
こんにちは。 DSOC R&D グループの高橋寛治です。
光陰矢のごとしとはまさにこのことで、気づけば入社して2年が経とうとしています。 今でこそある程度わかってきましたが、入社当初はどこにどんなデータがあり、どのようにアクセスするのかよくわかっていませんでした。
知らないことを知るということは非常に難しく、「それさぁ。早く言ってよ〜」とどこかで聞いたことのあるようなフレーズをぼやくのは簡単なのです。 しかし、そういった事態を避けるために情報を共有しようとしますが、実際には非常に難しく感じます。 何を伝えるべきか選ぶのが難しかったり、伝えても覚えきれなかったりします。 おそらく自分自身も共有できていない情報がたくさんあります。
こういった問題を軽減しR&D グループでの研究開発活動を加速させるために、データアクセスライブラリを作って便利になった話をします。
データがどこにあり、どうやってアクセスするかわからない
SansanではAmazon Web Services を主に利用しています。 DynamoDB や Athena など各種 AWS リソース上にデータが保存されています。
データにアクセスする上でいくつかハードルがあります。 ハードルについていくつか例を挙げます。
- AWS に関する知識がないと聞いてもよくわからない
- SQLやKVSといった概念はわかっていても、AWSサービス名と紐付けて覚えるのが大変
- boto3(AWS SDK for Python)の使い方を覚える必要がある(clientとresourceの違いなど、分析目的にはやや複雑)
- ドキュメントに書かれた内容が、どこに保存されており、いつ書かれた情報かわからない
- ドキュメントの鮮度を保つことが非常に難しい
- ドキュメントやメモの保存場所が散乱しがち(SlackやQiita)
- 接続先情報がまとまっておらず探すのが大変
- 認証情報の利用が難しい
- SSHやAWS Session、SSLなど覚えることが多い
それぞれのハードルに対しては、個人が勉強することで解決されるものや、分析環境提供側の仕組み作りで解決されるものが多いように感じるかもしれません。 しかし、それらすべてを個人の努力で解決しなくてもいいと思います。 また、分析基盤の仕組み作りは工数がかかるため検討する点が増えます。
これらの問題に対して、すぐに用意できてかつ効果が高い方法ということで、ライブラリの開発に至りました。
インポートで利用できるように
まずは利用シーンを決めました。 研究開発において利用可能なデータにPythonから簡単にアクセスできる、としました。
Python を使える人なら誰でも簡単に利用できることを想定して開発を進めました。
ssh の設定ができていれば pip コマンドでインストール可能です。 (もちろん setup.py からもインストールできます。)
README.md には、次のように sshの設定やライブラリの使い方を丁寧に書いています(一部文字列は変更しています)。
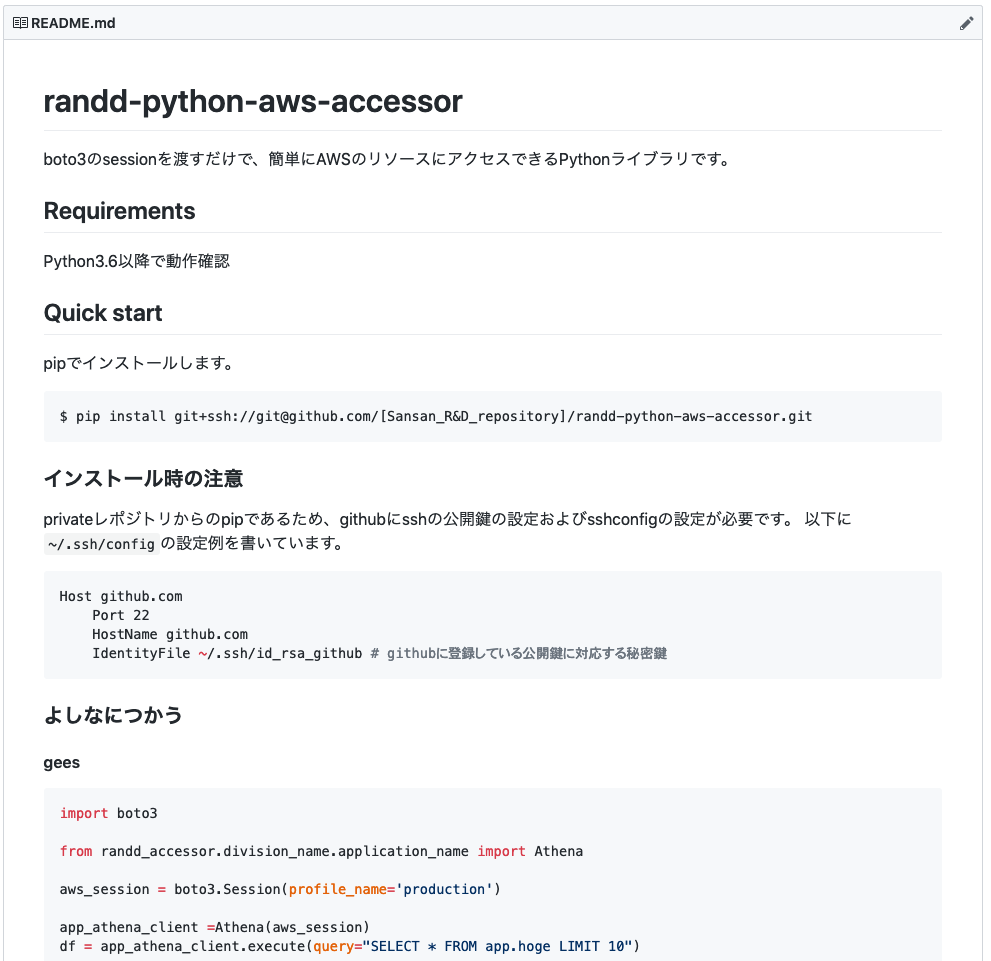
そして大事なことは、 ひたすら布教する ことです。 Slackや定例会で布教したり、サンプルコードでも積極に使ったりと、ひたすら布教活動を行いました。
その結果、使う人が増えてきたことやデータのアクセスについて躓きづらくなってきたことと、私の知らないアクセス先についてクライアントを書いてプルリクエストを出していただけるようになりました。 非常に良い相乗効果のように感じます。 使う人が増えてきた反面のデメリットについては、次節の議論に記します。
ここでは、簡単に実装について紹介します。 方針は、接続情報を簡略化しつつSansan内のデータ仕様に直感的に触れやすいということを主眼に置きました。 ただし余計な機能は付加せず、Boto3で簡単にできることは提供しません。
