はじめに
データ戦略部門の松本です。 1年の各月の季節を漢字で表すと「冬冬春春夏夏夏夏夏夏秋冬」と感じるくらい最近暑いですね。5月なのに真夏日も出ており、秋が好きな私としてはとても残念な気持ちを持っています。今年も暑くなりそうなので、体調に気をつけて過ごしていきたいです。
今回はRxJSやstream処理について失敗から学びを得ましたので、その知見を共有します。
サマリ
- 読み込みよりも書き込みが遅い、バックプレッシャー が必要な領域ではRxJSを使うべきではない
- ReactiveXがオーナーのライブラリであるIxJSを使うことで、I/O周りの処理においてRxJSと同等の記載内容でバックプレッシャー可能
- streamのpipeline APIは非同期ジェネレータをサポートしているので、シンプルな用途であれば必要十分
失敗
私たちのプロダクトではデータを多く扱うため、大量のデータに対してバッチ処理を行うプログラムを書くことがあります。 複雑なデータフローを効率よく実行する目的で、ファイルに対してのバッチ処理を実行するためにRxJSを利用していました。*1
私たちのユースケースの多くは単純に示すと、次のように読み込んだファイルに対して何かしら外部APIを叩いて結果を取得して、その後データベースに行を挿入するというものです。
import { from, concatMap } from "rxjs"; import fs from "fs"; const fileReadStream = fs.createReadStream("large_file.csv"); const observable = from(fileReadStream).pipe( // APIの呼び出しに時間がかかる concatMap((x) => someApiClient.get(x)), concatMap((x) => db.streamingInsert(x)) );
ファイルをチャンクに分割して処理を書くためにNode.jsのstreamの機能を利用していました。それにもかかわらず、プログラムはアウトオブメモリエラーにより異常終了してしまいました。その原因を調査した結果と内容・対策をご紹介します。
Node.jsのstream
Node.jsのstreamにはバックプレッシャーという概念があります。 リアクティブ宣言 によるとバックプレッシャーとは次のような意味を持つ単語です。
処理が追いつかなくなっていて、かつクラッシュすることも許されないならば、コンポーネントは上流のコンポーネント群に自身が過負荷状態であることを伝えて負荷を減らしてもらうべきだ。
今回の事象を例にとると、APIの呼び出しはファイルからの読み出しよりも時間がかかる処理です。バックプレシャーの仕組みが存在しない場合、ファイルの読み込みが先行して行われ、読み込まれたデータはAPI呼び出しを待つ間「メモリ上」に展開されてしまいます。これによりアウトオブメモリエラーが発生してしまいます。
一方バックプレッシャーの仕組みが存在する場合、API呼び出し用に確保されたメモリ(バッファ)の上限に達した際に、バッファがいっぱいである旨をファイルの読み込み処理に対して通知します。ファイルの読み込み処理は、API呼び出しのバッファーに余裕ができるまでファイルの読み込みを中断することでメモリの使用量を削減します。
streamにはバックプレッシャーの仕組みが存在しているにもかかわらずなぜアウトオブメモリになったのでしょうか。もう少し見ていきます。
nodesource.com のこの記事から、次のことがわかります。
- streamを利用することで、ファイルをチャンク(chunk)に分割して読み込むため、メモリ上にすべての内容を保持する必要がない
これは、私たちがstreamを選定した理由に合致しています。 ただし、同記事をさらに読み進めていくと次のような記述があります。
- Readable streamには2つのモードがある
- flowing モード : データを自動的に読み取って、EventEmitterのインターフェイスでイベントを素早く送信する
- paused モード : streamからデータを読み出すために stream.read() メソッドを明示的に読み出す必要がある
この辺りが怪しそうです。深掘りしていきましょう。
streamの2種類のモード
Node.jsのドキュメント によると、 stream#readableFlowing を確認することで現在streamがどのモードで起動しているか確認できます。各種操作を行った状態でのstreamのモードを次のプログラムで検証しました。(Node.js 20.11.0で実行しています)
import fs from "fs"; import { pipeline } from "stream/promises"; const nothing = () => {}; const rs = () => fs.createReadStream("test.ts"); const ws = () => fs.createWriteStream("/dev/null"); // 0. default const s0 = rs(); console.log("s0: ", s0.readableFlowing); // 1. use data event handler via on method const s1 = rs(); s1.on("data", nothing); console.log("s1: ", s1.readableFlowing); // 2. use data event handler via addListener method const