
R&D Architectグループの辻田です。SBB*1 2回目の登場です。
今回は【R&D DevOps通信】連載の5回目として、Kinesis Data Firehoseを使用したログのETL処理について書こうと思います。
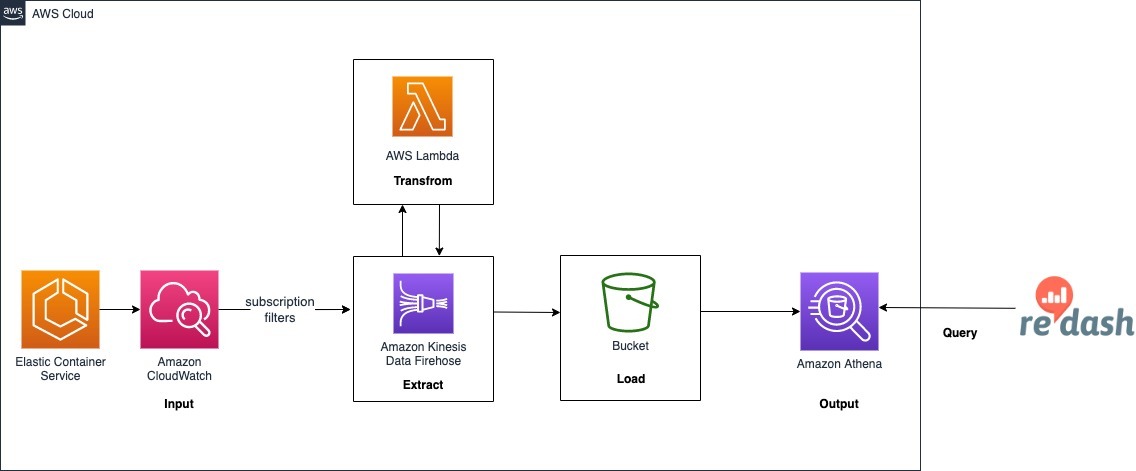
CloudWatch Logsサブスクリプションフィルタ + Kinesis Data Firehose + Lambdaを使用してログをETL処理し、S3へ出力したデータをAthenaテーブルに読み込み、Redashからクエリできるような仕組みです。これらのリソースをTerraformで構築する方法を紹介していきます。
背景
R&Dで運用しているとあるバッチにて、実行後にサーバ上のログファイルから必要なデータのみをスクリプトでcsvに抽出し、それをクラウド上に配置し他部署に共有するという運用を行っているものがありました。
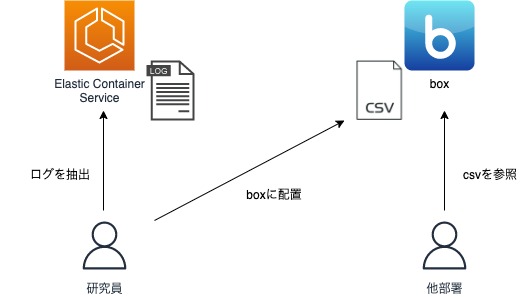
この手動運用を自動化し、他部署の人がログを参照する際の検索性も向上させて一連の運用フローを改善するため、今回の仕組みを作ることになりました。
全体像
最終的なアーキテクチャは以下のようになります。
サブスクリプションフィルタ
CloudWatch Logsのサブスクリプションフィルタを作成し、フィルターパターンと一致するログをリアルタイムにKinesisに配信するようにします。
ロググループごとに最大2つのサブスクリプションフィルタを関連付けることができます。
まずはフィルターしたログを配信先に配信するための権限を付与するIAMロールを作成します。
resource "aws_iam_role" "subscription_filter_role" { name = "subscription-filter-role" assume_role_policy = data.aws_iam_policy_document.logs_assume_role_policy_document.json } data "aws_iam_policy_document" "logs_assume_role_policy_document" { statement { effect = "Allow" actions = ["sts:AssumeRole"] principals { type = "Service" identifiers = ["logs.${var.region_name}.amazonaws.com"] } } } resource "aws_iam_role_policy" "subscription_filter_policy" { name = "${aws_iam_role.subscription_filter_role.name}-policy" role = aws_iam_role.subscription_filter_role.id policy = data.aws_iam_policy_document.subscription_filter_policy_document.json } data "aws_iam_policy_document" "subscription_filter_policy_document" { statement { actions = [ "firehose:PutRecord", "firehose:PutRecordBatch" ] resources = [ var.kinesis_stream_arn ] } }
Kinesisにログを配信するためにサブスクリプションフィルタのIAMロールに firehose:PutRecord と firehose:PutRecordBatch の権限を付与しています。
次にサブスクリプションフィルタを作成します。
resource "aws_cloudwatch_log_subscription_filter" "test_logfilter" { name = "test_logfilter" role_arn = aws_iam_role.subscription_filter_role.arn log_group_name = "example" filter_pattern = "filter pattern" destination_arn = var.kinesis_stream_arn }
ポイントは以下です。
filter_patternにはフィルターしたい語句を指定しますdestination_arnには配信先リソースのARNの指定します。Kinesis Data Stream、Kinesis Data Firehose、Lambda が選択可能で、今回はKinesis Data Firehoseを指定しています。
Kinesis Data Firehose
続いてKinesis Data Firehoseのリソースを作成していきます。
まずはKinesisが使用するIAMロールを作成、各リソースへのアクセス権を付与します。今回必要となった権限の概要は以下です。
- S3バケットにデータを配信する権限
- データ配信エラーをCloudWatch Logsに記録するための権限
- データ変換のためのLambdaの実行権限
resource "aws_iam_role" "firehose_role" { name = "firehose-role" assume_role_policy = data.aws_iam_policy_document.firehose_assume_role_policy_document.json } data "aws_iam_policy_document" "firehose_assume_role_policy_document" { statement { effect = "Allow" actions = ["sts:AssumeRole"] principals { type = "Service" identifiers = ["firehose.amazonaws.com"] } } } resource "aws_iam_role_policy" "firehose_policy" { name = "${aws_iam_role.firehose_role.name}-firehose-policy" role = aws_iam_role.firehose_role.id policy = data.aws_iam_policy_document.firehose_policy_document.json } data "aws_iam_policy_document" "firehose_policy_document" { statement { actions = [ "s3:AbortMultipartUpload", "s3:GetBucketLocation", "s3:GetObject", "s3:ListBucket", "s3:ListBucketMultipartUploads", "s3:PutObject", ] resources = [ "arn:aws:s3:::${var.bucket_name}", "arn:aws:s3:::${var.bucket_name}/${var.bucket_path}/*", ] } statement { actions = [ "kinesis:DescribeStream", "kinesis:GetShardIterator", "kinesis:GetRecords", "kinesis:ListShards", ] resources = [ var.firehose_arn ] } statement { actions = [ "lambda:InvokeFunction", "lambda:GetFunctionConfiguration", ] resources = [ "${var.firehose_lambda_arn}", "${var.firehose_lambda_arn}:*", ] } statement { actions = [ "logs:PutLogEvents", ] resources = [ "${var.firehose_log_arn}/*" ] } }
ロールの次はKinesis Data Firehoseの配信ストリームを作成します。
resource "aws_kinesis_firehose_delivery_stream" "firehose" { name = "delivery_stream" destination = "extended_s3" extended_s3_configuration { role_arn = var.firehose_role bucket_arn = var.bucket_arn prefix = "logs/succeed/!{timestamp:yyyy-MM-dd/}" error_output_prefix = "logs/!{firehose:error-output-type}/!{timestamp:yyyy-MM-dd/}" compression_format = "GZIP" processing_configuration { enabled = "true" processors { type = "Lambda" parameters { parameter_name = "LambdaArn" parameter_value = "${var.firehose_lambda_arn}:$LATEST" } } } cloudwatch_logging_options { enabled = "true" log_group_name = aws_cloudwatch_log_group.firehose_log.name log_stream_name = "DestinationDelivery" } } } resource "aws_cloudwatch_log_group" "firehose_log" { name = "/aws/kinesisfirehose/${var.name}" retention_in_days = var.retention_days }
ポイントは以下です。
destinationで配信先を指定します。S3, Redshift, Splunk, サードパーティーサービスプロバイダーが所有するHTTPエンドポイントなどがサポートされています。processing_configurationはtrueを指定してデータ変換を有効にします。変換用のLambdaを用意することで、受信したデータを変換してから送信先に配信することができます。- データ変換を有効にするとデフォルトで最大3MBまで受信データをバッファするようになります
- Lambdaの同期呼び出しモードを使って、バッファされたバッチごとに指定されたLambdaを非同期で呼び出します。変換されたデータはLambdaからKinesisに送信されます。
- 送信先バッファサイズまたはバッファ間隔に到達した時点で送信先のS3バケットに送信します。デフォルトはバッファサイズが5MB, バッファ間隔が5分です。
- Lambda同期呼び出しモードにはペイロードサイズに6MBの制限があるため、送信するバッファサイズとレスポンスのバッファサイズが6MB以下になるように設計する必要があります。
Lambda
続いてLambdaでの変換処理、LambdaのIAMロール作成、リソースを作成をしていきます。
変換処理を行うLambda関数の作成
サブスクリプションフィルタを介して宛先サービスに送信されるログはgzip形式で圧縮&base64でエンコードされている状態です。送られてくるデータの内容を理解していきます。
サブスクリプションフィルタから送られてくるログ形式
{ "messageType": "DATA_MESSAGE", "owner": "123456789012", "logGroup": "log_group_name", "logStream": "log_stream_name", "subscriptionFilters": [ "subscription_filter_name" ], "logEvents": [ { "id": "01234567890123456789012345678901234567890123456789012345", "timestamp": 1510109208016, "message": "message1" }, { "id": "01234567890123456789012345678901234567890123456789012345", "timestamp": 1510109208017, "message": "message2" } ] }
構成要素は以下です。
- owner
- 発行元ログデータのAWSアカウントID
- logGroup
- 発行元ログデータのロググループ名
- logStream
- 発行元ログデータのログストリーム名
- subscriptionFilters
- 発行元ログデータと一致したサブスクリプションフィルタ名のリスト
- messageType
- "DATA_MESSAGE"が入ってくる。CloudWatch Logsが送信先が到達可能であるかどうかをチェックするために"CONTROL_MESSAGE"というレコードを発行することもある
- logEvents
- ログイベントレコードの配列として表される実際のログデータ。idプロパティは各ログイベントの一意識別子
Lambdaに送られてくるevent