一番シンプルなものですと、次のように接続情報のみをラップしています。
利用者は、 HogeServiceOnElasticsearch オブジェクトのインスタンス生成時に AWSのセッションを引数で渡すことで利用可能となります。
class HogeServiceOnElasticsearch(elasticsearch.Elasticsearch): def __init__(self, boto3_session): """hogehogeのElasticserchクライアント >>> import boto3 >>> aws_session = boto3.Session() >>> es_client = HogeSeriviceOnElasticsearch(aws_session) >>> response = es_client.search(body={"query": {"match": {"fuga": "value"}}}) """ super().__init__(hosts=["http://hoge"], port=9200, use_ssl=True)
他には、例えば Athena はクエリの結果がS3バケットに保存されるので、それを取得しなければいけません。 毎度コードを書くのが大変であるため、クエリの実行と結果の取得はライブラリ側でカバーしました。 方針は、分析を手軽に実行できるような機能を提供するということです。
議論にあがったこと
ライブラリを開発する際に要望や使い道をメンバーに聞いたのですが、様々な議論がありました。 データアクセスが楽になればいい、というくらいの楽な気持ちで作り始めたのですが、実際使われ出すとソフトウェアとしての課題が露呈してきました。 過去に C# でも同様のデータアクセスライブラリの実装がされていたので、その知見も含まれていました。
- バージョニングの問題
- 共有ライブラリの運用負荷
- 分析用途に限定しているが、結局本番に使われるのではないか
いろいろと話し合った結果、簡単にまとめると次のようになりました。
- 共有ライブラリとして本番に組み込むと時間が経つにつれて運用負荷が増していくため、コードスニペットとして利用する方法を促す
- 依存パッケージの破壊的変更を捉えるためにメジャーバージョンは採番したほうが取り扱いやすい
- 本番で使えるなら使いたいが、メンテし続けるという意思を持って自己責任でやっていく
- なるべく最低限の機能に限定する「入れてしまったものをなくすことはできない」
終わりのない議論ではありますが、R&Dメンバーで認識をすり合わせることで、使われるライブラリになったのではないかと思います。
おわりに
社内データアクセスライブラリを開発して良かったと思います。 実際にデータ分析を行う際に、私はよく利用しています。 そして接続方法を調べる手間が減り作業効率が改善されています。
結局、本番環境では利用していないので大きな問題は起きていないようです。 よく知っていそうな誰かに聞くというのも確かに早いですが、よく知っていそうなライブラリがあるというのも、改めて一つの手段として良かったのではないかと振り返って思います。
執筆者プロフィール
高橋寛治 Sansan株式会社 DSOC (Data Strategy & Operation Center) R&Dグループ研究員
阿南工業高等専門学校卒業後に、長岡技術科学大学に編入学。同大学大学院電気電子情報工学専攻修了。在学中は、自然言語処理の研究に取り組み、解析ツールの開発や機械翻訳に関連する研究を行う。大学院を卒業後、2017年にSansan株式会社に入社。現在はキーワード抽出など自然言語処理を生かした研究に取り組んでいる。