
研究開発部 Architectグループ ML PlatformチームのKAZYこと新井です。
名古屋にある中部支店に所属しています。
先日、研究開発部内のEKSクラスタのKubernetesのバージョン更新とその振り返りを行いました。
バージョン更新で起きた出来事と思い出を記します。
【追記】
このエントリの内容をもとに Kubernetes Meetup Tokyo #59 でLTを行いました。
研究開発部へのEKS導入
2022年に研究開発部ではアプリケーション基盤としてEKS(Circuitと呼んでいます)を導入しました。
現在50~100程度のPodが動いています。
以前のエントリーで導入の経緯や周辺技術選定、運用設計について詳しく掘り下げています。
バージョン更新概要
Kubernetesのバージョン
- 1.22→1.24
バージョン更新方法
その他
- アドオン各種のバージョン更新
振り返り
ML Platfromチームの3人で振り返りを行いました。
時系列でイベントをボードに書き出し、特に印象深いものに対して天気(🌞と🌧)を付けました。 天気マークが多く集まったイベントに対してより深ぼって話をしました。
こちらが実際に使ったボードです。
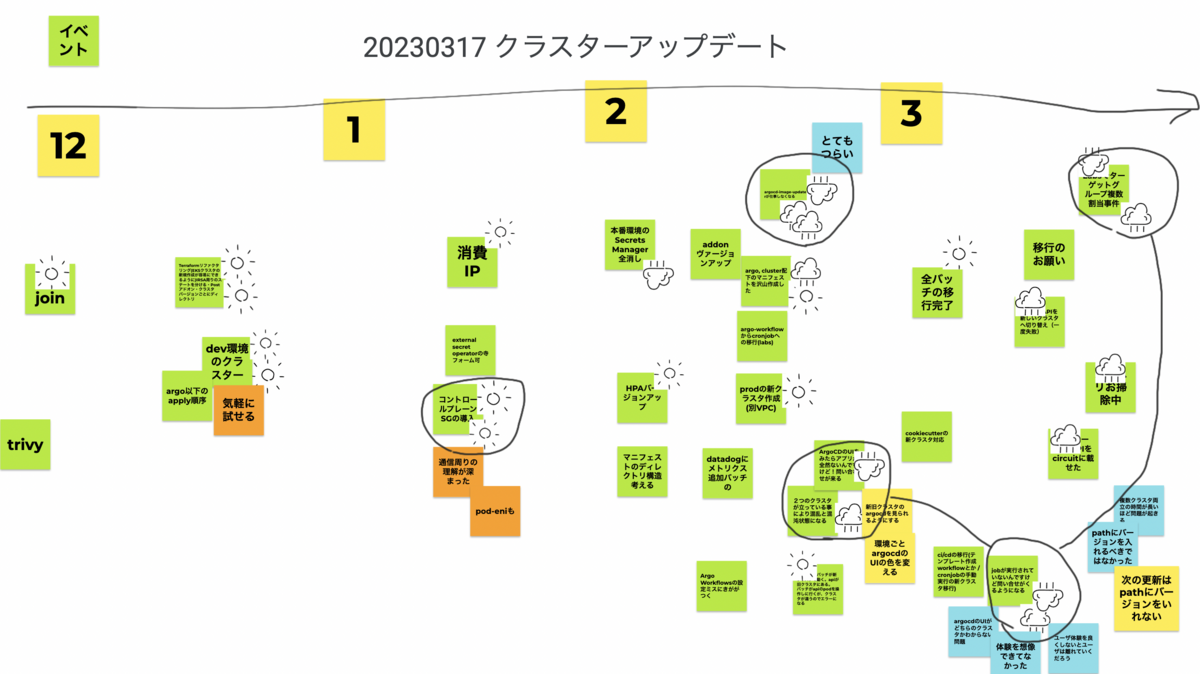
以降で振り返りに上がった話題からいくつかピックアップします。
🌞 Terraformコードのリファクタリング
Terraformを用いて、EKSクラスタ、アドオン、および一部のKubernetesリソースを作成していました。しかし、既存のクラスターと同じ構成で新しいクラスターをTerraformで適用しようとすると失敗してしまう状況が発生していました。これは、リソースをクラスタに順次追加していたことで、予期せぬ依存関係が生じたためです。
具体的には、クラスタとアドオンがインストールされた後でなければ存在しないCRDをTerraformで作成しているケースがありました。クラスタ移行を始める前に、この問題を解決しました。リソースの依存関係を整理し、適宜ステートを分けるなどして新しいクラスタをエラーなく作成できるように改善しました。
事前に時間をかけて依存関係の整理や問題解決に取り組んでいたため、クラスターのバージョン更新に集中できました。これにより、効率的に作業を進めることができたと言えるでしょう。
🌞 クラスタに追加のセキュリティグループを導入
クラスタのバージョン更新ごとにSecurityGroupPolicyのマニフェストを書き換える必要がありましたが、セキュリティグループを追加することで解消しました。詳細については別のエントリーで説明しているため、ここでは割愛します。この改善により、運用がより効率的になりました。
🌞 クラスタ設計の理解
新しいクラスタの作成はチームメンバーにとって非常に重要な学習機会となりました。既に導入しているアドオンやリソースについて、改めて考えるきっかけとなったからです。「これはなぜ必要?」という会話が多くできたことが非常に良い経験となりました。これにより、チーム全体の理解が深まりました。
🌧 クラスタ移行中のArgoCDのWeb UI
ArgoCDのWeb UIを使って、利用者がデプロイ状況を確認できるようにしていましたが、同時に二つのクラスタの情報を表示する準備ができていませんでした。クラスタ移行中は、片方のクラスタの情報しかWeb UIで見られず、UIをホスティングしていないクラスタにデプロイを行うと、サービスが正常にデプロイされていないように見えてしまいます。これにより、利用者からいくつかの問い合わせがあり、不便をかけてしまいました。
今後の改善策として、以下のようなことが考えられます。
- クラスタの移行を短い期間で完了させ、利用者が移行を意識しなくても済むようにする。
- ArgoCDを各クラスタにインストールするのではなく、一つのインスタンスで対応できるようにする。
- 移行前と移行後のUIに利用者がアクセスできるようにして、デプロイ状況の確認を容易にする。
これらの改善策を実施することで、利用者の不便を軽減し、よりスムーズな運用ができるようにしていきたいです。
🌧 一度に多数のアプリケーション作成でArgoCDがメモリ不足
