
こんにちは、R&D Architectグループの辻田です。
今回はカスタムメトリクスを使ってターゲット追跡スケーリングを行い、費用の無駄が少ない最適なスケーリングの実現に取り組んだ内容を紹介します。
カスタムメトリクスはSQSキューのメッセージ数とオートスケーリンググループ内のインスタンス数から算出した値で発行します。
大まかな流れはAWSのドキュメントで紹介されている通りです。下記アーキテクチャに加えて、カスタムメトリクスの発行にはLambda+EventBridgeを使用したのでそちらも紹介していきます。
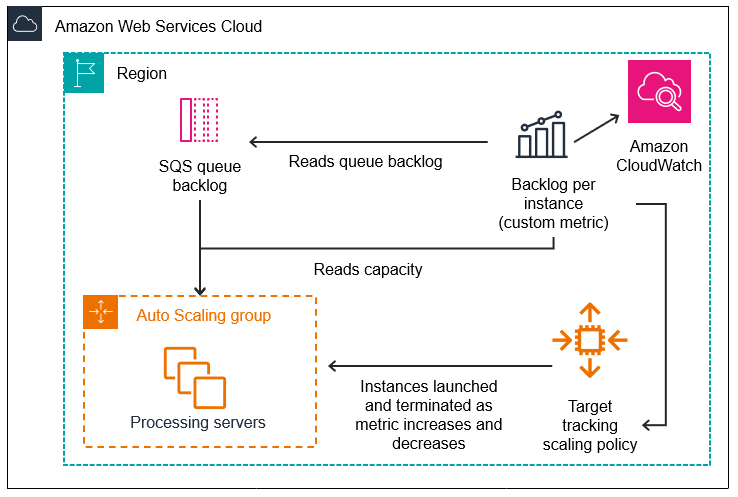
Scaling based on Amazon SQS - Amazon EC2 Auto Scaling
背景と課題
SQSキューからメッセージを受け取り処理するECSサービスにて、メッセージの数に応じてオートスケーリングさせたいサービスがありました。メッセージがたくさん積まれたらスケールアウトし、減ってきたらスケールインしたい、という要件です。
しかし、 CloudWatchの標準メトリクスであるAWS/SQSのApproximateNumberOfMessagesVisible(キューから取得可能なメッセージ数)をもとにスケーリングを行う場合、キュー内のメッセージの数がメッセージを処理するオートスケーリンググループのサイズに比例して変化しないという課題があります。
例えば、ApproximateNumberOfMessagesVisibleが60以上でスケールアウト、0以下でスケールインするようなステップスケーリングを設定した場合で、1インスタンス分スケールアウトして十分に捌ける状態になったとしても、メトリクスの対象であるメッセージ数が変わらず60来ていたらまたスケールアウトしてリソースを無駄に使ってしまう可能性があります。
この課題を解決するため、
- インスタンスあたりのバックログ
- SQSのApproximateNumberOfMessagesの数 ÷ オートスケーリンググループのサイズ(InService中のインスタンス数)
- インスタンスあたりの適正バックログ
- 許容できる最大レイテンシ ÷ メッセージの平均処理時間
この2つの値を活用して、適切なスケーリングができるようにします。
カスタムメトリクスを発行するLambdaの実装
カスタムメトリクスの発行はLambda+EventBridgeで実現しています。EventBridgeはcron用途で1分毎にLambdaを実行してメトリクスを更新します。
以下、インスタンスあたりのバックログを計算してカスタムメトリクスを発行するLambda(Python)の実装です。
import os import boto3 from aws_lambda_powertools import Logger logger = Logger() _asg_name = os.getenv("ASG_NAME") _queue_name = os.getenv("QUEUE_NAME") _custom_namespace = os.getenv("CUSTOM_NAMESPACE") _metric_name = os.getenv("METRIC_NAME") @logger.inject_lambda_context(log_event=True) def handler(event, context): """カスタムメトリクスを定期的に発行するLambda""" cloudwatch = boto3.client("cloudwatch") sqs = boto3.client("sqs") asg = boto3.client("autoscaling") queue_url = sqs.get_queue_url(QueueName=_queue_name)["QueueUrl"] sqs_res = sqs.get_queue_attributes( QueueUrl=queue_url, AttributeNames=["ApproximateNumberOfMessages"], ) messages = sqs_res["Attributes"]["ApproximateNumberOfMessages"] asg_res = asg.describe_auto_scaling_groups( AutoScalingGroupNames=[_asg_name], ) in_service_instances = 0 for asg in asg_res["AutoScalingGroups"]: for instance in asg["Instances"]: if instance["LifecycleState"] == "InService": in_service_instances += 1 metric_value = 0 if