.encode_image(image) text_features = model.encode_text(text) logits_per_image, logits_per_text = model(image, text) probs = logits_per_image.softmax(dim=-1).cpu().numpy() print("Label probs:", probs) # prints: [[0.9927937 0.00421068 0.00299572]]
CLIP-IQA
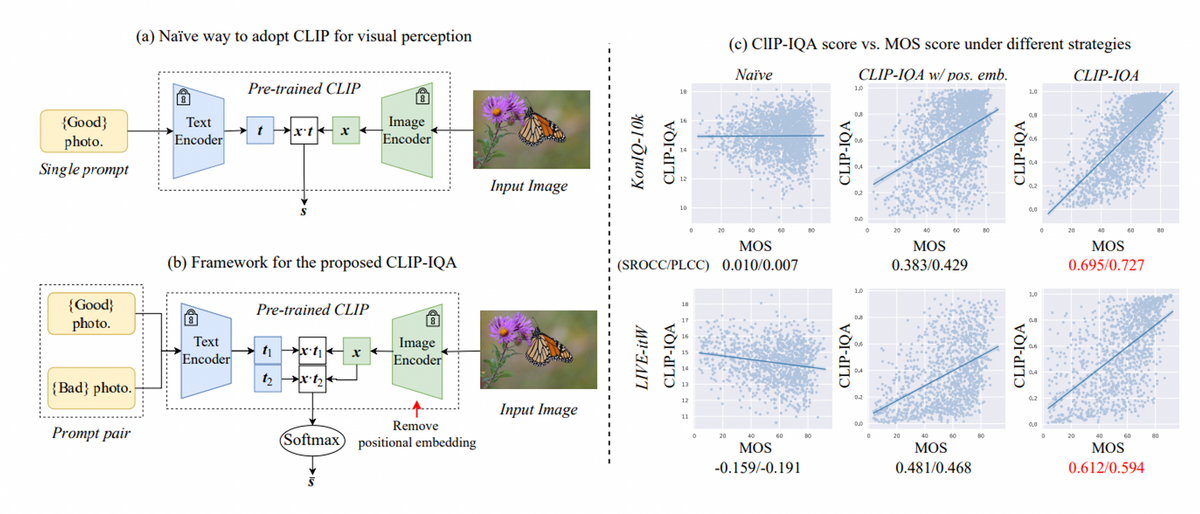
CLIPは優れたZero-shot性能を有していますが、上図のNaiveモデルのように[Good photo]のような曖昧なプロンプトを与えると、人の評価であるMOSと全く一致しないことが分かります。CLIP-IQA[Wang+, AAAI 2023]は、この問題に対して、対義語のペアプロンプト[Good photo. ,Bad photo.]を用いることでプロンプトの曖昧さを低減しました。また、CLIPは入力を224x224にリサイズする必要があるため、推論時の画像品質に影響を与えています。CLIP-IQAは、CLIPモデルのAttentionPool2dからpositional embedding(位置情報を組み込む要素)を取り除き、任意の解像度の画像を入力できるように改善しました。
Zero-shot性能においてIQA特化の最先端手法には及ばないものの、特殊なドメインや生成画像の品質評価において、CLIP-IQAは性能の低下が少なく優れた汎化性能を発揮しています。
また、CLIP-IQAはTorchmetricsから簡単に利用できます。
from torchmetrics.multimodal import CLIPImageQualityAssessmentimport clip import torch image = torch.randint(255, (1, 3, 224, 224)).float() metric = CLIPImageQualityAssessment(prompts=(("Good photo.", "Bad photo."))) metric(image) {'user_defined_0': tensor([0.9652]))}
CLIP-IQA以降のVLM IQA
CLIP-IQAの拡張的な手法
Blind Image Quality Assessment via Vision-Language Correspondence: A Multitask Learning Perspective [Zhang+, CVPR 2023]