s2 = rs(); s2.addListener("data", nothing); console.log("s2: ", s2.readableFlowing); // 2a. attatch other than data event handler const s2a = rs(); s2a.addListener("readable", nothing); console.log("s2a: ", s2a.readableFlowing); // 3. resume stream const s3 = rs(); s3.resume(); console.log("s3: ", s3.readableFlowing); // 4. pipe stream const s4 = rs(); s4.pipe(ws()); console.log("s4: ", s4.readableFlowing); // 5. pipeline stream const s5 = rs(); pipeline(s5, ws()); console.log("s5: ", s5.readableFlowing); // 6. pause stream const s6 = rs(); s6.pause(); console.log("s6: ", s6.readableFlowing); // 7. async iterator const s7 = rs(); const it = s7[Symbol.asyncIterator](); it.next(); console.log("s7: ", s7.readableFlowing);
これらの結果をまとめたものが次の表です。
| 番号 | 処理 | 結果 |
|---|---|---|
| s0 | stream生成直後 | null |
| s1 | onメソッドでdataイベントのイベントハンドラを登録 | flowing |
| s2 | addEventListenerでdataイベントのイベントハンドラを登録 | flowing |
| s2a | dataイベント以外のイベントのイベントハンドラを登録 | paused |
| s3 | resumeを呼び出し | flowing |
| s4 | pipeでstreamを結合 | flowing ⭐️ |
| s5 | pipelineでstreamを結合 | flowing ⭐️ |
| s6 | pauseを呼び出し | paused |
| s7 | 非同期イテレータでデータを読み出す | paused |
⭐️の部分に関しては、起動時はflowingモードだが内部実装上メモリの使用量を監視してpausedモードとflowingモードとを切り替えるようになっています。詳細はヤフー様のテックブログに詳しく解説されておりますのでご参照ください。 techblog.yahoo.co.jp
これらの調査から次のことがわかりました。
dataイベントのイベントハンドラを登録すると flowing モードになること- 非同期イテレータでデータを読み出した場合は paused モードになること
- pipeメソッドや pipeline APIでは起動時は flowing モードであるが、メモリの使用量を監視してflowingとpausedモードを切り替えバックプレッシャーを実現していること
RxJSでの実装
では、改めてRxJSにおけるReadable streamからObservableを作成する部分の実装を追ってみます。
Readable streamはEventEmitterでもあるため、次の2通りの実装が考えられます。
// EventEmitterとして扱う const observable = fromEvent(readableStream, "data"); // readable streamとして扱う const observable = from(readableStream);
fromEvent
実装は次のリンク先に示す箇所です。 https://github.com/ReactiveX/rxjs/blob/9c8fa65ea161f97cc90ea9b4679b0ae104a29ffb/packages/rxjs/src/internal/observable/fromEvent.ts#L262-L292
プログラムの要点を抜き出すと次のようになります。
export function fromEvent(target, eventName) { return new Observable((subscriber) => { // 単純にsubscriber.nextを呼ぶのみ const handler = (...args: any[]) => subscriber.next(args); target.addEventListener(eventName, handler); }) }
これは上で見た通り、イベントハンドラをそのままつなぐ実装であり、flowingモードで起動されるためアウトオブメモリを発生させそうな実装であることが分かります。
from
こちらの実装は次の部分です。 https://github.com/ReactiveX/rxjs/blob/9c8fa65ea161f97cc90ea9b4679b0ae104a29ffb/packages/observable/src/observable.ts#L1183-L1203
こちらもプログラムの要点を抜き出すと次のようになります。
