
技術本部 研究開発部 Architectグループの島です。見習い12年目です。
今回は、当社のデータ化技術の粋である「NineOCR」について、そのインフラ・デプロイの基盤を刷新したお話をします。NineOCRに関しては、以下の記事などをご参照ください。 buildersbox.corp-sansan.com
ということで「NineOCR」をテーマに以下の2回に分けて記事にする予定です。今回は前編、技術選定の過程です。
- 前編: 技術選定の過程
- 後編: GCEにおけるサービスの基盤を変更
タイトルに「刷新」と華々しく書いていますが、プランが二転三転した末の着地だったりします。本記事である技術選定編の結論を先に言ってしまえば、結局インフラは変えないことになりました。きっとこの過程が何らか役立つこともあろうかと思い、ここに記します。
ただし終わってみれば、出来上がりには満足しています。良い意味で「枯れた」技術だけで構成でき、単純明快な構成で使い勝手も良く、Compute Engineで十分戦えることが示されました。
対象システムについて
本記事で話題とするNineOCRについて、従来の構成を示します。
大前提として、NineOCRは Google Cloud に構築しています。当社のデータ化システムの大半は Amazon Web Services (AWS) 上にあるため、クラウドをまたいでNineOCRへとリクエストしています。*1
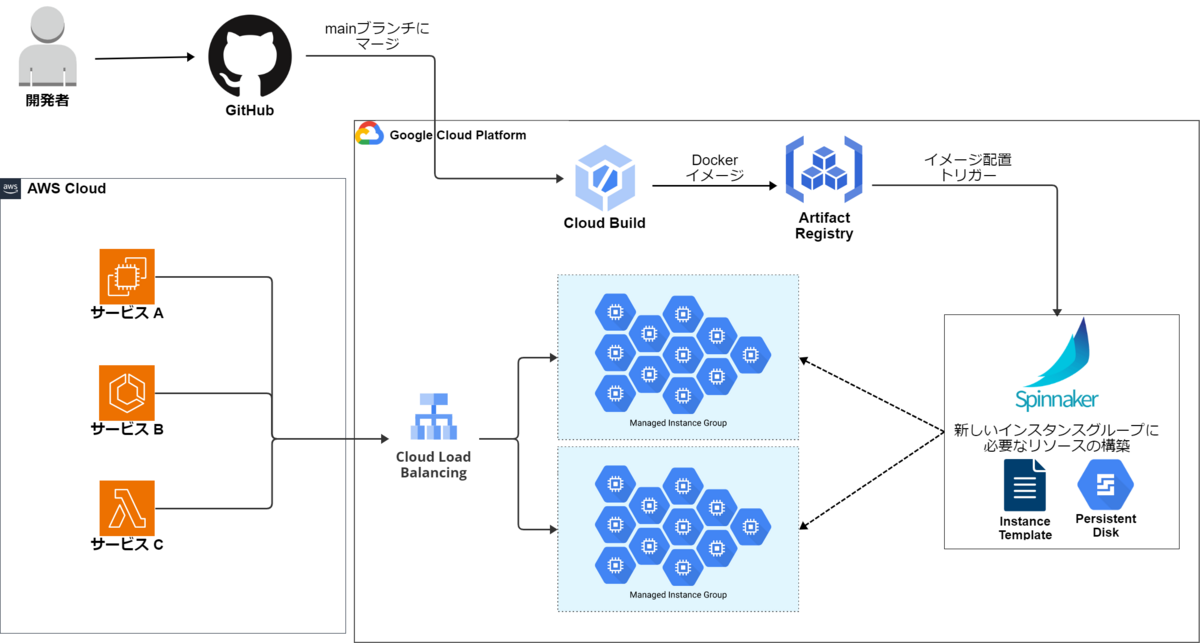
- NineOCRは Google Compute Engine(GCE) インスタンスで稼働します。インスタンスグループを定義し、その設定によってスケール調整などを行います。ロードバランサにはインスタンスグループ単位でぶら下げています。
- 図でインスタンスグループが2個ぶら下がっているのは、デプロイ途中で旧バージョンと新バージョン双方が稼働している状態を示しています。普段は1個のインスタンスグループのみが存在します。
- 個々のGCEインスタンスには、GPUを追加しています。N1インスタンスにアクセラレータを追加している格好です。
- アプリケーションは、付随するファイル・Dockerイメージやミドルウェアなどともども、特定のカスタムイメージ・カスタムインスタンスグループとして固めます。この処理は Continuous Delivery(CD)の一環としてCloud BuildとSpinnakerが担います。インスタンス内にて docker run することでアプリケーションが稼働します。
従来のデプロイの流れ
新しいバージョンをデプロイする際は、以下の流れをたどっていました。
- アプリケーションをコード管理するGitHubにて、main(master)ブランチにマージする。
- マージによってCloud Buildが発火。Cloud BuildワークフローによってアプリケーションをDockerイメージとして固める。
- Cloud Buildは、作成したDockerイメージを Artifact Registry にpushする。*2
- Artifact RegistryへのpushによりSpinnakerが発火。Spinnakerが以下のワークフローを処理する。
- 直前のデプロイ時のインスタンスイメージを元に、テンポラリのGCEインスタンスを立ち上げる。そのインスタンス内部で、ミドルウェアなどのアップデートや、新しいアプリケーションのDockerイメージ取得を行い、内部を最新の状態にする。
- 上記の状態でインスタンスイメージを抽出したのち、テンポラリのGCEインスタンスを削除する。
- 作成した新しいインスタンスイメージを関連付けて、インスタンスグループを作成する。
- 新しいインスタンスグループで最大台数のインスタンスを立ち上げ、ロードバランサに接続する。
- 古いインスタンスグループをロードバランサから接続解除し、削除。
先に結論を述べますと、今回の刷新では最終的に、上の太字になっている箇所を変更しました。
課題
NineOCRを開発している研究員(機械学習エンジニア)から、カナリアリリースをしたいという要望があがりました。究極の認識精度を求めてモデルの改善を繰り返していますが、最後の最後は実地で動かしてみないとわからないものです。新しいモデルに急に100%切り替えるのではなく、例えばほんの5%程度流してみて様子を見たいという背景です。
デプロイの制御は前述のようにSpinnakerワークフローが行っていますので、カナリアリリースの実現にはSpinnakerの改修が求められました。いったんはそれをやり遂げたのですが、メンテナンス性・拡張性に課題がありました。課題の一例として、作成したワークフローは処理が最後まで成功する前提で組んでおり、もし問題があって巻き戻したいときは手作業でロードバランサなどの設定を変更することになる点があります。Spinnakerのまま各種問題に向き合っていくことに限界を感じ、なにか別の仕組みがないか、探してみることにしました。