Circuitでは、ArgoCDを使用してマニフェストの宣言的管理とデプロイを効率的に行っています。しかし、クラスタ移行作業中に約10個のアプリケーションを一気に作成したところ、ArgoCDのapplication controllerがメモリ不足(OOM)を起こし、更新ができなくなる問題が発生しました。
この問題は、application controllerがOOMを起こして終了し、再起動を繰り返すことでリソース作成が行われず、アプリケーションのPodが立ち上がらない現象を引き起こしました。原因となったapplication controllerは、0.5vCPUメモリ1GBのFargate Podで動作していました。
実は過去にも同じことが起きていて、この時は0.25vCPUメモリ0.5GBから0.5vCPUメモリ1GBに変更しました。この度の事態を受け、Podのサイズを再び増加*1させることで問題を解決することができました。
今回の経験から、ArgoCDを使用する際には、アプリケーションの作成数やリソース使用量に注意し、適切なサイズのPodを使用することが重要であることが分かりました。今後はこのような問題が再発しないよう、運用方法やリソース割り当てについて検討し、継続的な改善を行っていく予定です。
🌧 クラスタ移行中のアプリケーションデプロイ先
クラスタ移行中に利用者が新旧どちらのクラスタにアプリケーションをデプロイすべきか迷ってしまう問題が発生し、誤って意図していないクラスタにデプロイしてしまう事態がありました。
これを防ぐために、クラスタ移行中であっても利用者がクラスタを意識せずにデプロイできる方法や、デプロイすべきでないクラスタにデプロイできないようにする工夫が求められます。
🌧 本番環境のVPC移行
本番環境のみVPC移行が必要となり、元々の計画であった、同じALBを使ったターゲットグループでトラフィックの向き先を変える方法が使えなくなりました。この状況に対処するため、Route 53の加重ルーティング機能を用いて、ダウンタイムなくトラフィックを移行させることができました。これにより、VPCの変更による影響を最小限に抑えることができ、サービスの継続性を確保できました。
🌧 TargetGroupBinding複数作成事件
TargetGroupBindingというリソースを用いてServiceとAWSのターゲットグループ(とその先にあるALB)を紐付けています。
TargetGroupBinding - AWS Load Balancer Controller
クラスタの移行では、クラスタ間で異なるターゲットグループを紐付けて、加重を切り替えることを想定していました。
しかし、新旧クラスタで作成したTargetGroupBindingを手違いで同じターゲットグループに紐付けてしまいました。
TargetGroupBindingは互いに排他的な挙動をするため、自身の管理していないPodがターゲットグループに紐づくと、TargetGroupBindingはそのPodを登録解除してしまいます。そのため2つのTargetGroupBindingリソースがPodを消し合う挙動をしてしまいました。 問題なく動いているPodがターゲットから現れたり消えたりする挙動に対しての原因究明に時間を要しました。
🌧 Secrets Manager全削除事件
CircuitではExternal Secrets Operatorを用いて、マニフェストに直接機密情報を記述することを回避しています。 機密情報はAWSのSecrets Manager経由でクラスタに読み込まれます。
上記のTerraformのリファクタリングの一環でクラスタを作ったり壊したりしていたのですが、操作ミスで本番環境のEKSクラスタで使うSecrets Managerリソースを全て削除してしまいました。
クラスタ内に機密情報が残っていたため、事なきを得ましたが青ざめました。
詳細は別エントリーにしようと思います。
おわりに
ブログを書いているうちに、EKSで1.26が使えるようになってしまいました。
2回目の更新が終わったらまた振り返りエントリーを書こうと思います。
求人
私の所属するML Platformチームを含む、研究開発部Architectグループでは一緒に働く仲間を募集しています。
R&D MLOps/DevOpsエンジニア / Sansan株式会社
*1:一時的に0.5vCPUメモリ4GB