Sansan Engineering Unit Infrastructure グループの落合と申します。
こちらのSansan Tech Blogは初投稿となります。
コロナ禍以降、カンファレンスはオンラインで見られるのが普通になり海外イベントに現地参加することはもうなくなるのだろうな、とばかり思っていましたが、意外にも今年のAWS re:Invent 2023に参加する機会をいただきました。
今回はre:Inventでの発表の中で一番気になった、Amazon Aurora Limitless Databaseの紹介をします。
Keynoteでの発表
re:Invent2023最初のKeynoteであるMonday Night Live with Peter DeSantisの中で、最初に発表になった新サービスがAmazon Aurora Limitless Databaseです。

Keynoteでの発表を聞く限りでは、データ量や性能が厳しくなってきても自動で複数のDBに分割してスケールアウトし、使う側からは複数DBを意識することなく今まで通り1個のDBとしてアクセスするだけで良い、という夢の様なサービスに聞こえました。もし本当ならすごいのですが、過去にPostgreSQLの分散DB化の格闘(Postgres-XC とか、RitaDBとか……)を聞いていた限りそんなうまくいくとは思えない、と懐疑的な目で見てしまいます。詳しいところが知りたい。
セッション: Achieving scale with Amazon Aurora Limitless Database
セッションの内容
Break out Sessionでより具体的な話を聞くことができました。
感想としては、「夢の分散DBというよりは、shardingにフォーカスした機能になっていて想像以上に現実的」という印象です。基本、Aurora Limitless Databaseはshardingを楽に実現できるDBと考えれば良いでしょう。
簡単に説明すると以下のようになります
- shardingしたいテーブルはsharded tableと呼ぶ
- テーブル作成時の設定でshardedのマークをつける
- 設定でshardingするときのkeyを指定する
- 裏で自動的に複数のDBに分散してくれる
- 物理的な配置やデータが増えたときの再配置は、使う側は意識しなくて良い
- shardedなテーブルにjoinするマスター系のテーブルはreferenceと呼ぶ
- テーブルにreferenceマークをつけておく
- 全DBに同じ内容がコピーされて配置される
夢のようなDBではないですがshardingを楽に実現できる点ではとても実用的と言えます。
分散DBとしての特性
アーキテクチャ
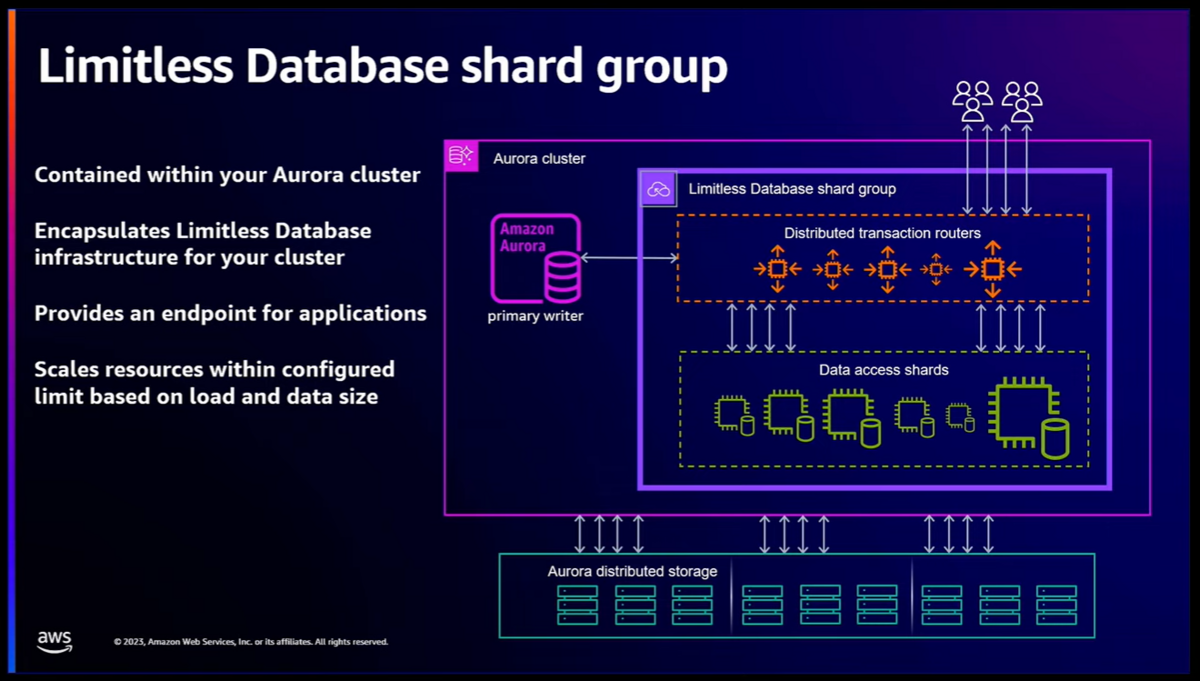
通常のAuroraのinstanceを2層に分離しています。
- Distributed transaction router
- クエリをshardごとに分割してData access shardsに投げる
- 結果を取りまとめて返す
- Data access shards
- shardごとのクエリを実行する
DB利用者は1個のEndpointにアクセスすれば良く、規模に応じてDistributed transaction routerもData access shardsもスケールアウトしていきます。
timeベースのtransaction管理

Keynoteで時間を取って強調されていたのですが、timeベースのtransaction管理を行っていて、どこか一か所にtransaction管理が集中することがなくスケーラブルとなっています。
NITRO対応のEC2ではマイクロセカンド精度の時刻同期を実現していて、timeベースのtransaction管理が実現できているとのこと。*1
Isolation levelは通常のPostgreSQLと同等のREAD COMMITEDとREPEATABLE READをサポートしています。
原理的には、Postgres-XCでのGTM(Global transaction Manager) *2 のように集中的にtransaction管理をする方法にくらべてボトルネックになりづらく、Aurora Limitless Databaseの方法が優れているように見えますが、この当たりは門外漢のため何とも言えません。
Q&A
注目度が高いためか、Q&Aが活発になされていました。気になった質問を書いておきます。
partitionが使えないのは、用途によっては大きな制約になりそうです。
- reference tableは、sharded tableと同じくtime based MVCCなのか
- Yes、全体がtime based MVCCになる
- データ移行はどうするのか
- Auroraのツールが使える
- sharded tableに並列でpumpするツールを準備する予定
- reference tableは複数DBに配置されるが、更新はatomicに行われるのか?
