はじめに
技術本部 Sansan Engineering Unit Nayoseグループの上島です。
今回、Nayoseグループで大規模なバッチシステムを開発し、従来システムと比較して9倍の高速化を達成しました。また、処理期間は数十日から数日へと大幅に短縮することに成功しました。
本記事では、この事例と設計時に考慮した点をご紹介します。具体的にはタイトルにある通り、億単位の大規模ジョブを扱う中で直面した課題—ジョブの抽出・管理・実行制御—への取り組みについて解説します。
Nayoseグループは、当社のほぼすべてのプロダクトが利用する共通基盤である”データの名寄せ”サービスを開発・運用しています。 ここでいう名寄せとは、名刺や取引先の情報など別々に存在する多種多様なデータの中から同じ組織や人物に関する情報を識別し、それらをひとまとめにグルーピングすることです。
背景
日々、私たちは名寄せの精度向上と、より多くのデータの名寄せを目指してアルゴリズムの改善に取り組んでいます。
名寄せされたデータは組織に関するマスタデータとひもづけられ、多様なビジネスを支援する情報へのアクセスが可能になります。このため、名寄せアルゴリズムが改善されることで、ユーザーはより求める情報にアクセスできるようになります。そして名寄せアルゴリズムを変更する際は、新規の名寄せ依頼データだけでなく、過去の名寄せ済みの名寄せ依頼データにも新しいアルゴリズムを適用し直す必要があります。この再適用プロセスを「洗い替え」と呼んでいます。
プロダクトの成長に伴い、日々データ量が増加する中で、旧来のシステムではこの洗い替えに多くの時間を要する課題が浮上しました。この洗い替え期間の課題を解決し、名寄せの価値をユーザーに素早く届けるため、システムの刷新プロジェクトに取り組みました。
新しいシステムに求めたこと(要件)
- 短期間で洗い替えが完了できること
- 洗い替え期間の短縮とスループットの向上が一番の目的のため
- 柔軟に洗い替え対象を決定可能であること
- 対象はアルゴリズム改善内容によってまちまちであるため
- 洗い替え順序を決定可能であること
- お客様のデータ(以下、テナント)ごとにまとめて洗い替えたいため
洗い替えバッチシステムの設計
結果として、システムの全体像は以下の図のようになりました。以下では、図の詳細と、大量のジョブ処理に伴う課題を考慮したバッチシステムの設計で重視した点をご紹介します。なお、開発プラットフォームにはAWSを採用しました。

洗い替え対象データの抽出
膨大な名寄せ依頼データからAthenaで効率的に抽出
メインDBにはRDSのAmazon Aurora(MySQL)を使用していますが、データ量が億単位と膨大で、セカンダリインデックスにも限りがあるため、名寄せアルゴリズムの改善内容に応じて洗い替え対象を柔軟な抽出するユースケースには適していませんでした。さらに、抽出に時間がかかることで、DBを参照しているリアルタイムサービスにも悪影響を及ぼす問題がありました。
そこで、メインのDBから直接抽出せず、Athenaを使って抽出することにしました。AthenaはS3上のデータに対して、事前のインデックス作成がなくてもクエリを自動的に並列実行できます。そのため、大規模なデータセットでも高速にクエリ結果を返すことが可能です。
そして、RDSには、DBのクラスタ(もしくはスナップショット)からS3にエクスポートする機能があります。
このシステムでは、RDSからS3上にエクスポートされたDBデータをAthenaのSQLで検索することで、RDSのインデックスによらない柔軟な対象の抽出を可能にしました。