ここで補足すると、移行の理由として、「Spinnakerそれ自体に問題がある」という比重は小さいと考えています。このNineOCR向けのデプロイ機構は私が途中から引き継いだのもあって、全体の俯瞰が難しかったり、設定ファイルがコード管理無く随所に散らばったり、アクティブに面倒を見ていた者が不在であったりと、運用上の問題が大きいです。SpinnakerはどちらかというとGKEでの運用例が巷に多いようで、また調べると確かに少々古い記事に当たりやすいですが、それでも最前線で活用している例は見かけます。
変更先の選択肢
デプロイ機構だけの刷新にこだわらず、インフラ自体を変更することも選択肢に入れました。GCEを使う現状について、「VMを自分で管理する」なんてこのご時世ではイケていない、という後ろめたさがあり、むしろ積極的に「今風」なインフラへの変更を視野に入れました。そうすれば、おのずとデプロイ機構も刷新されて一挙両得のはずでした。結果的には、この背伸びで挫折したわけですが。
AWS または Google Cloud の範疇で、以下の選択肢が挙がりました。
- AWS
- Google Cloud
これらいずれも、個々のインスタンスを意識する必要が減る「ナウい」案だと思ったのですが、すべてを検討した結果、不採用になりました。以下、その経過を記します。
AWS案
SageMaker、ECS、EKSの案がありました。後ろ2つは、Fargateではなくon EC2とすることでGPUを利用可能にします。
AWSを一律不採用にした理由は、コストの問題です。
本件のアプリケーションの稼働に最低限必要な1インスタンスあたりのスペックが以下でした。
- 2 vCPU
- 4GB 前後のメモリ
- 1つの NVIDIA T4 GPU
これに見合うAWSでの構成を考えようとするとき、Amazon EC2のインスタンスタイプは基本的にスペックが決め打ちですから、カタログから近いのを選ぶほかありません。今回は g4dn.xlarge が最も近いであろうと見いだしました。ただしこれはvCPUが4でメモリが16GiBなので、必要に比べ多すぎる問題があります。

かたやGoogle Cloudは、カスタムマシンタイプを選べます。完全に自由自在ではないですが *3、今回の程度であれば問題なくぴったりのスペックでインスタンスを用意できます。
一般的なCPUベースのサービスを組むのであれば、小さいインスタンスを多数用意するなり、大きな少数のインスタンスで稼働させるなり、割と柔軟に変えられます。よってAWSで決め打ちスペックしか選択できない点はそれほどネックになることがないと思いますが、しかし今回の対象(NineOCR)はGPUこそがボトルネックであり、GPUを何個確保できるかということに尽きる点が特異です。CPUやメモリのスペックが余るならその分並列で多数処理させればよい、というわけにいかないのです。
AWSのg4dn.xlargeで2 vCPU、12GiBのメモリの分だけ過剰になるのは、そのままコストに跳ね返ってしまいます。各種割引の具合にもよりますが、Amazon EC2へ素朴に移行すると仮定して、費用を試算したところ現行GCEの1.5倍前後になるようでした。実際に利用するECSにせよEKSにせよEC2を基盤とさせるため、この試算と大差ないと見込みました。
SageMaker Endpointは、インスタンス費用はEC2に比べて元々割高ゆえ、さらに採用が難しくなりました。例えば2024年4月現在で、東京リージョンのオンデマンドにてEC2の g4dn.xlarge では $0.71/時 のところ、SageMakerの ml.g4dn.xlarge は $0.994/時 で、1.4倍ほど高額です。便利にしてくれている分のマージンですね。
当部門には、「Circuit」と呼んでいる、EKSで構築したサービス基盤があります(以下記事など参照ください)。もしAWSに移行可能であれば、このCircuit基盤に載せることで各種使い勝手の刷新も図れます。しかしそれは以上で述べたコストの問題のため頓挫することになりました。このAWS移行検討にあたっては、AWSの方にもあれこれ相談に乗っていただきました。感謝申し上げるとともに、結局果たせなかった点を申し訳なく思います。 buildersbox.corp-sansan.com
「大部分AWSを利用しながら、なぜ一部だけGoogle Cloud?」という疑問はいま読者の皆さまもお持ちでしょうし、社内のメンバーからでさえよく聞かれます。過去にそうなった理由は1つではないのですが、今回のコストの検討を経て、正しい選択だったのだと再認識することになりました。