{ "invocationId": "a7234216-12b6-4bc0-96d7-82606c0e80cf". "deliveryStreamArn": "arn:aws:firehose:ap-northeast-1:123456789012:deliverystream/test_firehose", "region": "ap-northeast-1", "records": [ { "recordId": "49578734086442259037497492980620233840400173390482112514000000", "data": "TGFtYmRh44Gr6YCB44KJ44KM44Gm44GP44KLZXZlbnTjgaDjgog=", "approximateArrivalTimestamp": 1510254469499 }, { "recordId": "49578734086442259037497492980621442766219788363254202370000000", "data": "TGFtYmRh44Gr6YCB44KJ44KM44Gm44GP44KLZXZlbnTjgaDjgog=", "approximateArrivalTimestamp": 1510254473773 } ], }
構成要素は以下です。
- invocationId
- Lambda呼び出しID (ランダム GUID)
- deliveryStreamArn
- 配信ストリームARN
- region
- リージョン
- records
- recordId
- Kinesisレコードのシーケンス番号に基づいたレコードID
- data
- 先に紹介した
サブスクリプションフィルタから送られてくるログ形式をgzip形式で圧縮&base64でエンコードした文字列
- 先に紹介した
- recordId
データ変換後のレスポンス
データ変換後のレスポンスのは以下のパラメータが含まれる必要があります。含まれない場合データ変換の失敗として処理されてしまいます。
{ "records": [ { "recordId": "49578734086442259037497492980620233840400173390482112514000000", "result": "Ok", "data": "5aSJ5o+b5b6M44Gu44OH44O844K/44Gg44KI" }, { "recordId": "49578734086442259037497492980621442766219788363254202370000000", "result": "Ok", "data": "5aSJ5o+b5b6M44Gu44OH44O844K/44Gg44KI" } ] }
構成要素は以下です。
- recordId
- 呼び出し時にKinesis Data Firehoseから渡さたレコードID。変換後のレコードには同じレコードIDが含まれる必要があります。元のレコードIDと変換後のレコードIDが不一致の場合はデータ変換失敗として扱われます
- result
- レコードのデータ変換のステータス
- Ok (レコードが正常に変換された)
- Dropped (レコードが処理ロジックによって意図的に削除された)
- ProcessingFailed (レコードを変換できなかった)
- ステータスが Ok または Dropped の場合レコードが正常に処理されたとみなされます。ProcessingFailedの場合のみ正常に処理できなかったとみなされます。
- レコードのデータ変換のステータス
- data
- 変換後のデータをbase64エンコードしたもの
Lambda関数
Lambdaに送られてくるデータ形式とレスポンス形式を確認できたので、実際のデータ変換処理を作っていきます。
作るといっても設計図が用意されいるので、実装する必要があるのはログ変換処理の部分のカスタマイズのみで、レコードのエンコードやレスポンス形式へのフォーマット、Kinesisへのデータ送信といった部分は実装不要です。
設計図からの作成手順は割愛しますので詳しくはドキュメントを参照してください。
今回はPythonのkinesis-firehose-cloudwatch-logs-processor-pythonという設計図を使用しました。
import base64 import gzip import json from io import BytesIO from typing import Generator import boto3 from aws_lambda_powertools import Logger logger = Logger() def transform_log_event(log_event: dict) -> str: """Transform each log event. The default implementation below just extracts the message and appends a newline to it. Args: log_event (dict): The original log event. Structure is {"id": str, "timestamp": long, "message": str} Returns: str: The transformed log event. """ return log_event['message'] + '\n' def process_records(records: list) -> Generator: """kinesisにデータを送信するためのフォーマットに変換する""" for r in records: data = base64.b64decode(r["data"]) data_dict = {} with BytesIO(data) as bio, gzip.GzipFile(fileobj=bio, mode="r") as f: data_dict = json.loads(f.read()) rec_id = r["recordId"] # CONTROL_MESSAGE are sent by CWL to check if the subscription is reachable. # They do not contain actual data. if data_dict["messageType"] == "CONTROL_MESSAGE": yield {"result": "Dropped", "recordId": rec_id} elif data_dict["messageType"] == "DATA_MESSAGE": joined_data = "".join([transform_log_event(e) for e in data_dict["logEvents"]]) encoded_data = base64.b64encode(joined_data.encode("utf-8")) if len(encoded_data) == 0: yield {"result": "Dropped", "recordId": rec_id} elif len(encoded_data) <= 6000000: yield {"data": encoded_data, "result": "Ok", "recordId": rec_id} else: yield {"result": "ProcessingFailed", "recordId": rec_id} else: