技術本部 Sansan Engineering Unit Nayoseグループでエンジニアをしている冨田と申します。私たちのグループでは、当社のほぼすべてのプロダクトが利用する共通基盤である”データの名寄せ”サービスの開発を日々行っています。
今回は、普段の業務の中で直面した課題についてご紹介します。Athenaクエリの実行中に、ソート処理がボトルネックとなり失敗してしまう問題が起きました。そこで、問題解決に向けて試行錯誤したプロセスや得られた知見を共有します。
Athenaクエリが実行失敗した件を説明する前段として、まず名寄せについて説明します。
名寄せの洗い替えについて
上記の「名寄せ」というのは、別々のデータとして存在する「同じ会社や人物のデータ(以降「名寄せ依頼データ」と呼ぶ)」をひとまとめにグルーピングすることを言います。
今回、この名寄せ結果を洗い替える仕組みの刷新が行われました。「洗い替え」とは「名寄せアルゴリズムの変更に伴い、名寄せ依頼データ群に最新アルゴリズムを適用する取り組み」のことを指します。
本記事では、この仕組みの一部分を実現するまでの道のりについて解説します。
洗い替え作業の大まかな処理の流れとしては以下になります。
- Athenaで名寄せ依頼データを洗い替え順にソートする(本記事で紹介する部分)
- その後、ソート順に分割したCSVを出力する
- 洗い替え順に沿って、SQSにジョブをエンキューしていく
- 一CSV分のジョブが捌けたら次のCSV分のジョブが対象になる
- エンキューされたジョブをECSワーカーで処理していく
- SQSをポーリングして名寄せ処理を実施する
本記事で紹介する部分は、以下の赤枠になります。
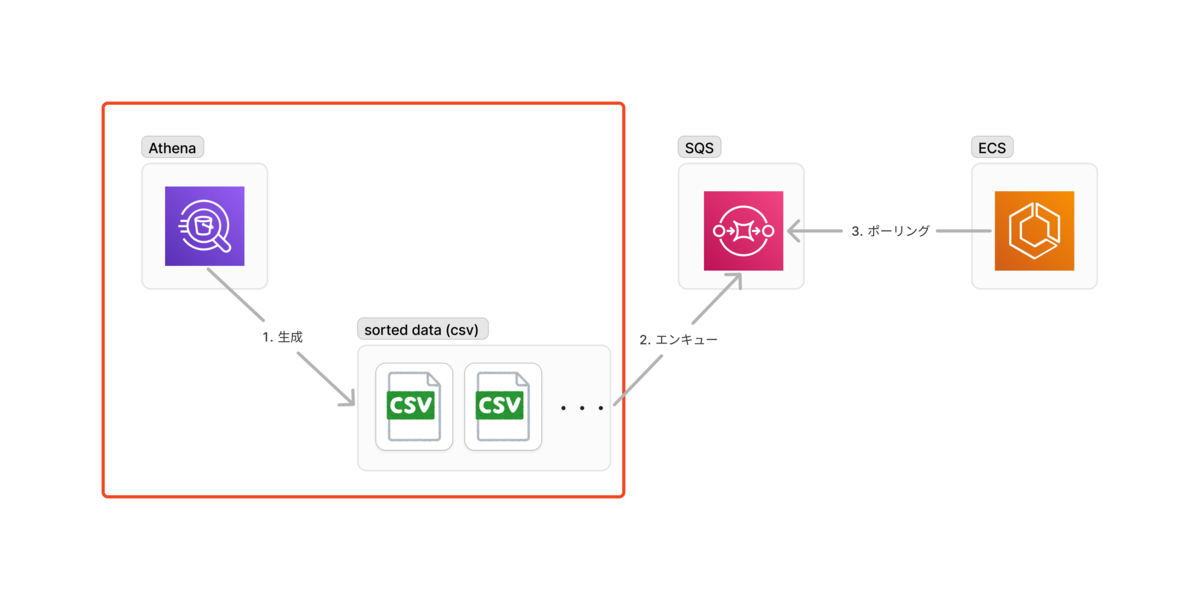
仕組みの詳細について詳しく知りたい場合は、以下の記事をご覧ください。 buildersbox.corp-sansan.com
Athenaのengine versionは3になります。Athenaを選定した理由は、名寄せ依頼データを洗い替え順にソートするにあたって利用したい関連テーブルが既に存在しており都合がいいこと、他処理で利用実績があったことなどが挙げられます。
洗い替え順をソートする理由
新旧の名寄せ結果が混在する期間を削減するために、お客様のデータ(以降「テナント」と呼ぶ)ごとにソートして洗い替えます。
図と合わせて説明します。
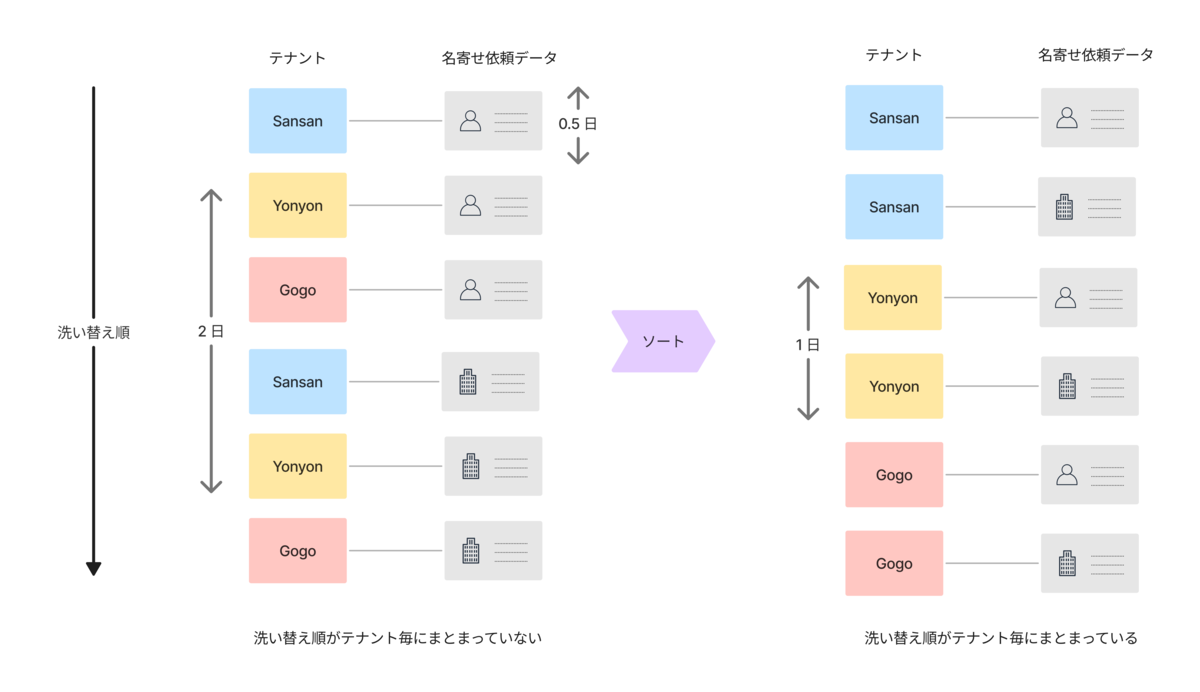
1つの名寄せ依頼データを洗い替えるのに半日掛かると仮定します。洗い替え順がテナントごとにまとまっていない場合、テナントごとの洗い替え完了に2日ずつかかります。一方、洗い替え順がテナントごとにまとまっている場合、テナントごとの洗い替え完了が1日ずつで済みます。
名寄せ依頼データを洗い替え順にソートするため、名寄せ依頼データをテナント単位にまとまるようソートして、そのソート結果に対して順序性のあるジョブ実行IDを付与する必要がありました。ジョブ実行ID順に処理していくことで、テナント単位で洗い替えを進められます。
テーブルのイメージと合わせて説明します。
まずnayose_targetsテーブルがあります。このテーブルには、名寄せ依頼データが格納されています。
| nayose_target_id | tenant_name |
