3行で
- Sentencepieceの論文概要を説明した。
- 自身のTweetを用いて、SentencepieceとMeCabの分割点の違いを調べた。
- Sentencepieceでは生文から生成された特徴的な分割が見られた。一方、今回のような少ない学習データでは上手く分割できない。
はじめに
Sansan DSOC 研究開発部の齋藤です。
最近Sentencepieceの論文を読む機会があったので、論文の概要説明と、実際に使ってみようと思い立ちました。
前半で論文の説明を行い、後半でSentencepieceの特徴を知るために、MeCabとの比較を行います。 データとして、今回は自分自身のTweetを使いました。
Sentencepieceとは
Sentencepieceは、従来の「文法的に正しい分割」ではなく、学習データである生のテキストから最適な分割点を学習しようという取り組みです。
Taku Kudo et al.(2018)にて解説されています。本論文では、Neural Machine Translation(ニューラル機械翻訳, NMT)での利用を前提としています。NMTとは英語→日本語などの機械翻訳において、ニューラルネットワークを用いる方式を表します。
今回はNMTにおける「語彙数」と「計算量」の問題に着目します。
極端な例を出すと、翻訳の精度を極めるのであれば、世の中にある全ての語彙を学習した翻訳モデルを作れば良いはずです。しかし、語彙数を増やせばモデルの計算量は増えていき、実用に耐えれないことになります。*1
仮に、Google翻訳やDeepLでの翻訳に毎回1時間必要なら、使うユーザーはほぼいなくなることが想像されます。
そこで、NMTにおいては語彙数をある程度に保ちつつ、未知語(学習されていない語彙)に対しても可能な限りカバーしたいというモチベーションが生まれます。 その具体的な手法として、一般的にはsubwordが使われます。
subwordとは
subwordはSennrich et al. (2016)にて発表された手法です。
subwordでは未知語を更に細かい単語へと分割します。例えば、未知語が「言語処理」だと仮定した場合、
「言語 / 処理」
「言 / 語処 / 理」
という区切りの候補を用意し、候補のどれかを使用することで未知語への対応を行うことになります。
仮に「言語 / 処理」という区切りで扱い、既に「言語」「処理」という単語が語彙に含まれている場合、語彙数を維持したまま「言語処理」という未知語に対応できたことになります。
実際に区切りを決定する方針としては、語彙数を減らしつつ幅広い単語をカバーできるかを考えます。その手法として、Sennrich et al.(2016)ではByte Pair Encoding (BPE) の利用が提案されています。
BPEでは、下記の仕組みで圧縮を行なっていきます。
- テキストの圧縮率を指定する。
- 最も細かい文字の分割から、bi-gramの頻度を計算する。
- 高頻度なbi-gramの単語2つを結合する。
- 2,3を繰り返し、指定したテキストの圧縮率になるまで語彙を減らす。