yield {"result": "ProcessingFailed", "recordId": rec_id} def put_records_to_firehose_stream(stream_name: str, records: list, client, attempts_made: int, max_attempts: int): """変換後のデータをkinesisに送信する""" failed_records = [] codes = [] err_msg = "" # if put_record_batch throws for whatever reason, response['xx'] will error out, adding a check for a valid # response will prevent this response = None try: response = client.put_record_batch(DeliveryStreamName=stream_name, Records=records) except Exception as e: failed_records = records err_msg = str(e) # if there are no failedRecords (put_record_batch succeeded), iterate over the response to gather results if not failed_records and response and response["FailedPutCount"] > 0: for idx, res in enumerate(response["RequestResponses"]): # (if the result does not have a key 'ErrorCode' OR if it does and is empty) => we do not need to re-ingest if "ErrorCode" not in res or not res["ErrorCode"]: continue codes.append(res["ErrorCode"]) failed_records.append(records[idx]) err_msg = "Individual error codes: " + ",".join(codes) if len(failed_records) > 0: if attempts_made + 1 < max_attempts: logger.warning( "Some records failed while calling PutRecordBatch to Firehose stream, retrying. %s" % (err_msg) ) put_records_to_firehose_stream(stream_name, failed_records, client, attempts_made + 1, max_attempts) else: raise RuntimeError("Could not put records after %s attempts. %s" % (str(max_attempts), err_msg)) def create_reingestion_record(original_record: dict) -> dict: """レコードのbase64文字列をデコードする""" return {"data": base64.b64decode(original_record["data"])} def get_reingestion_record(re_ingestion_record: dict) -> dict: """kinesisで処理するためのフォーマットに変換する""" return {"Data": re_ingestion_record["data"]} @logger.inject_lambda_context(log_event=True) def handler(event, context): stream_arn = event["deliveryStreamArn"] region = stream_arn.split(":")[3] stream_name = stream_arn.split("/")[1] records = list(process_records(event["records"])) projected_size = 0 data_by_record_id = {rec["recordId"]: create_reingestion_record(rec) for rec in event["records"]} put_record_batches = [] records_to_reingest = [] total_records_to_be_reingested = 0 for idx, rec in enumerate(records): if rec["result"] != "Ok": continue projected_size += len(rec["data"]) + len(rec["recordId"]) # 6000000 instead of 6291456 to leave ample headroom for the stuff we didn't account for if projected_size > 6000000: total_records_to_be_reingested += 1 records_to_reingest.append(get_reingestion_record(data_by_record_id[rec["recordId"]])) records[idx]["result"] = "Dropped" del records[idx]["data"] # split out the record batches into multiple groups, 500 records at max per group if len(records_to_reingest) == 500: put_record_batches.append(records_to_reingest) records_to_reingest = [] if len(records_to_reingest) > 0: # add the last batch put_record_batches.append(records_to_reingest) # iterate and call putRecordBatch for each group records_reingested_so_far = 0 if len(put_record_batches) > 0: client = boto3.client("firehose", region_name=region) for record_batch in put_record_batches: put_records_to_firehose_stream(stream_name, record_batch, client, attempts_made=0, max_attempts=20) records_reingested_so_far += len(record_batch) logger.info( "Reingested %d/%d records out of %d" % (records_reingested_so_far, total_records_to_be_reingested, len(event["records"])) ) else: logger.info("No records to be reingested") return {"records": records}