export function from(readableStream) { return new Observable((subscriber) => { for await(const value of readableStream) { subscriber.next(value); } }) subscriber.complete(); }
上で見た内容に準ずると、非同期イテレータを利用して内容を読み出しているため、streamはpausedモードで起動していそうです。ただし、subscriber.next(value) を同期的に呼び出しているため、せっかくのpausedモードですが値を無限にpushする構成になっています。
パフォーマンス検証
実際に検証用のプログラムを用意し、パフォーマンスを測定しました。
▼ fromEventのパフォーマンス測定用のプログラム:
import { fromEvent, concatMap, takeUntil } from "rxjs"; import fs from "fs"; const readableStream = fs.createReadStream("large_file.csv"); const sleep = (ms) => new Promise((resolve) => setTimeout(resolve, ms)); const obs = fromEvent(readableStream, "data").pipe( concatMap(async (data) => { await sleep(10); console.log(JSON.stringify(process.memoryUsage())); return data.toString(); }), takeUntil(fromEvent(readableStream, "end")) ); await new Promise((resolve) => { obs.subscribe({ complete: resolve, }); });
fromEventのメモリ使用量の測定結果
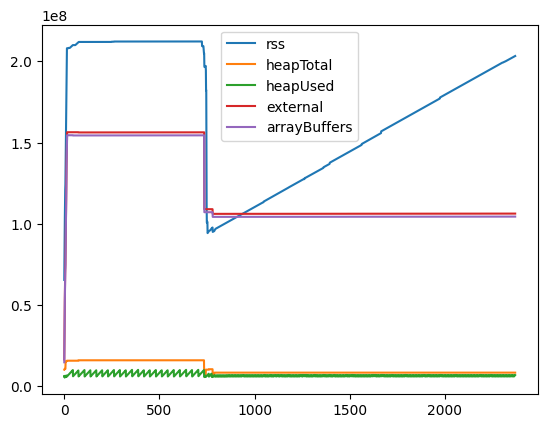
▼ fromのパフォーマンス測定用のプログラム:
import { from, concatMap } from "rxjs"; import fs from "fs"; const readableStream = fs.createReadStream("large_file.csv"); const sleep = (ms) => new Promise((resolve) => setTimeout(resolve, ms)); const obs = from(readableStream).pipe( concatMap(async (data) => { await sleep(10); console.log(JSON.stringify(process.memoryUsage())); return data.toString(); }) ); await new Promise((resolve) => { obs.subscribe({ complete: resolve, }); });
fromのメモリ使用量の測定結果
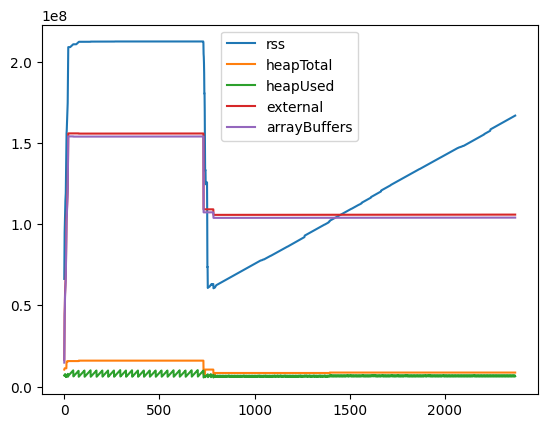
検証に利用したファイルは約150MBのcsvでしたが、arrayBuffersに約150MB割り当てられており、ファイルの中身がすべてメモリ上に読み込まれていることが分かります。
IxJS
今まで見てきた通り、RxJSではファイルをstreamで取得したとしても内部の実装ですべてメモリにため込んでしまうため、アウトオブメモリが発生する状態です。 そこで代替のライブラリを調査したところ、同じくReactiveXから IxJSというライブラリが公開されていました。
GitHub - ReactiveX/IxJS: The Interactive Extensions for JavaScript
READMEに記載されているIxJSについての内容を引用します。
The Interactive Extensions for JavaScript (IxJS) brings the Array#extras combinators to iterables, generators, async iterables and async generators. With the introduction of the Symbol.iterator and generators in ES2015, and subsequent introduction of Symbol.asyncIterator and async generators, it became obvious we need an abstraction over these data structures for composition, querying and more.
IxJS unifies both synchronous and asynchronous pull-based collections, just as RxJS unified the world of push-based collections. RxJS is great for event-based workflows where the data can be pushed at the rate of the producer, however, IxJS is great at I/O operations where you as the consumer can pull the data when you are ready.