|---|---|
| 441 | Yonyon |
| 30 | Sansan |
| 20 | Yonyon |
| 40 | Yonyon |
| … | … |
nayose_target_idは名寄せ依頼データを一意に特定するID、tenant_nameはその名寄せ依頼データを保持するテナントを指します。本テーブルは億単位のレコードを保持します。
実現したいことは、nayose_targetsテーブルを利用して、以下を出力することになります。
| job_execution_id | nayose_target_id | tenant_name |
|---|---|---|
| 1 | 10 | Sansan |
| 2 | 30 | Sansan |
| 3 | 20 | Yonyon |
| 4 | 40 | Yonyon |
| … | … | … |
ポイントとしては「テナントごとにまとめてソートされた上で、順序性のあるジョブ実行ID(シーケンス番号)が振られている」になります。
以降から、具体的にAthenaクエリが実行失敗した件について説明します。
ソート処理によるリソース不足
早速、「テナントごとにソートしジョブ実行IDを付与するクエリ」を組んでみます。
SELECT ROW_NUMBER() OVER(ORDER BY tenant_name) AS job_execution_id, nayose_target_id, tenant_name FROM nayose_targets
上記クエリを実行したところ、「Query exhausted resources at this scale factor」というエラーメッセージが表示されました。クエリの実行に必要なリソース(CPU、メモリ、I/Oなど)を使い果たしたと読み取れます。
Athenaクエリの最適化対象として挙げられているように、上記クエリのボトルネックは「order by」にあると当たりを付けました。
実際に確認してみます。
EXPLAIN ANALYZE 構文を利用して、クエリ実行時間やCPU処理時間を確認します。EXPLAIN ANALYZEの結果を得るためには、対象クエリの実行に成功する必要があるので、対象レコードをサンプリングしています(part_nayose_targetsテーブルにサンプリング結果が格納されています)。
order byなし
EXPLAIN ANALYZE SELECT ROW_NUMBER() OVER() AS job_execution_id, nayose_target_id, tenant_name FROM part_nayose_targets
Query Plan
Queued: 512.52us, Analysis: 159.25ms, Planning: 75.91ms, Execution: 1.25s
Fragment 1 [SINGLE]
CPU: 429.40ms, Scheduled: 482.78ms, Blocked 4.53s (Input: 3.91s, Output: 263.69ms), Input: [mask] rows ([mask]), Data Scanned: 0B; per task: avg.: [mask] std.dev.: 0.00, Output: [mask] rows ([mask])