transform_log_eventの中身を任意の変換処理に修正するだけで使えるようになっていますが、設計図のままだとKinesis Data StreamsとKinesis Data Firehose両方に対応している実装になってるので不要な処理(Kinesis Data Streamsのほう)を削除し、Type Hints追加したりloggerを使うようにしたりなどの修正を加えています。
LambdaのIAMロールとリソース作成
Lambda用のIAMロールを作ります。
resource "aws_iam_role" "lambda_role" { name = "lambda-role" assume_role_policy = data.aws_iam_policy_document.lambda_assume_role_policy_document.json } data "aws_iam_policy_document" "lambda_assume_role_policy_document" { statement { effect = "Allow" actions = ["sts:AssumeRole"] principals { type = "Service" identifiers = ["lambda.amazonaws.com"] } } } resource "aws_iam_role_policy_attachment" "AWSLambdaKinesisExecutionRole" { role = aws_iam_role.lambda_role.name policy_arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaKinesisExecutionRole" } resource "aws_iam_role_policy" "firehose_policy" { name = "${aws_iam_role.lambda_role.name}-policy" role = aws_iam_role.lambda_role.id policy = data.aws_iam_policy_document.firehose_policy_document.json } data "aws_iam_policy_document" "firehose_policy_document" { statement { actions = [ "firehose:PutRecordBatch", ] resources = [ var.firehose_arn ] } }
AWSLambdaKinesisExecutionRoleポリシーにはKinesisの項目を読み取る権限、CloudWatch Logsにログを書き込む権限があります。
これだけだと変換後のデータをKinesisに送る権限が足りないためfirehose:PutRecordBatchの権限を追加で付与しておきます。
最後にLambdaとCloudWatch Logsのロググループを作成します。
resource "aws_lambda_function" "lambda_function" { function_name = var.name role = var.role_arn package_type = "Image" image_uri = "${var.image_uri}:latest" memory_size = 512 timeout = 300 reserved_concurrent_executions = 5 depends_on = [ aws_cloudwatch_log_group.log_group, ] lifecycle { ignore_changes = [image_uri] } } resource "aws_cloudwatch_log_group" "log_group" { name = "/aws/lambda/${var.name}" retention_in_days = 90 }
ポイントは以下です。
- KinesisでサポートされているLambdaの呼び出し時間は最大5分のため
timeoutは300(sec)を指定 - 同時実行数のクォータはデフォルトで1000となっているので、他サービスと相談して同時実行数を決めると良いです。捌きたいログの量、パフォーマンスによってチューニングが必要になってくるところかと思います
Athena(Redash)
さて、ここまででCloudWatch LogsのログをLambda経由で変換し、S3に配信する仕組みができました。
あとは配信先のS3バケットからAthenaテーブルを作成すれば完成です。今回、Athenaテーブルの作成は最初の一度きりだけのためTerraformで実装していません。テーブル作成の手順はドキュメントを参照ください。
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/creating-tables.html
またAthenaをデータソースとするRedashは既に仕組み化されていたため、この記事では説明を割愛します。詳しくはRedashのドキュメントを参照ください。
https://redash.io/help/data-sources/querying/amazon-athena
最後にRedashで必要なクエリを保存すれば、ログ提供の自動化、およびRedashから簡単にログを検索できる仕組みの完成です!
最後に
CloudWatch Logsサブスクリプションフィルタ + Kinesis + Lambdaを使用することで、複雑そうなETL処理をサーバレスで簡単に構築することができました。
各サービス間で受け渡されるデータモデルを理解するまでに少し苦労したのと、サーバーレスな分、実装途中の動作検証が手間取りました。
ただ一度作ってしまえば拡張やメンテは楽にできるかと思うので、今後同じようなログ提供自動化が必要になった際はこの仕組みを活用していきたいです。
以上、最後まで読んでいただきありがとうございました。
Architectグループでは一緒に働く仲間を募集しています。
*1:本ブログSansan Builders Blogのことです