頻度の高いbi-gramから結合することで単語を減らしていき、目標の圧縮率に到達した時点での語彙を利用します。
Sentencepieceでの取り組み
Sentencepieceでは上記subwordの概念に加え、更に単語の分割点の問題を考慮しています。これは日本語など、「分かち書き」が必要な言語特有の問題です。
先ほどの例を再び利用すると、そもそも「言語処理」の単位から始めることが正しくなく、 (例えばですが)「自然言語処理」という単位から始めた方が良い区切りを生み出せるのではないかという考えです。
そこでSentencepieceでは、単語列をベースにどこに区切りを入れるか判断するのではなく、生文を受け取り、単語のどこに分割を入れるべきかを学習し、 語彙数制限に収まるよう分かち書きを生成します。
概要は以上となります。実際には、追加で下記のような点が拡張されています。
- 2つのトークン分割手法を利用(BPE, Unigram language model)
- BPEの高速化
- テキストの可逆分割
より詳細を知りたい場合は元論文や、著者自らが執筆された記事を参照してください。
SentencepieceとMeCabの比較
利用するデータセット
Sentencepieceの学習には、2021/6/10 07:00時点の自身のTwitterアカウントの全Tweet1702件を利用します。reply,RTは除いています。
これは、Sentencepieceの学習において頻度の観点も重要になり、可能な限り似た言葉を使うデータセットを用いたいと考えたためです。 RTは他の人のTweetなので勿論除外です。replyも相手に対して敬語を使った文章になり、自身の呟きとは質が異なるため今回は除外しました。
利用したコード
githubにて公開しています。
Tweetを取得するコードに関しては、下記サイトのものを利用させて頂きました。ありがとうございます。
TwitterAPI でツイートを大量に取得。サーバー側エラーも考慮(pythonで) | コード7区
適当なTweetを分かち書きしてみる
分かち書きが簡単そうなTweet、難しそうなTweetをSentencepieceとMeCabで分かち書きしてみます。
まずは簡単そうなTweetについて。
平和な部屋の中で雨が降っているのをぼーっと眺めることが大好きです
— しんちろ (@sinchir0) 2021年6月3日
このTweetに対して、前処理を行ったものは下記になります。
- MeCab
['平和', 'な', '部屋', 'の', '中', 'で', '雨', 'が', '降っ', 'て', 'いる', 'の', 'を', 'ぼーっと', '眺める', 'こと', 'が', '大好き', 'です']
- Sentencepiece
['平', '和', 'な', '部', '屋', 'の中で', '雨', 'が', '降', 'って', 'いる', 'の', 'を', 'ぼ', 'ー', 'っ', 'と', '眺', 'め', 'る', 'こと', 'が', '大', '好き', 'です']
Sentencepieceでは、「の中で」を一つの単語として扱っているのが、生文から学習した感じがありますね。