LIQE(Language-Image Quality Evaluator)は、Multimodal IQAモデルをマルチタスクで学習する新しいアプローチです。この手法では、画像品質スコアの推定だけでなく、劣化タイプやシーンの推定という異なるタスクを同時に学習することで、最先端の性能を達成しています。CLIP-IQAとは異なり、LIQEは入力プロンプトにシーンや画像の劣化状態を含め、入力画像をランダムなパッチに分割して処理します。
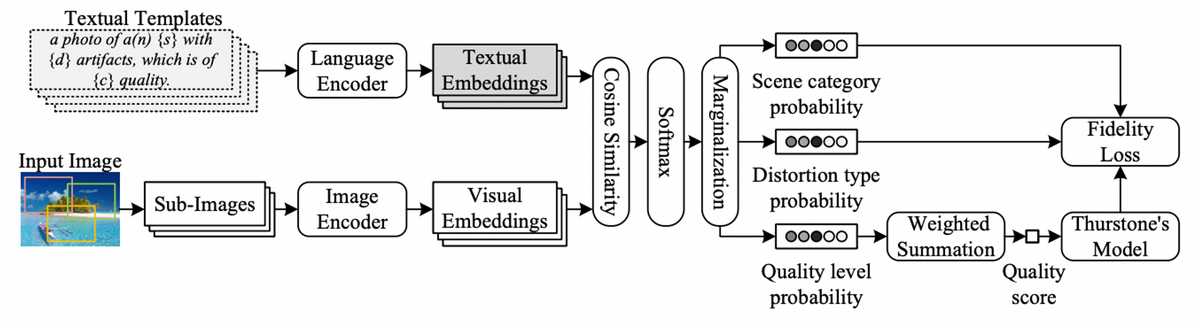
Vision-Language Modelによる局所構造を考慮したFew-shot画像品質評価モデル[Imai+,MIRU2023]
弊社でもCLIP-IQAに関連した論文発表をおこなっております。CLIP-IQAはZero-shot IQA性能が十分でないため、実際の利用シナリオでは追加学習が必要となっています。一方で、ドメインや目的ごとに新たにIQAデータセットを構築することは困難です。そこで、論文では限られた数十枚の学習データから、 Few-shot IQAを実現する手法を提案しています。この手法は、プロンプトの拡張、局所スコアの統合、新たな損失関数の導入を通じて、CLIP-IQAのZero-shotとFew-shot性能を向上させています。
buildersbox.corp-sansan.com
審美評価への適用
審美的画像評価(Image Aesthetics Assessment, IAA)は、画像の劣化(ブラーやノイズ)を評価するのではなく、画像の美しさや魅力を評価するタスクです。
VILA: Learning Image Aesthetics from User Comments with Vision-Language Pretraining[Ke+,CVPR2023]
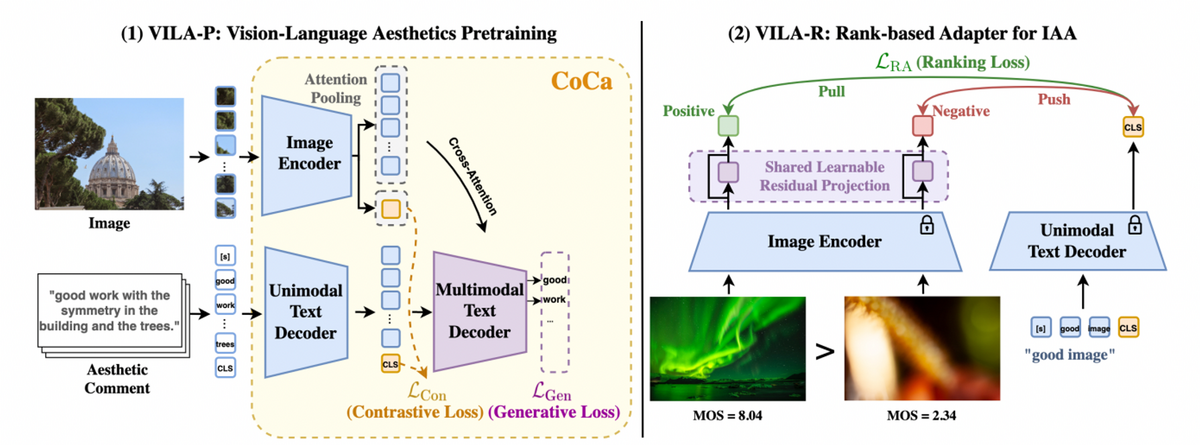
一般的に写真共有プラットフォームでは、投稿された写真に対してユーザーから内容についてのコメントが書かれています。これらのコメントは「very cool patterns and curls」のような形で画像の美的特徴を表現し、学習において有用な情報になります。
VILAのアプローチは、このようなユーザーコメントを活用することに焦点を当てています。VILAはVision-Language(VL)モデルを、CoCa[Yu+, TMLR2022]という手法で事前学習します。CoCaは、画像とそれに対応するコメントの関係性を学習すると同時に、コメント生成も行う手法です。この事前学習により、VILAモデルはマルチモーダル推論とコメント生成を同時に行うことが可能になります。さらに、審美スコアを推定するためのアダプタを追加学習することで、IAAにおいて最先端の性能を達成しています。