Output layout: [nayose_target_id, tenant_name, row_number]
Output partitioning: SINGLE []
RowNumber[]
...
Fragment 2 [SOURCE]
CPU: 3.76s, Scheduled: 7.07s, Blocked 1.20s (Input: 0.00ns, Output: 1.18s), Input: [mask] rows ([mask]), Data Scanned: [mask]; per task: avg.: [mask] std.dev.: 0.00, Output: [mask] rows ([mask])
Output layout: [nayose_target_id, tenant_name]
Output partitioning: SINGLE []
TableScan[table = awsdatacatalog:tomita:part_nayose_targets]
...
order byあり
EXPLAIN ANALYZE SELECT ROW_NUMBER() OVER(ORDER BY tenant_name) AS job_execution_id, nayose_target_id, tenant_name FROM part_nayose_targets
Query Plan
Queued: 621.67us, Analysis: 161.23ms, Planning: 98.93ms, Execution: 18.79s
Fragment 1 [SINGLE]
CPU: 17.64s, Scheduled: 17.67s, Blocked 5.60s (Input: 4.61s, Output: 0.00ns), Input: [mask] rows ([mask]), Data Scanned: 0B; per task: avg.: [mask] std.dev.: 0.00, Output: [mask] rows ([mask])
Output layout: [nayose_target_id, tenant_name, row_number]
Output partitioning: SINGLE []
Window[orderBy = [tenant_name ASC NULLS LAST]]
...
Fragment 2 [SOURCE]
CPU: 3.28s, Scheduled: 7.17s, Blocked 1.07s (Input: 0.00ns, Output: 1.07s), Input: [mask] rows ([mask]), Data Scanned: [mask]; per task: avg.: [mask] std.dev.: 0.00, Output: [mask] rows ([mask])
Output layout: [nayose_target_id, tenant_name]
Output partitioning: SINGLE []
TableScan[table = awsdatacatalog:tomita:part_nayose_targets]
...
