はじめに
研究開発部の小松です。
本記事は Sansan Advent Calendar 2022 の17日目の記事になります。
普段こちらのブログではネットワーク経済学をテーマに細々と書いています。今回は少し話題を変えて、日頃の分析でお世話になっている R のパッケージ {targets} に (半年ぐらい前になりますけれど) OSSコントリビュートした話をします。
普段の業務では Python と R 両方使っていますが、素早い対応が求められる分析業務では私は R を使っています。{tidyverse} によるデータハンドリングに慣れた身からすると、pandas での処理はまどろっこしく感じられて未だに慣れません。*1
その R を用いた分析の生産性を向上に大きく寄与しているのが、1年程前に使い始めた {targets} です。以下の記事にも、研究開発部の R ユーザーが {targets} を普段の分析で活用していることに触れました。
{targets} とは?

{targets}は分析者のためのパイプラインツールです。
データ分析における基本的なワークフローは以下の図に要約されます。
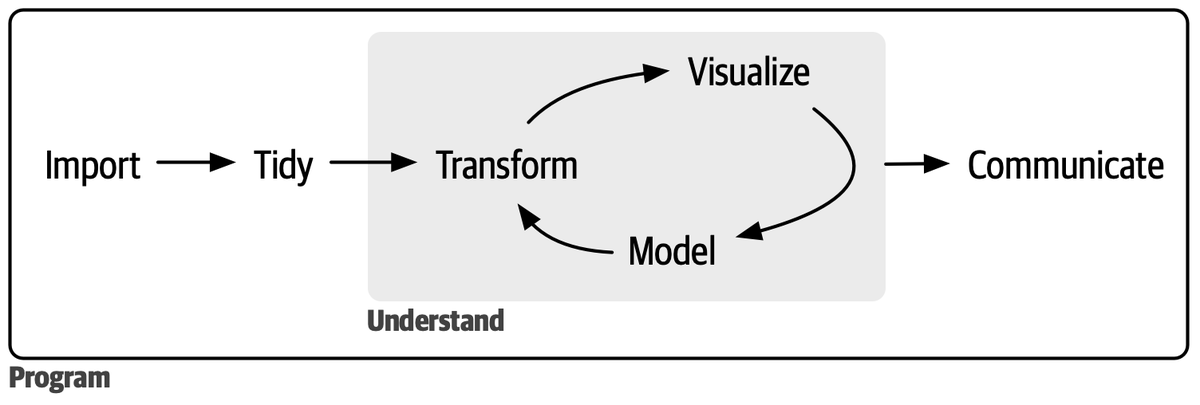
つまり、データを取得し、「整然」データに直し、分析できる形に整形し、分析・可視化を行うというものです。
しかし実際の分析では、このモデルが示す通りスムーズに進むものではありません。元データを取得し直したり、データの加工手順を変えたり、分析で異なる specification を試したりと、各作業間の往来を繰り返します。
{targets} はその試行錯誤の過程で、パイプラインの依存関係を記録し、変更が加えられたときに必要な計算のみを実行してくれます。例えば、線形回帰分析で違う specification を試す場合は、その手前のデータの取得・加工については計算を再実行しなくてよいはずです。{targets} でパイプラインを構築しておけば、そのデータ取得・加工の部分は実行時に自動的にスキップされます。
具体的な例を見ましょう。R project を立ち上げて、そのルートディレクトリに _targets.R を作成します。詳細は省くとして、{targets} におけるパイプラインの書き方の一例は以下の通りです。分析の中身は適当です。
library(targets) list( tar_target(raw_data, cars), tar_target(cleaned_data, cars |> dplyr::mutate(dist_squared = dist^2)), tar_target(reg, lm(speed ~ dist, data = cleaned_data)) )
そしてこのパイプラインを実行します。コンソールから以下のコマンドを実行します。
tar_make()
• start target raw_data • built target raw_data [0.001 seconds] • start target cleaned_data • built target cleaned_data [0.15 seconds] • start target reg • built target reg [0.005 seconds] • end pipeline [0.234 seconds]
うまくいきました。回帰分析の結果は、例えば tar_read(reg) とすれば読み込むことができます。
もう一度 tar_make() でこのパイプラインを実行してみます。
✔ skip target raw_data ✔ skip target cleaned_data ✔ skip target reg ✔ skip pipeline [0.068 seconds]
ご覧の通り、前回の実行から各パイプラインの構成要素 (target と呼ばれています) に変更がないため、全てスキップされました。
ここで、回帰分析の specification を少し変えて再実行してみます。
list( tar_target(raw_data, cars), tar_target(cleaned_data, cars |> dplyr::mutate(dist_squared = dist^2)), tar_target(reg, lm(speed ~ dist + dist_squared, data = cleaned_data)) )