Text-to-Imageモデルの評価
Text-to-Image(T2I)モデルの評価は画像の美しさだけでなく、入力プロンプトと生成画像との整合性も重要な評価基準となっています。

TIFA: Accurate and Interpretable Text-to-Image Faithfulness Evaluation with Question Answering[Hu+, ICCV2023]
TIFAは、テキスト入力に忠実な画像を生成するかを評価するための新しい評価指標です。このアプローチでは、テキスト入力を基にして、言語モデルを使用して複数の質問・回答ペアを自動生成します。これらの質問に対して既存のVQAモデルが、生成された画像から質問に答えられるかをチェックします。このプロセスを通じて、生成された画像がテキスト入力にどれだけ忠実であるかを計測できます。TIFAは、特に数の数え上げや複数のオブジェクトの構成に関する評価において、他の評価指標より優れた性能を示しています。
損失関数への応用
MultimodalなIQAは画像の評価だけでなく、既存のlow-level画像復元にも応用されています。
CLIP-LIT:Iterative prompt learning for unsupervised backlit image enhancement[Liang+, ICCV2023]
CLIP-LITは、逆光画像補正における新しい手法です。逆光画像補正は基本的に教師データ取集が困難であり、Unpairedデータで学習されるタスクです。Unpairedデータで学習されたモデルの課題として、汎化性能に低さが挙げられます。CLIP-LITは画像復元モデルと、復元モデルを評価するCLIP-IQAを交互に学習することで、Unpairedな画像補正における性能を向上できることを示しています。詳しくは関東CV勉強会にて発表したスライドをご参照ください。
speakerdeck.com
基盤モデルのIQA性能ベンチマーク:Q-Bench
Q-Bench: A Benchmark for General-Purpose Foundation Models on Low-level Vision[Wu+,arxiv2023]
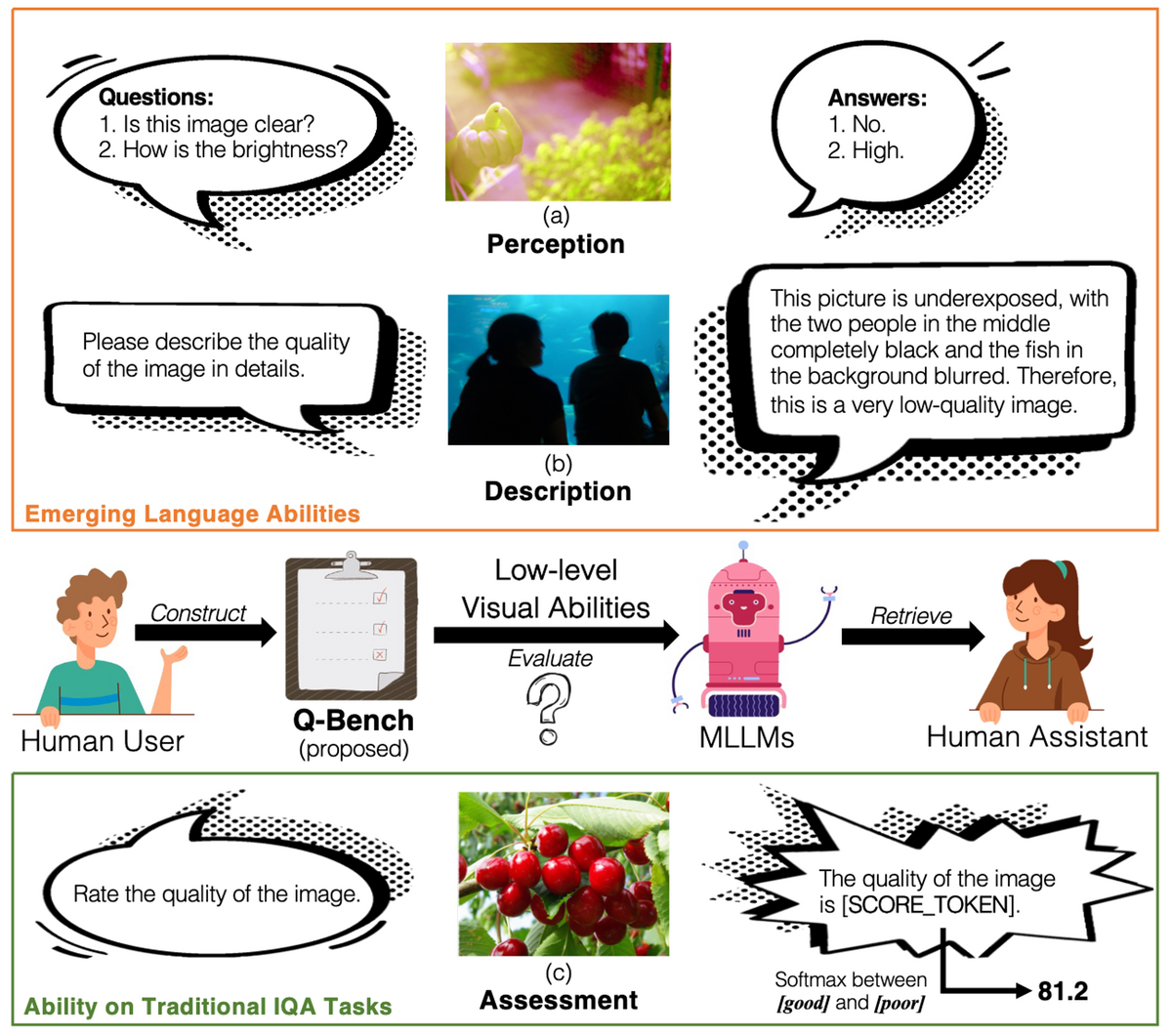
Q-Benchは、マルチモダリティ大規模言語モデル(MLLMs)の画像品質の知覚と理解を評価するベンチマークで、3つのタスクから構成されています。
