こんにちは。プロダクト開発部の荒川 id:ad-sho-loko です。突然ですが、皆さんはこんな疑問を持ったことはありませんか?
- データベースの内部実装はどうなっているのか?
- トランザクションとはどのようなアルゴリズムで実現されているのか?
- NoSQLが遅いのはなぜか? 古典的なデータベースとは内部的にどのように違うの?
データベースを何かしらの形で利用しているのにも関わらず、意外と内部の仕組みを理解していない場合が多いかと思います。僕もそうです。*1
しかし、エンジニアたるもの、その仕組みを知ることは非常に重要です。僕もデータベースについて勉強しようといくつかの本やサイトを調べていたのですが、なかでもCMU(カーネギーメロン大学)のDatabase System Groupがアップロードしている講義が最も勉強になりました。
そして本ブログでは、上記の講義を参考にして、今回はシンプルなDBMSをGoで実装したのでご紹介します。リポジトリは以下です。
何が学べるか?
まず、簡単に講義内容をご紹介します。公式サイトのシラバスによると以下の記載があります。
This course is on the design and implementation of database management systems. Topics include data models (relational, document, key/value), storage models (n-ary, decomposition), query languages (SQL, stored procedures), storage architectures (heaps, log-structured), indexing (order preserving trees, hash tables), transaction processing (ACID, concurrency control), recovery (logging, checkpoints), query processing (joins, sorting, aggregation, optimization), and parallel architectures (multi-core, distributed). Case studies on open-source and commercial database systems will be used to illustrate these techniques and trade-offs. The course is appropriate for students with strong systems programming skills.
- データモデル(リレーショナルモデル、ドキュメント、key/value)
- ストレージモデル(n-array, decomposition)
- クエリ言語(SQL)
- ストレージアーキテクチャ(ヒープ構造、ログ指向)
- インデックス(btree、ハッシュテーブル)
- トランザクション処理(ACID、並列処理)
- 回復処理(ロギング、チェックポイント)
- クエリ処理(ジョイン、ソート、集約、最適化)
- 並列処理(マルチコア対応、分散DB)
上記に挙げたように、データベースの理論と実装の全般について学ぶことが出来ます。現実のDBMSとの比較を通して解説されるため、非常にイメージが湧きやすいです。内容の網羅性の高さ、深度ともに入門としてはこれ以上無いクオリティだと思います。また事前知識としては、コンピュータサイエンスの基礎が求められます。例えば、仮想記憶の仕組み、mmapなどのシステムコールの基礎知識、アルゴリズムの基礎(B-tree, SkipList)などです。
実装と全体図
さて、講義を参考にして勉強用のDBMSをGoで書くことにしました。その名もbogoDBです。*2 授業を参考に実装したので、それなりに一般的なデータベースの実装に近しい全体像になっているかと思います。もちろん機能やパフォーマンスは明らかに劣りますが。ちなみに、あくまでも勉強用ということで、ひたすら「やるだけ」の実装はなるべく控えるようにしています。なので明らかに非効率な処理を行っている箇所が多数存在しています...
以下にモジュールの全体像を示しました。モジュール別に内容をご紹介します。
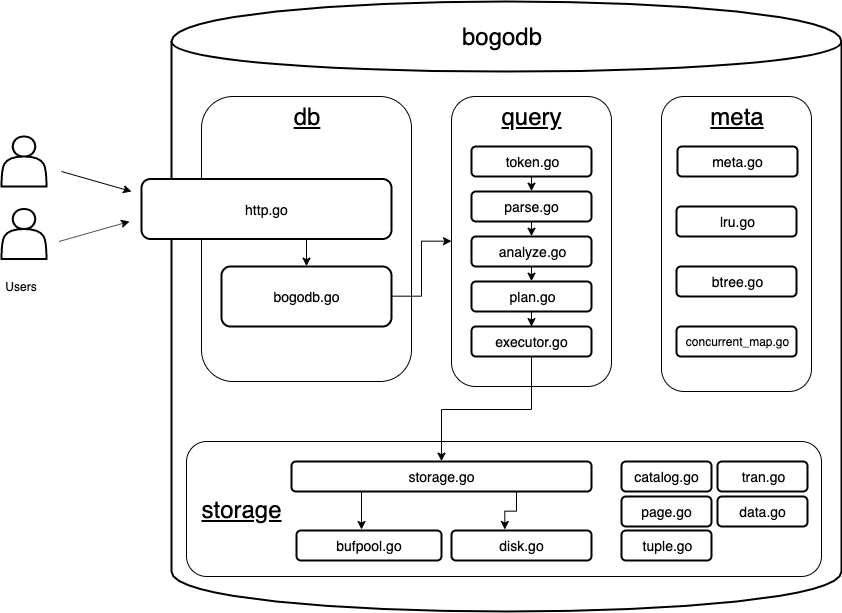
storage
データファイルを扱うモジュールが定義されています。データベースの核心と呼べるのはココでしょう。