Google Cloud案
さて、以上からAWSへの移行が難しいということになり、Google Cloud残留案が有力になりました。しかしCompute Engineのままでは終われないと思っていたので、 GKEまたはVertex AIを検討しました。
ここで頭を悩ませたもう1つの譲れない要件は、GPUインスタンスの確実な確保です。
本件のNineOCRは社内データ化フローにおいてもはや欠かせない、最重要システムの1つになっています。その安定稼働を阻む問題があります。GPUインスタンスの確保失敗です。Google Cloud側でのGPU需要逼迫などの理由により発生することがあります。NineOCRは非同期(バッチ)ではなくリアルタイム推論を行うサービスであるため、GPUの空きができるまでしばらく待ってからまた試すという悠長な手は使えません。
この対処のため、Compute Engineでの運用ではオートスケールを事実上無効にして、最大瞬間風速に耐えられる最大時の台数を固定で確保して運用しています。最大限スケールアウトするときの台数で「予約」を行うことで、GPU確保を必ず成功させます。予約をすると、インスタンスが停止していようとも課金されるため、スケールする意味がないわけです。*4
従って、GKEやVertex AI案でも、「予約」相当のリソース保証を付けたいと考えました。しかし、Vertex AIのリソース予約はできないとの情報でした(2023年12月にGoogle Cloudサポートに確認)。
GKE Standard や Autopilot では、本記事の執筆時現在ではできそうな情報が見つかりました。ただし私が検討した時点(2023年末)では、 Autopilot のほうは難しいという判断をしました。以下のリファレンスを当時見つけられなかったのか、まだなかったのか定かではないですが、いずれにせよ情報不足のため進めるのが難しい(タイパが悪い)と考えました。Standardの方は当時から可能と見込みましたが、Kubernetesの知見が少ない中でGKE Standardのクラスタを1から構築・運用していくのに尻込みしました。いまCompute Engineでも普段問題なく運用できている中で、元々今回成し遂げたかったデプロイの課題感に比して、これもまた割に合わないかもしれない、と。
移行検討のまとめ
2023年末時点での私の調査の限りであり、間違いがあるかもしれませんし、将来のアップデートにより改善するかもしれません。
| 案 | コスト | 技術難易度 *5 | GPU予約可 |
|---|---|---|---|
| Amazon SageMaker | × | 易 | × |
| Amazon EC2 (ECS, EKS) | × | 普通 | 〇 |
| GKE Autopilot | 〇 | 難? *6 | 〇? |
| GKE Standard | 〇 | 難 | 〇 |
| Vertex AI | △ | 易 | × |
| (参考) Compute Engine | 〇 | 普通 | 〇 |
Compute Engine 残留案へ
以上から、「AWSではコストが見合わない」「Google Cloudで刷新するならGKE方面になり、技術的に可能そうではあるが、工数がかかりそう」だと判断しました。今でも完全にGKE案をボツにしたわけではなく、おそらく本当はベストなのだろうとは思っています。しかしいったんは脇に置いておき、「Compute Engineのままで、デプロイ(CD)の課題を解決する最短ゴールはないだろうか?」という方向で考え始めました。
こうしてふりだしに戻ってしまいました。次回の記事では、Compute Engineに備わった機能だけでデプロイの問題が解決できた詳細について述べたいと思います。
*1:異種クラウドを併用している経緯は、長くなるので割愛します。
*2:正確には、この従来構成時点ではContainer Registryを使用していました。退役のアナウンスがあるため、今回の刷新のついでに Artifact Registryへと移行しています。話の本筋ではないので、区別せずArtifact Registryとして記述しています。
*3:例えばあまりにvCPUとメモリのバランスが悪いような構成にはできない
*4:「予約」についてAWSで近いサービスは On-demand Capacity Reservations です。なお、AWSにおける Reserved Instances に相当すると思われる 確約利用割引 でもリソースを確保可能です(確約利用割引を契約すると、対応する「予約」が自動的に作られます)。
*5:客観的にというよりは、当部門にとって。
*6:GPUの保証をしないなら普通?