こんにちは、Eight Engineering Unitの井上です。
Eightのデータ抽出基盤である Data Management Platform(以下、DMP)の開発を担当しています。
はじめに
Eightは330万人を超えるユーザーにご利用いただいており、お預かりしているデータ量も日々多くなっています。
データが多いことに加えて抽出条件もさまざまなため、データアクセスは基本的にフルスキャンとなり高い負荷がかかります。
負荷は高いのですが頻度は高くないこともあり、DMPではサーバーレスのGlueとAthenaを利用して低コストで安定した稼動となる構成を採用しました。
ざっくりとしたシステム構成は以下になります。
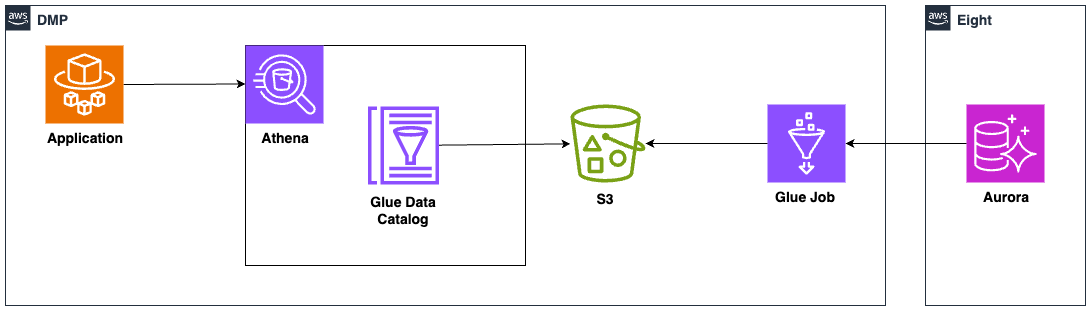
- Glue JobでEightデータをS3へエクスポート
- エクスポートしたファイルはGlue Data Catalogでテーブル定義
- アプリケーションからAthenaへクエリを投げてデータ抽出
この記事では Athena のデータソースを用意するGlueの開発で工夫した点をご紹介します。
工夫①: Blue/Greenのデータ更新
エクスポートするEightデータの大半はデイリー更新で良いのですが、退会やオプトアウトなど高頻度で更新が必要なデータもあります。
Glue Job(PySpark)は分散処理フレームワークのため、データ量や並列数に応じて出力されるファイルが複数になります。
そのため洗い替えでデータ更新するには今あるファイルを全て削除してから新しく作り直す必要があり、一時的にファイルが存在しない状態が発生してしまいます。
ファイルが存在しない状態とデータ抽出が重なると予期せぬ挙動となってしまうため、以下のような実装でダウンタイムなしのデータ更新を実現しています。
from awsglue.context import GlueContext from pyspark.context import SparkContext import boto3 import re # Blue/Greenデータ更新の流れ # ① DataCatalogのテーブル情報から現在のLocationを取得 # ② 現在のLocationが blue か green かを判定 # ③ 次のLocationのディレクトリにParquetファイルを書き込み(データアクスセスが高速になる列指向データファイル形式) # ④ 次のLocationでDataCatalogを更新 def replace_table_data_location(database_name, table_name, dynamic_frame): glue_client = boto3.client("glue", "ap-northeast-1") base_table_location = f"s3://dummy-s3-bucket/schemas/{table_name}/" # ① table_catalog = glue_client.get_table(DatabaseName=database_name, Name=table_name) current_table_location = table_catalog["Table"]["StorageDescriptor"]["Location"] # ② match_result = re.match(r"{}(?P<pattern>\w+)".format(base_table_location), current_table_location) pattern = match_result.group("pattern") if match_result else "" # ③ next_table_location = base_table_location + ("green" if pattern == "blue" else "blue") dynamic_frame.toDF().write.mode("overwrite").format("parquet").save(next_table_location) # ④ # Locationのみの更新ができないため、他のテーブル情報もtable_inputに含める table_input = { key: value for key, value in table_catalog["Table"].items() if key in ["Name", "Owner", "Retention", "StorageDescriptor", "PartitionKeys", "TableType", "Parameters"] } table_input["StorageDescriptor"]["Location"] = next_table_location glue_client.update_table(DatabaseName="hoge_database", TableInput=table_input, SkipArchive=True) # main処理 glue_context = GlueContext(SparkContext.getOrCreate()) dynamic_frame = glue_context.create_dynamic_frame.from_catalog(database="hoge_database", table_name="fuga_table") # データ抽出で扱いやすくするための加工処理など ... # Blue/Greenデータ更新 replace_table_data_location("hoge_database", "fuga_table", dynamic_frame)
工夫②: 共通化
Glue Job間で共通化したい関数を別ファイルに切り出し、 --extra-py-files として再利用しています。
①のデータ更新処理はダウンタイムの解消以外に、障害耐性を上げるメリットもあるためデイリー更新のデータにも適用しています。
Terraformでの定義は以下になります。
resource "aws_s3_object" "replace_table_data_location" { bucket = "dummy-s3-bucket" key = "libs/replace_table_data_location" source = "libs/replace_table_data_location.py" source_hash = filemd5("libs/replace_table_data_location.py") } resource "aws_s3_object" "dmp_glue_job_script" { bucket = "dummy-s3-bucket" key = "scripts/dmp_glue_job" source = "scripts/dmp_glue_job.py" source_hash = filemd5("scripts/dmp_glue_job.py") } resource "aws_glue_job" "dmp_glue_job" { name = "dmp-glue-job" default_arguments = { "--job-language" = "python" "--enable-glue-datacatalog" = "true" "--extra-py-files" = "s3://${aws_s3_object.replace_table_data_location.bucket}/${aws_s3_object.replace_table_data_location.key}" } command { script_location = "s3://${aws_s3_object.dmp_glue_job_script.bucket}/${aws_s3_object.dmp_glue_job_script.key}" python_version = "3" } }
--extra-py-files は script_location と同一ディレクトリに配置されるため、以下のようにimportすることができます
from replace_table_data_location import replace_table_data_location
おまけ
Terraformでテーブル定義していると location の切り替えによる差分が出てしまいます。
そこで 該当テーブルの location は ignore_changes で無視します。
resource "aws_glue_catalog_table" "fuga_table" { database_name = "hoge_database" name = "fuga_table" ... # 細かいパラメータは省略 storage_descriptor { location = "s3://dummy-s3-bucket/schemas/fuga_table/blue" # or s3://dmp_s3_bucket/schemas/fuga_table/green ... } lifecycle { ignore_changes = [ storage_descriptor[0].location, # locationで差分が発生しても無視する ] } }
最後に
今回はGlueを利用する開発のTipsを紹介しました。
Eightではこのような分散処理の開発もあり、Web開発とはまた違った知見も得られます。
もしご興味ありましたらエントリーをお待ちしております!