- A1:視覚知覚能力評価: 2,990枚の画像から成るLLVisionQAデータセットを使用し、MLLMsが画像品質に関する質問にどれだけ正確に答えられるかを測定します。例:劣化が存在するか?, どのような劣化が存在するか?
- A2:情報の記述能力評価: 499枚の画像と画像品質についてキャプションを含むLLDescribeデータセットを用いて、MLLMsが画像の品質を正確に描写できるかを評価します。
- A3:品質評価: MLLMsが定量的な画像品質スコアを予測できるかどうかを測定します。
以下は、タスクA1とタスクA3でのMLLMsとIQAモデルの性能比較です。ここでは、一般人(human-1)、画像評価の訓練を受けた一般人(human-2-senior)、およびIQA手法の性能が示されています。特筆すべきは、GPT-4Vが一般人の画像評価能力に匹敵する性能を示している点です。
| Participant Name | ↑Task A1 overall | ↑Task A3 KonIQ-10K |
|---|---|---|
| MUSIQ | - | 0.8654/0.8958 |
| CLIP-IQA | - | 0.5786/0.6471 |
| mPLUG-Owl (LLaMA-7B) | 0.5538 | 0.4090/0.4270 |
| InternLM-XComposer-VL (InternLM) | 0.6535 | 0.5680/0.6160 |
| GPT-4V | 0.7336 (+0.1142 to best open-source) | - |
| human-1 | 0.7431 (+0.0095 to GPT-4V) | - |
| human-2-senior | 0.8174 (+0.0838 to GPT-4V) | - |
さらに、Q-BenchチームはQ-Instructと呼ばれる追加の200Kインストラクションデータセットと、それによってファインチューニングされたMLLMsを提案しています。このファインチューニングにより、MLLMsの性能はGPT-4Vに近づきつつあります。実際の性能は、対話デモ (Hugging Face)で確認できます。
huggingface.co
まとめ
この記事では、Vision-Language Modelの画像品質評価への応用を中心に紹介しました。従来の一般的な画像評価値を予測するIQA手法から、Q-Benchのように画像の劣化要因を説明するという新しいタスクまで、IQAの分野は大きく進化しています。本記事を通して、画像品質評価の世界に興味を持っていただけたら幸いです。