「Execution(2行目の末尾)」から実行時間、「Fragment 1(ソート有無の違いがある処理ステップ)のCPU(4行目の先頭)」からCPU処理時間に差があることがわかります。他にもさまざまな情報が確認できます。詳細な結果の確認方法はドキュメントをご参照ください。
ボトルネック箇所がわかったので、このソート処理をいかにして改善するか検討します。
パフォーマンスチューニング
Athenaでのパフォーマンスのチューニングを参考に、以下の観点から考えてみます。
- データを最適化する
- クエリを最適化する
データを最適化する
まずは、クエリを変更せずにデータセットの構成方法を見直して改善できるか見ていきます。
パーティション化
最初に浮かんだのはパーティション化でした。
パーティション化とは、指定キー(パーティションキー)ごとにレコードをグループ化する手法です。パーティションキーの絞り込みにより、スキャン対象を減らしてパフォーマンス向上を狙えます。ただし、今回のクエリでは、特に絞り込みは行っていないため改善は期待できません。
バケット化
スキャン量を減らす別の方法として、バケット化があります。
バケット化は、指定キー(バケットキー)値に基づいてレコードを個別ファイル(バケット)に分散する手法です。バケット化によって、同じ値を持つ全てのレコードが同じファイル内に存在することが保証されます(合わせてバケット数=ファイル数を指定します)。今回のクエリでは絞り込みは行っていませんが、バケット化することで、バケットキー値が事前にある程度ソートされて格納されるため、ORDER BY実行時のソートが効率化されてパフォーマンス向上することを期待して試してみます。
ちなみに、バケット数の設定はファイルサイズとファイル数に影響します。ファイルサイズは、一般的なガイドラインとしては約128MBが一つの目安となるようです。
では、バケット化による効果を確認してみます。
バケット化なし
EXPLAIN ANALYZE SELECT ROW_NUMBER() OVER(ORDER BY tenant_name) AS job_execution_id, nayose_target_id, tenant_name FROM part_nayose_targets
Query Plan
Queued: 621.67us, Analysis: 161.23ms, Planning: 98.93ms, Execution: 18.79s
Fragment 1 [SINGLE]
CPU: 17.64s, Scheduled: 17.67s, Blocked 5.60s (Input: 4.61s, Output: 0.00ns), Input: [mask] rows ([mask]), Data Scanned: 0B; per task: avg.: [mask] std.dev.: 0.00, Output: [mask] rows ([mask])
Output layout: [nayose_target_id, tenant_name, row_number]
Output partitioning: SINGLE []
Window[orderBy = [tenant_name ASC NULLS LAST]]
...
Fragment 2 [SOURCE]
CPU: 3.28s, Scheduled: 7.17s, Blocked 1.07s (Input: 0.00ns, Output: 1.07s), Input: [mask] rows ([mask]), Data Scanned: [mask]; per task: avg.: [mask] std.dev.: 0.00, Output: [mask] rows ([mask])
Output layout: [nayose_target_id, tenant_name]
Output partitioning: SINGLE []
TableScan[table = awsdatacatalog:tomita:part_nayose_targets]
...
バケット化あり
CREATE TABLE "bucketed_part_nayose_targets" WITH ( format = 'parquet', external_location = 's3://test/bucketed_part_nayose_targets/', bucketed_by = ARRAY['tenant_name'], bucket_count = バケット数 ) AS SELECT * FROM part_nayose_targets ; EXPLAIN ANALYZE SELECT ROW_NUMBER() OVER(ORDER BY tenant_name) AS job_execution_id, nayose_target_id, tenant_name FROM bucketed_part_nayose_targets
Query Plan
Queued: 246.50us, Analysis: 157.79ms, Planning: 84.88ms, Execution: 16.05s
Fragment 1 [SINGLE]
CPU: 15.08s, Scheduled: 15.13s, Blocked 4.41s (Input: 3.59s, Output: 0.00ns), Input: [mask] rows ([mask]), Data Scanned: 0B; per task: avg.: [mask] std.dev.: 0.00, Output: [mask] rows ([mask])
Output layout: [nayose_target_id, tenant_name, row_number]
Output partitioning: SINGLE []
Window[orderBy = [tenant_name ASC NULLS LAST]]
...
Fragment 2 [SOURCE]
CPU: 3.34s, Scheduled: 5.87s, Blocked 1.58s (Input: 0.00ns, Output: 1.58s), Input: [mask] rows ([mask]), Data Scanned: [mask]; per task: avg.: [mask] std.dev.: 0.00, Output: [mask] rows ([mask])
Output layout: [nayose_target_id, tenant_name]
Output partitioning: SINGLE []
TableScan[table = awsdatacatalog:tomita:bucketed_part_nayose_targets buckets=10]
...