大量ジョブ管理と実行順序制御
Athenaによるジョブ実行順序の決定
Athenaで洗い替え対象の名寄せ依頼データを抽出した後、それら1つ1つをジョブとして扱います。これらのジョブは、お客様のテナントごとにまとめて処理されるよう、ソートされている必要があります。これを実現するために、ジョブ全体をAthenaでソートし、順序性のあるジョブ実行IDを付与した後、ソート済みジョブリストとしてAthenaテーブルに出力するようにしました。これにより洗い替えの実行順序を決定できました。
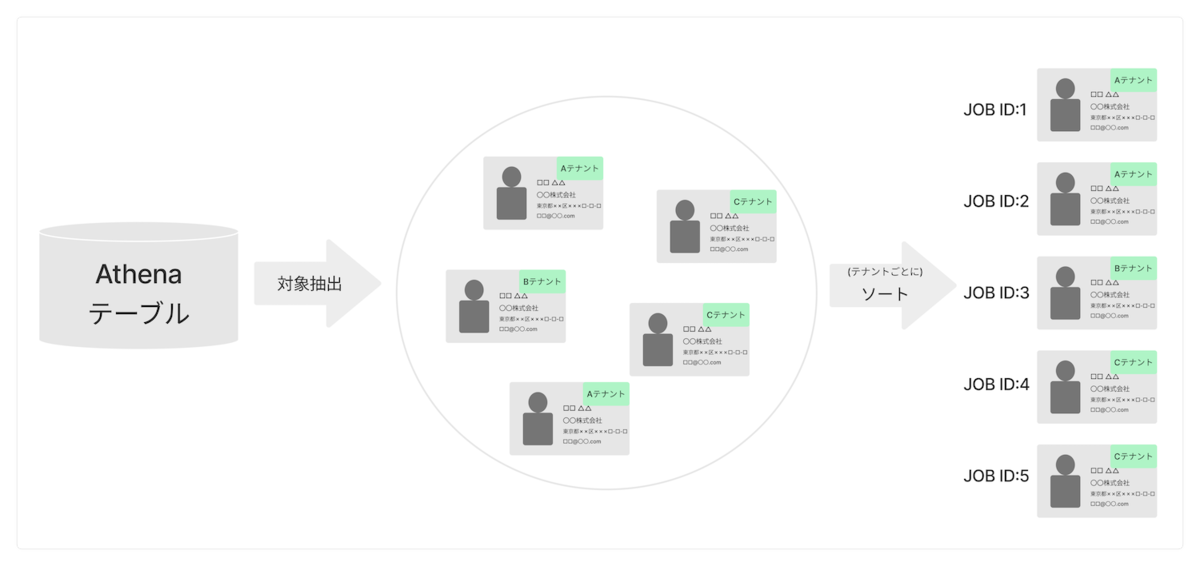
しかし、Athenaといえど今回扱うデータ量ではこのソートを実現するのが難しく、格闘したので同じプロジェクトメンバーの冨田より別記事で詳しく紹介します。 buildersbox.corp-sansan.com
スケーラビリティを確保したジョブ管理
大量ジョブのスケーラビリティの課題
本システムでは、すべての対象を抽出してジョブを一度に大量に作成するため、ピーク時のジョブ量が非常に多く、ジョブの情報量も大きくなります。そのため、ジョブ管理用のデータストアへの取り込みには、多大な時間とシステムリソース(ストレージや処理能力など)を要します。
検討したが採用を見送ったこと
- RDS
- RDSのAmazon Aurora(MySQL)のテーブルで1レコードを1ジョブとして管理する場合、一括インサートなどの工夫をしても、本番環境レベルのDBスペックでデータの取り込みに数十時間かかる見積もりとなり、パフォーマンス不足でした。
- Redisなどのインメモリデータベース
- データの取り込みは高速化できますが、大容量メモリを搭載したインスタンスが常時必要になります。使用頻度が時期によって変動するため、これは非効率な面がありました。
- SQS
- メッセージの保持期間が最大14日間と限られているため、メインのジョブストアとしての採用を見送りました。
- AWS Batch
- キューとコンピュートが統合されているメリットがある一方で、1ジョブごとに1 ECSタスクを起動する仕様であり、効率面で今回の用途には適していませんでした。
ファイルベースでのジョブ管理
これらの検討を踏まえ、本システムでは個々のジョブを直接管理する方式を避け、複数のジョブをまとめた単位で管理するようにしました。具体的には、ソート済みジョブリストをAthenaでチャンクごとに分割し、各チャンクをS3上のCSVファイルとして保存しました。そして、これらCSVファイルへの参照(S3 URI)をジョブのメタ情報としてDBで管理する方式を採用しました。

チャンクの番号順にCSVファイルからジョブを読み込んで処理し(※)、併せてジョブの進行状態をDBで管理することで、大量のジョブを効率的に扱いながら、処理順序の制御ができるようになりました(※詳細は後述)。

この方式により、ジョブ量が増え続けても、S3のストレージ使用量が増えるだけで容易にスケールできるようになり(コストも抑えられる)、洗い替えのジョブセットアップも15分程度という短時間で完了できます。
並列処理とジョブ分配
大量ジョブの並列処理
洗い替え期間を短縮するためには、セットアップ時間の短縮だけでなく、ジョブの処理スループットを上げることも重要になります。
スループット向上のアプローチは、アプリを最適化するか、インフラで並列化するという選択肢があると考えられますが、今回は後者を選択し、スケーラビリティを優先して大規模な並列処理を可能にするアプローチを採用しました。プロデューサー/コンシューマーパターンを適用しています。