- Yes
- partitionは使えるのか
- shardはpartitionで実現しているので、parttionは使用できない
- partitionを使用するuse caseがあるのか議論してきた。Use caseを教えてほしい。
- shard分割時のDB負荷は?
- 影響はある
- ギリギリになる前に分割を計画すべき
- スケールアウトとスケールアップを同時に行えるのか
- まずはスケールアップして、それで対応できなくなってからスケールアウトするのが良いのでは
- shardingに分割されたDBにglobalなindexは可能か?
- indexは個別DBローカルとなる
考察
このAmazon Aurora Limitless Databaseの発表を見て、思ったこと、気になったことを書きます。
実用性は高いと思われる
上に書いたようにKeynoteを見て勝手に夢を膨らませていたのですが、実際はshardingに的を絞っていて利用者が意識することなくshardingできるように工夫してあり、実用性が高く感じています。
特に当社のようなB2B(法人向け) SaaSではテナントをまたがったクエリは原則不要(むしろさせない)で、巨大なテーブルでもテナントごとにsharding分割すれば十分小さくなることから、shardingがアプリの作りこみなく透過的に実現できるのは魅力的です。
実際、私の所属するチームで管理しているDBではshardingをしていますが*3、Aurora Limitless Databaseの仕組みは適合性が高そうです。
- データをテナントIDでshardingしてDBを分散(sharded table相当)
- 一部のテナント共通的なデータは共通DBに格納(reference table相当)
Aurora Limitless Databaseはshard横断の検索をいかに分散して高速かつtransaction分離レベルも保って実現するのか工夫が多くみられますが、自分たちではshard横断で使う用途がまずないのでさみしい気もしつつその分バグを踏む機会が減るので安心して使えそうです。
Azure Cosmos DB for PostgreSQL対抗
Amazon Aurora Limitless DatabaseはAzure Cosmos DB for PostgreSQLの対抗で出してきたものと想像しています。
Azure Cosmos DB for PostgreSQLはMicrosoftが2019年に買収したCitus Dataが開発しているPostgreSQL拡張のCitusがベースとなっています。
Citusは製品やオープンソースとして実績があり、またCitus DataにはPostgreSQLコミッターが複数所属していることからサービスの内容や継続性には信頼感はあります(私は触ったことがないので残念ながら中身のことは何も言えません)。
一方、Amazon Aurora Limitless Databaseは発表されたばかりで、AWSがLimitless Databaseを拡張続けてサービスを継続していくのか、全くの未知数です。サービスの売れ行き次第なのでしょうが、本格的な採用の前にしばらく見守ったほうがよさそうに感じます。
メリット、デメリット
私が感じたAurora Limitless Databaseのメリット・デメリットを記載します。
メリット
- プログラムの作りこみなし
- これから新規に作るサービス、あるいはまだsharding対応していないならメリット大きい
- スケールアウト、rebalanceが自動でできる
- DBのデータ再分割は非常に手間がかかるため、DBにお任せできるのはとてもうれしい
デメリット
- Aurora Limitless Databaseにロックインになる
- どこまでAWSが力を入れて取り組みメンテし続けるのか、現時点ではまだわからないので様子見
- 対応するextensionが少ない
- 使用しているextensionが対応していないと移行できない
- 利用者が多いextensionは順次対応すると思われるが、いつ対応になるのかはわからない
- partitionが使えない
- partitionを使っていないなら問題ない
- 年月でpartitionを作って保持期間が過ぎたらpartitionごと削除、というような使い方を良く見かけるが、こういった場合は使えない
自分たちでAurora Limitless Databaseを採用するかどうかといえば、当面は使うことはなさそうに思いました。
機能としては魅力ではあり、特にshardのスケールアウトとrebalanceを自動でやってくれるのは非常にうれしいのですが、既に独自のプログラム作りこみでshardingを実現しているためそのロジックを消してまで採用する必要性は感じませんでした。
おわりに
AWSのイベントre:Invent 2023に参加して聞いた中で一番興味を持ったAmazon Aurora Limitless Databaseの概要を紹介しました。システムの発展期でDBの性能がそろそろ厳しくなってきた、というような状況なら適合度が高いサービスです。ぜひ参考にしてもらえればと思います。
また、個人的には分散DBの夢を掘り起こしてくれたので、興味深くBlog記事を書くことができました。久々にこういう技術的な刺激を受けるのも良いものですね。
*1: re:Invent2023直前にAmazon time Sync Serviceの機能追加リリースがありました。https://aws.amazon.com/jp/about-aws/whats-new/2023/11/amazon-time-sync-service-microsecond-accurate-time/
*2: Postgres-XCの参考資料: https://postgres-x2.github.io/presentation_docs/2014-07-PGXC-Implementation/pgxc.pdf
*3: 参考: Sansanにおけるインフラから見たRDBMSの運用/Operation of RDBMS as seen from infrastructure in Sansan - Speaker Deck