上記から実行時間、CPU処理時間の改善を確認できます。複数回実行した結果、バケット化されていない場合と比較して、バケット化されている場合は2.5~3.5秒ほど早いことが確認できました。
改めて全データに対してクエリ実行してみます。
CREATE TABLE "bucketed_nayose_targets" WITH ( format = 'parquet', external_location = 's3://test/bucketed_nayose_targets/', bucketed_by = ARRAY['tenant_name'], bucket_count = バケット数 ) AS SELECT * FROM nayose_targets ; SELECT ROW_NUMBER() OVER(ORDER BY tenant_name) AS job_execution_id, nayose_target_id, tenant_name FROM bucketed_nayose_targets
結果は同じエラーが出てしまいました。
バケット数については、いくつかのバリエーションを試しましたが、いずれも結果は変わりませんでした。この方法で対応するのは難しいと判断し、別方法の検討に切り替えます。
クエリを最適化する
今回、ソート処理対象が多いためにクエリが失敗しました。
以下クエリの場合、全件を対象にソートしています。
SELECT ROW_NUMBER() OVER(ORDER BY tenant_name) AS job_execution_id, nayose_target_id, tenant_name FROM nayose_targets
なので、ソート対象を減らす方法を考えてみます。
テーブルのイメージと合わせて説明します。
以下のnayose_targetsテーブルがあるとします。
| nayose_target_id | tenant_name |
|---|---|
| 441 | Yonyon |
| 331 | Sansan |
| 551 | Gogo |
| 552 | Gogo |
| 442 | Yonyon |
| 553 | Gogo |
テナントは3個、それぞれ以下の名寄せ対象数を持っているとします。
- Sansanは1個
- Yonyonは2個
- Gogoは3個
2つの補佐テーブルを利用することで実現を試みます。

ソートキーによる集計結果テーブルの利用:
ソート処理対象を分割して、最後に結果を統合できればよさそうです。クエリが処理失敗しない「複数テナントを束ねた範囲(以降「テナントグループ」と呼ぶ)」ごとにソートを行うことを考えます。そして、最後にそれぞれのソート結果を統合することで「テナント単位でソートした結果」は取得できます。
オフセットテーブルの利用:
次にジョブ実行IDの実現方法について考えてみます。まず自明なのは「テナントグループ内であればIDを振れる」ということです。テナントグループを跨ってIDを振るにはどうしたらいいか考えてみます。これは「手前のテナントグループからのオフセット値」があれば算出できます。
それぞれの対応について、詳しく説明します。
ソートキーによる集計結果テーブルの用意
ソート処理を分割して実行するためにはnayose_targetsテーブルに「ソートキー(tenant_name)の集計結果」を持たせる必要があります。そのテーブルをtenantsテーブルとします。
以下にテーブルのイメージを載せます。
| tenant_name | nayose_target_count | tenant_group_id | tenant_sort_id |
|---|---|---|---|
| Sansan | 1 | 1 | 1 |
| Yonyon | 2 | 1 | 2 |
| Gogo | 3 | 2 | 1 |
nayose_target_count(テナントごとの名寄せ対象数)は、後述するオフセットテーブル作成時に利用します。tenant_group_id(テナントグループID)は、分割後のソート実行単位になります。分割方法としては、名寄せ対象数を設定値(上記の例だと3)の除算結果ごとに振り分けています。tenant_sort_id(テナントソートID)は、テナントグループ内でのテナントの順序性を担保するための値になります。
算出クエリは以下になります。
CREATE TABLE "tenants" WITH ( format = 'parquet', external_location = 's3://test/tenants/' ) AS ( WITH tenant_nayose_target_counts AS ( -- テナントごとの名寄せ対象数を求める SELECT tenant_name, COUNT(1) AS nayose_target_count FROM nayose_targets GROUP BY tenant_name ), tenant_nayose_target_cumulative_sums AS ( -- テナントごとに名寄せ対象数の累積和を求める SELECT tenant_name, nayose_target_count, SUM(nayose_target_count) OVER(ORDER BY RANDOM()) AS nayose_target_cumulative_sum FROM tenant_nayose_target_counts ), grouped_tenant_nayose_target_counts AS ( -- 名寄せ対象数の累積和を使ってテナントグループに分ける SELECT tenant_name, nayose_target_count, nayose_target_cumulative_sum / 分割する名寄せ対象数(今回の例であれば 3)+ 1 AS tenant_group_id FROM tenant_nayose_target_cumulative_sums ) SELECT tenant_name, nayose_target_count, tenant_group_id, ROW_NUMBER() OVER(PARTITION BY tenant_group_id ORDER BY RANDOM()) AS tenant_sort_id FROM grouped_tenant_nayose_target_counts )