Nayoseグループでは、ECSをバッチ基盤として使用しています。そのため、洗い替え処理用のECSサービスを作成し、ECSタスク(洗い替え処理ワーカー)を大量に配置することで、大幅に処理能力を向上させることができました。
ジョブ分配と部分的順序保証
洗い替え処理ワーカーへのジョブ分配方法は、ジョブエンキューワーカーにて先述のチャンクCSVファイルから読み取ったジョブをSQS(Standard Queue)にエンキューし、SQS経由で分配する方式を採用しました。
ただし、SQS(Standard Queue)には制約があり、メッセージの順序保証がないこと、一度にエンキューできる数が最大10件に限られていることです。また、エンキュー速度を確保するために並列でエンキューを行うと、メッセージの順序が崩れやすくなります。
それでもなお、SQSをキューとして選択した理由は、マネージドサービスとしての運用の容易さにあります。具体的には、高いスケーラビリティ、CloudWatchによる監視機能、そして処理に失敗したジョブの自動リトライ機能などです。
ちなみに、SQSにはFIFOキューも存在しますが、これは全体ではなく一定のグループ内での順序保証にとどまるため、今回の用途には適していませんでした。
順序保証と先述のメインのジョブストアとしなかった理由であるメッセージ保持期間の制約に対処するため、プロデューサー側(エンキューワーカー)で1回につき一定の個数ずつジョブをSQSにエンキューし、コンシューマー(洗い替え処理ワーカー)が捌き終わったら、次のエンキューをするという方式を採り、SQSを極短期のキューとして使うようにしました。これにより極短期のタイムボックス内では順序保証できないものの、より長期のタイムボックス内では部分的に順序保証できるようになりました。

新しいシステムの運用結果
洗い替え期間の短縮とスループットの向上が最大の目的でしたが、冒頭で述べた通り、新システムのスループットは従来比9倍に向上し、処理期間を数十日から数日へと大幅に短縮することに成功しました。
当初の目標は3倍でしたが、プロジェクト途中でマシンリソース追加の予算承認を得られたため、洗い替え処理ワーカーのタスク数をさらに3倍に増やすだけで、9倍の高速化を達成できました。
スケーラビリティを念頭に置いた設計が功を奏したのではないかと思います。
今後の展望
別の対象抽出手段として、Amazon Redshift と Amazon Aurora ゼロ ETL 統合があります。こちらはほぼリアルタイムでクエリが可能です。諸事情により採用を断念しましたが、この方法ではAthenaで検索するためのRDS→S3エクスポート作業が不要になります。そのため、Athena同様に柔軟な検索が可能で、かつ高速であれば、将来的に再検討してみようと考えています。
おわりに
今回は大規模データの洗い替えバッチシステムと設計で考慮した点についてご紹介しました。 ここで紹介した内容のひとつでも、皆さまのお役に立てれば嬉しいです。
大規模なデータを扱うこのプロジェクトは非常にチャレンジングでしたが、さまざまな制約の中でいかに効率的に処理するかを模索する過程が個人的にとても面白く感じました。
ここまでお読みいただき、ありがとうございました。
私たちNayoseグループが所属するデータ戦略部門では、Webアプリ開発エンジニア、アルゴリズムエンジニア、データエンジニアを募集しています。
少しでもご興味を持っていただけましたら、ぜひ面談だけでもお越しいただければ幸いです。