まず、データの流れから説明すると、INSERTしたデータはBufferPoolと呼ばれるメモリに保存されます。BufferPoolはLRUキャッシュになっていて、キャッシュが最大まで埋まると参照タイムスタンプが古いものから除去されます。DBの終了処理時、もしくはLRUキャッシュから溢れるタイミングで、ディスクにページと呼ばれる単位ごとに永続化されます。一般的なDBMSでは、これらに加えてチェックポイントと呼ばれる定期的にバッファを永続化する処理があるのですが、今回は実装していません。
そして、ページはOSの仕組みを直接利用せずに、バイナリファイルとして定義しています。それぞれのDBMSごとに思想に沿ったバイナリを定義されるのですが、bogoDBはバイナリへのシリアライズはprotocol bufferにすべて任せています。これをタプルと呼んでいて、ページはタプルが並ぶだけのシンプルな構造ですが、非常に効率の悪いデザインです。授業では効率的なレイアウトが紹介されているのですが、割とやるだけ感が強くて採用するのをやめました。いくつかのDBMSの構造を勉強すると、バイナリとしてデータを扱うことでギリギリまでデータ量を削減する努力を感じることができました。
CREATE TABLEにて、作成されるシステムカタログは永続化のためにjsonを使用しています。例えばテーブルを作成した場合、このjsonファイルにメタ情報が書き込まれます。*3 そして、取り扱えるデータの型はint、string(varchar)のみです。
このモジュールは、抽象化にこだわった設計になっています。例えば、メモリからページを取得したか、ディスクから取得したかを呼び出し側からは意識する必要のない実装になっています。
同時実行制御
同時実行制御はMVCCを採用しています。特にPostgreSQLに似た追記型アーキテクチャとなっています。*4
簡単に仕組みを説明すると、まずトランザクションを作成するたびに独自のID(TXID)が割り振られます。このIDごとにトランザクションの状態(進行中、コミット済み、アボート)を管理しており、挿入時(更新時)にタプルにメタ情報として付与します。例えば、他のトランザクションが進行中のとき、そのトランザクションが挿入したタプルは、他のトランザクションが閲覧できないようにする必要があるのですが、このTXIDとトランザクション状態を見るだけで、隔離性を担保できるようになります。
db
データベースのフロントエンドに該当します。ほかのモジュールとの仲介役をしています。
クライアントとのプロトコルには何も考えずにHTTPを使っています。なのでDBを起動するとHTTPサーバが同時に起動します。クエリに実行したいSQLを設定した上で、リクエストを飛ばすことでクエリを実行できます。*5 当然バリデーションは甘く、オーバヘッドも高いのですが、curlやブラウザから直接叩けるので意外と便利でした。PostgreSQLやMySQLは独自のフロントエンド用のプロトコルが実装されています。
他にもシグナルハンドラを定義して、データベースの終了時にシステムカタログやインデックスなどの永続化処理を行います。
query
クエリ処理を担当するモジュールです。読み込んだSQLをパースして実行エンジンで走らせます。SQLは以下の4つの構文を実装しました。いずれも最小の構文しか実行できません。テストも一応書いていますが、正常系しか試していないのであしからず。
- CREATE TABLE
- INSERT
- BEGIN, COMMIT, ROLLBACK
- SELECT(FROM, WHERE)
パーサは適当に再帰下降構文解析で実装しています。アナライザはパースしたクエリを意味解析し、プランナはスキャン方式を確定させます。Joinを実装できていないので、現時点ではあまり面白みがないです。スキャン方式は2種類選べて、シーケンシャルスキャンとインデックススキャンの2種類を利用できます。またインデックスはbtreeにて構築され、主キーに自動で付与されます。
meta
配置場所に困ったファイルの集まりです。テーブルやカラムを構造体として定義したクラス、btree、LRU、utilityメソッドが格納されています。どれも必要最低限の実装しかしていないです。*6
おわりに
機能としては非常に限られたモノかつ、おもちゃのようなデータベースですが、今後のデータベース学習への取っ掛かりができたような気がしています。間違いなくバグだらけで実用に耐えうるものではないのですが、理論を実装に落とし込むという意味では大変勉強になりました。やはり手を動かして実装してみることは非常に重要ですね。
現時点では実装出来ていないのですが、あとはリカバリ処理(ARIES)まで実装したいですね。みなさんも是非この記事を機会にDBMSを開発してみてください。