in_service_instances == 0 else int(messages) / int(_parallel_columns) / in_service_instances logger.info( f"approximate_number_of_messages: {messages}, in_service_instances: {in_service_instances}, metric_value: {metric_value}" ) cloudwatch.put_metric_data( Namespace=_custom_namespace, MetricData=[ { "MetricName": _metric_name, "Dimensions": [ {"Name": "QueueName", "Value": _queue_name}, {"Name": "AutoScalingGroupName", "Value": _asg_name}, ], # ApproximateNumberOfMessagesの数 / InService中のインスタンス数 "Value": metric_value, "Unit": "Count", }, ], )
ドキュメントで紹介されている方法をそのままPythonで実装した感じですが、要点は以下です。
- SQSのApproximateNumberOfMessages(キューから取得可能なメッセージ数)を取得
- オートスケーリンググループのInService状態のインスタンス数を取得
- ApproximateNumberOfMessagesをInService中のインスタンス数で割って、インスタンスごとのバックログを計算
- 結果をCloudWatchカスタムメトリクスに記録
Lambda、EventBridgeのリソース作成
上記LambdaをEventBridgeで1分間隔で実行するようにすれば、カスタムメトリクスを記録する仕組みは完成です。
設定方法はドキュメントを参照ください。
https://docs.aws.amazon.com/ja_jp/eventbridge/latest/userguide/eb-run-lambda-schedule.html
メトリクスが表示されるようになるまで少しラグがあるようですが、しばらくするとこのようなメトリクスが取れるようになります。

ターゲット追跡スケーリングポリシーを作成
最後にオートスケーリンググループのターゲットスケーリングポリシーを作成します。
この例では許容できる最大レイテンシ: 300sec, メッセージの平均処理時間: 10secとするため、ターゲット値は300/10の30として設定しています。
$ cat ~/config.json
{
"TargetValue":30,
"CustomizedMetricSpecification":{
"MetricName":"BacklogPerInstance",
"Namespace":"Sample/Namespace",
"Dimensions":[
{
"Name":"QueueName",
"Value":"sample-queue"
},
{
"Name":"AutoScalingGroupName",
"Value":"sample-asg"
}
],
"Statistic":"Average",
"Unit":"Count"
}
}
put-scaling-policyコマンドでポリシーを作成します。
aws autoscaling put-scaling-policy --policy-name sqs10-target-tracking-scaling-policy \ --auto-scaling-group-name sample-asg --policy-type TargetTrackingScaling \ --target-tracking-configuration file://~/config.json
ターゲットスケーリングポリシーを作成すると、スケールアウト, スケールインのアラームも自動で作成されます。これでインスタンスあたりの適正バックログをもとにしたオートスケーリングの完成です。
最後に
メッセージ数、オートスケーリンググループのサイズから算出した値でカスタムメトリクスを作成することで、より正確で高速にスケーリングできる仕組みができました。ターゲット追跡ポリシーのターゲット値についてはサービスによって許容されるレイテンシは様々なので、この値の設計が肝となりそうです。弊チームでもターゲット値を小さく設定しすぎて、必要以上にスケールしてしまったことがあります。
SQS標準メトリクスでのスケーリングが満足にいってない場合は是非こちらの方法を検討してみてはいかがでしょうか。
最後まで読んでいただきありがとうございました。
Architectグループでは一緒に働く仲間を募集しています。