次は難しそうな下記Tweetについて
multi stage buildの概念少し理解した。例えばpoetry使ってた場合、docker化した際の環境にはrequirement.txtだけあれば良いからpyproject.toml, poetry.lockは持っていきたくない。そこで、最初にbuildした環境内ではpoetryからrequirement.txtを生成する作業、二つ目ではそれをコピーして利用する
— しんちろ (@sinchir0) 2021年6月7日
- MeCab
['multi', 'stage', 'build', 'の', '概念', '少し', '理解', 'し', 'た', '。', '例えば', 'poetry', '使っ', 'て', 'た', '場合', '、', 'docker', '化', 'し', 'た', '際', 'の', '環境', 'に', 'は', 'requirement', '.', 'txt', 'だけ', 'あれ', 'ば', '良い', 'から', 'pyproject', '.', 'toml', ',', 'poetry', '.', 'lock', 'は', '持っ', 'て', 'いき', 'たく', 'ない', '。', 'そこで', '、', '最初', 'に', 'build', 'し', 'た', '環境', '内', 'で', 'は', 'poetry', 'から', 'requirement', '.', 'txt', 'を', '生成', 'する', '作業', '、', '二つ', '目', 'で', 'は', 'それ', 'を', 'コピー', 'し', 'て', '利用', 'する']
- Sentencepiece
['m', 'u', 'lt', 'i', 'st', 'a', 'g', 'e', 'b', 'u', 'i', 'l', 'd', 'の', '概', '念', '少し', '理解', 'した', '。', '例', 'え', 'ば', 'p', 'o', 'e', 't', 'r', 'y', '使って', 'た', '場合', '、', 'docker', '化', 'した', '際', 'の', '環境', 'には', 're', 'q', 'u', 'i', 're', 'm', 'en', 't', '.', 't', 'x', 't', 'だけ', 'あ', 'れば', '良い', 'から', 'py', 'pr', 'o', 'j', 'e', 'c', 't', '.', 'to', 'ml', ',', 'p', 'o', 'e', 't', 'r', 'y', '.', 'l', 'o', 'c', 'k', 'は', '持', 'って', 'い', 'きた', 'く', 'ない', '。', 'そ', 'こ', 'で', '、', '最', '初', 'に', 'b', 'u', 'i', 'l', 'd', 'した', '環境', '内', 'では', 'p', 'o', 'e', 't', 'r', 'y', 'から', 're', 'q', 'u', 'i', 're', 'm', 'en', 't', '.', 't', 'x', 't', 'を', '生', '成', 'する', '作業', '、', '二', 'つ', '目', 'では', 'それ', 'を', 'コ', 'ピ', 'ー', 'して', '利', '用', 'する']