オフセットテーブルの用意
その次に、tenantsテーブルからオフセットテーブル(tenant_group_offsetsテーブル)を作成します。
このテーブルは、テナントグループを跨いだジョブ実行IDを求めるために使います。テナントグループ内のソート結果に付与するシーケンス番号は、そのままの値を使うとテナントグループを跨いだ際にリセットされてしまうため、このオフセット値を足すことで対応します。
以下にテーブルのイメージを載せます。
| tenant_group_id | offset |
|---|---|
| 1 | 0 |
| 2 | 3 |
算出クエリは以下になります。
CREATE TABLE "tenant_group_offsets" WITH ( format = 'parquet', external_location = 's3://test/tenant_group_offsets/' ) AS ( WITH tenant_group_nayose_target_counts AS ( -- テナントグループごとの名寄せ対象数を求める SELECT tenant_group_id, SUM(nayose_target_count) AS nayose_target_count FROM tenants GROUP BY tenant_group_id ), tenant_group_nayose_target_cumulative_sums AS ( -- テナントグループごとに名寄せ対象数の累積和を求める SELECT tenant_group_id, SUM(nayose_target_count) OVER(ORDER BY tenant_group_id) AS nayose_target_cumulative_sum FROM tenant_group_nayose_target_counts ) SELECT tenant_group_id, COALESCE(LAG(nayose_target_cumulative_sum, 1) OVER(ORDER BY tenant_group_id), 0) AS offset FROM tenant_group_nayose_target_cumulative_sums )
上記テーブルを利用して結果取得
そして最後に、上記テーブル(nayose_targets, tenants, tenant_group_offsets)を結合して、以下の結果を取得します。
テナントグループ内でテナント単位にソートし、ジョブ実行IDはオフセット値を使って求めます。
以下にテーブルのイメージを載せます。※idの昇順でソートした結果
| job_execution_id | nayose_target_id | tenant_name |
|---|---|---|
| 1 | 331 | Sansan |
| 2 | 441 | Yonyon |
| 3 | 442 | Yonyon |
| 4 | 551 | Gogo |
| 5 | 552 | Gogo |
| 6 | 553 | Gogo |
算出クエリは以下になります。
SELECT tenant_group_offsets.offset + ROW_NUMBER() OVER(PARTITION BY tenants.tenant_group_id ORDER BY tenants.tenant_sort_id) AS job_execution_id, nayose_targets.nayose_target_id, nayose_targets.tenant_name FROM nayose_targets INNER JOIN tenants ON nayose_targets.tenant_name = tenants.tenant_name INNER JOIN tenant_group_offsets ON tenants.tenant_group_id = tenant_group_offsets.tenant_group_id
こちらのクエリで無事結果を取得できました 🎉
まとめ
ソート処理がボトルネックとなるAthenaクエリの改善方法について紹介しました。
Athenaは気軽に大量データを処理できて便利です。ただ、クエリ内容によっては今回のように検討が必要な場合があります。
今回のクエリ最適化の過程を振り返ってみると、分割統治の考え方(問題を小問題に分割して解く)に沿って検討を進めていたと感じています。最初のクエリは、全体をまとめてソート対象としていました。それをソート可能かつソート要件を満たす範囲に分割することで解決し、最終的にそれらを統合することで期待する結果を得ました。基本的な考え方ではありますが、その汎用性を改めて実感しました。
本記事がパフォーマンスチューニングする際の参考になったら幸いです。
Nayoseグループが所属するデータ戦略部門では、エンジニアを募集しています。もし少しでもご興味を持っていただけましたら、以下も併せて確認していただければと思います。
最後まで読んでいただきありがとうございました。