✔ skip target raw_data ✔ skip target cleaned_data • start target reg • built target reg [0.005 seconds] • end pipeline [0.078 seconds]
すると、reg のみが実行されていますが、その手前の処理はスキップされています。手前のデータ処理のタスクはキャッシュされており、それを利用することで計算を省略できているわけです。
{targets} を上手に活用すればデータ分析の試行錯誤において、無駄な処理時間の待ち時間を減らしたり、再現性の保証を容易にしたりすることが可能となります。
また昔自分が行った分析を再び回そうとして、どのコードから手をつければよいか路頭に迷った経験はありませんか。
過去に自分が書いたコードをたとえ忘れたとしても、{targets} を使ってその分析をパイプラインにしておくと、最低限分析の再現はできるという安心感が生まれます。
より詳細を知りたい方は、マニュアルページの Walkthrough に触れていただくのが良いかと思います。
日本語では、R でおなじみの Shinya Uryu さんの資料がコンパクトで大変分かりやすいです。
キャッシュをクラウドストレージに連携する
この {targets} の肝の1つは、各計算結果をキャッシュすることによる効率化です。キャッシュされたファイルは、デフォルトでは _targets/objects/ 以下に置かれます。
そのキャッシュファイルの保存先として、AWS S3 や GCP Cloud Storage を指定することが可能です。以下の設定は一例です。
tar_option_set( resources = tar_resources( aws = tar_resources_aws( bucket = "your-bucket-name", prefix = "your_project/_targets/objects" ) ), repository = "aws" )
こうすることで、ローカルストレージの圧迫を防いだり、他の分析者との計算結果の共有をスムーズに行ったりすることができます。
GCP との連携で、User Authentication も使えるようにする
普段の分析では AWS S3 を {targets} のキャッシュの保存先として利用しているのですが、分析によっては GCP の Cloud Storage を使った方が便利なケースも増えてきました。
{targets} は GCP との連携もサポートされているとのことでしたので、早速マニュアルに従い連携を試みました。ところが上手くいきません。
その原因を探ったところ、{targets} のGCPの認証が Service Account による認証のみを受け付けている実装になっているからだということがわかりました。
つまり、Service Account を発行して、JSONの鍵を取得し、それを用いて認証する方法です。
しかしこれは個人ごとに Service Account の発行が必要になりますし、自分のユースケースでは Service Account 程の権限は必要ありません。
そこで User Account として認証を行いたいのですが、その時点の {targets} の実装ではうまくいかなそうでした。
そこで {gargle} というパッケージの関数を用いて認証を行う実装を提案しました。そうすることで、Service Account としてだけでなく、User Account としても認証を行うことが可能になります。
結果私の提案が受け入れられ、pull request がマージされました。私としては初めての OSS contribution でした。普段自分が愛用しているパッケージである分、小さいながらも貢献できたことに喜びを感じます。*2
終わりに
{targets} はデータ分析をサポートする機能が数多く搭載されており、私もそれを使った分析のベストプラクティスを日々模索しています。機会があればその辺りを深入りできればと思います。