MeCabは辞書ベースの区切りができているように見えます。
Sentencepieceについて、上記のバーを右側にずらすとdockerという単語が一つのまとまりで登場するのが分かります。dockerは私が比較的よく呟くので学習されていますが、それ以外の単語、特に英語の部分はほぼ初めて呟いた言葉のためうまく分割できていません。学習データ不足感が否めません。
Tweet全部を分かち書きし、頻度順に並べてみる
SentencepieceとMeCabの特性の違いを理解するために、全Tweetをそれぞれの手法で分かち書きし、その頻度上位20単語を確認します。
単語の長さベースで順に見ていきます。
- 単語長さ > 0(制限なし)の場合
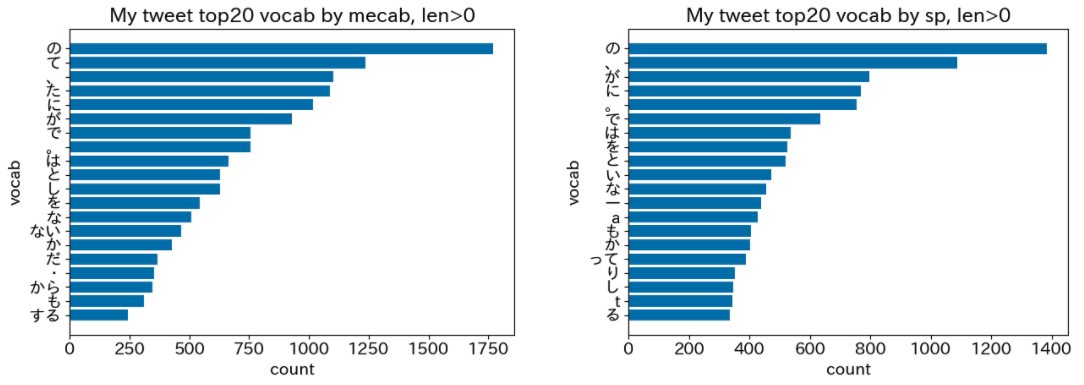
単語長さ > 0(制限なし)の高頻度単語20件
画像は左がMeCabによる分割、右がSentencepieceによる分割です。 Sentecepieceでは、英単語1語(a, t)が一つの単語として扱われている様子が分かります。
- 単語長さ > 1の場合
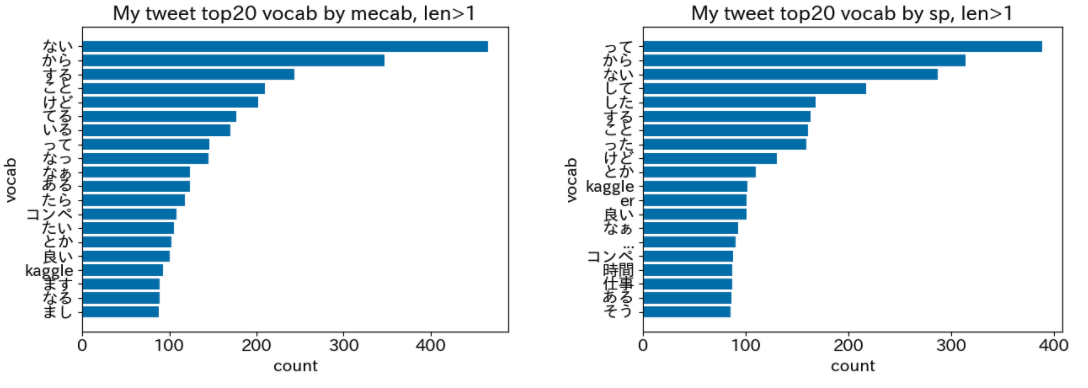
単語長さ > 1の高頻度単語20件
Sentecepieceにおいて、erという単語が上位に来るのはちょっと驚きですね。おそらくKagglerやSIerなどのerが分割されているのだと思われます。
これは余談ですが、私はKaggleが好きなので、Kaggleという単語が登場し始めるのは嬉しいです笑
- 単語長さ > 2の場合
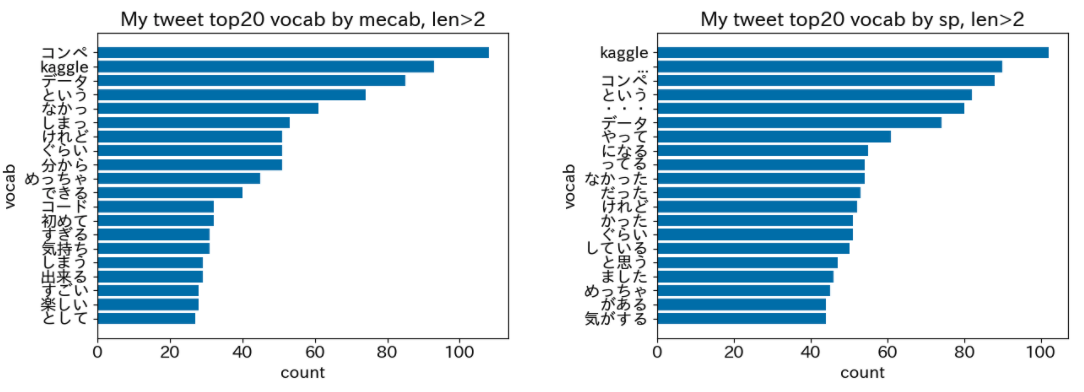
単語長さ > 2の高頻度単語20件
Sentencepieceにおいて、「やって」「になる」「ってる」という単語が登場し始めます。
下記の記事ではSentencepiece × tf-idfによる口癖の分析を行なっていますが、今回の上位単語を見ると普通の辞書には現れない口癖のようなものを確かに取得できそうです。
- 単語長さ > 3の場合
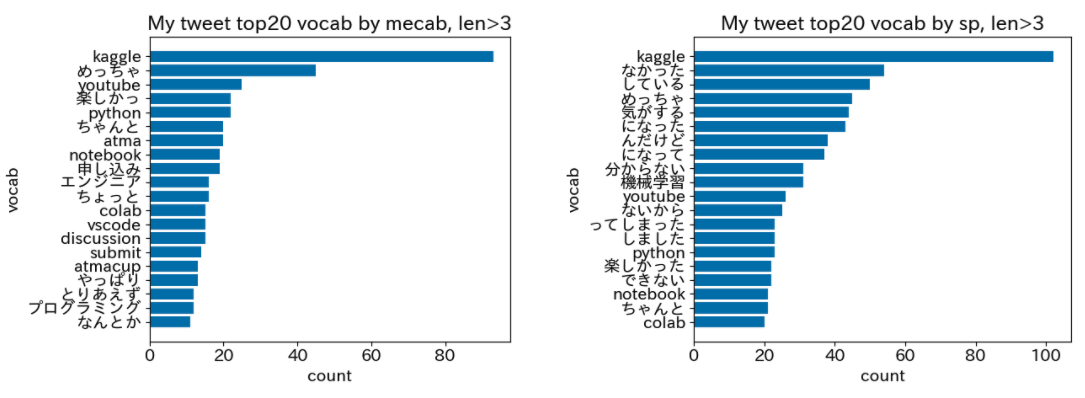
単語長さ > 3の高頻度単語20件
Sentecepieceにおいては、辞書で区切ることができない「になった」「んだけど」「になって」などを取得できていることがわかります。
まとめ
- Sentencepieceは、生のテキストから最適な分割点を学習しようという取り組み
- 辞書ベースのMeCabとは異なる分割点を取得することができている
- 今回のような学習データが少ない状況では、良い感じの分割を得ることはできない
NMTの文脈以外で、Sentencepieceの上手な活用の仕方が思いついたらまた投稿したいと思います。
注釈
*1:全ての語彙を持つデータが存在しないという問題もあります。