まとめると次のような説明です。
- IxJSはpull basedのコレクションである(一方RxJSはpush basedのコレクション)
- IxJSは I/O操作に適しており、コンシューマが準備できた時にデータをプルして操作する
以下、公式のサンプルコードからの引用ですが、用意されているAPIはRxJSとほとんど同じであるため、RxJSに慣れた方であればIxJSの切り替えもほとんどコストがかからないと思われます。
// ES import { from } from 'ix/asynciterable'; import { filter, map } from 'ix/asynciterable/operators'; // CommonJS const from = require('ix/asynciterable').from; const { filter, map } = require('ix/asynciterable/operators'); const source = async function* () { yield 1; yield 2; yield 3; yield 4; }; const results = from(source()).pipe( filter(async x => x % 2 === 0), map(async x => x * x) ); for await (let item of results) { console.log(`Next: ${item}`); } // Next 4 // Next 16
パフォーマンス
IxJSにもRxJS同様、 from というAPIがあります。このAPIもRxJSと同様、引数に非同期イテレータを指定でき、その結果からIxJSのイテレータを作成します。
実装の要点は次に示す通りです。
export class FromAsyncIterable { constructor(source: AsyncIterable) { this._source = source } async *[Symbol.asyncIterator]() { let i = 0; for await (const value of this._source) { yield value } } }
ということでそのままですね。 RxJSバージョンと異なり、このクラス自体が非同期イテラブルであり、イテレータ関数で値をyieldする点が大きく異なっています。
このAPIを利用したパフォーマンスを見ていきます。
import { from } from "ix/asynciterable/index.js"; import { concatMap } from "ix/asynciterable/operators/index.js"; import fs from "fs"; const readableStream = fs.createReadStream("large_file.csv"); const sleep = (ms) => new Promise((resolve) => setTimeout(resolve, ms)); const obs = from(readableStream).pipe( concatMap(async (data) => { await sleep(10); console.log(JSON.stringify(process.memoryUsage())); return data.toString(); }) ); for await (const _ of obs) { // noop }
プログラムを動作させて取得したメモリ使用量をプロットしたものが次のグラフです。
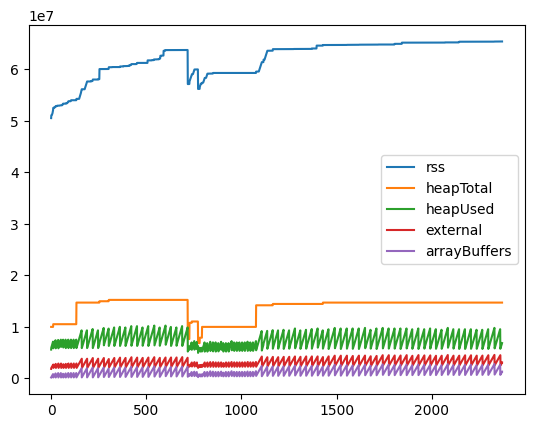
このグラフを見て分かる通り、最大メモリ使用量が約62MBと、RxJSのメモリ使用量と比較しても圧倒的に少ないメモリ使用量です。 arrayBuffersの使用量が特に顕著であり、RxJS版と比較するとIxJS版は最大2.5MBと適切にコントロールされています。
まとめると次のようになります。
| 種類 | 最大メモリ使用量 (150MBのファイルを読み込んだとき) |
|---|---|
| RxJS fromEvent | 202MB |
| RxJS from | 202MB |
| IxJS from | 63MB |
改めて、IxJSのpullベースのアーキテクチャの効果によりメモリの使用量が削減されること、が実験からも示されました。 *2
外部ライブラリに依存しない方法
ここまでIxJSというライブラリを紹介しました。複雑に絡み合ったストリーミング処理を記載する場合はこのライブラリが有用です。しかし、より簡単にstreamをバックプレッシャー付きで扱う方法として次の2種類が見つかったため、合わせて紹介させてください。
pipeline関数に非同期ジェネレータ関数を適用する
Node.jsのドキュメント によると、pipeline関数には非同期ジェネレータ関数をpipelineの構成要素として適用できます。 forkJoinのような複雑な処理はこの構文だけで書くのは難しく、さらなる実装が必要でメリットは少ないと感じました。一方APIを叩いて結果を保存するだけ、のようなシンプルな処理であれば、ライブラリも不要で扱いやすと思われます。 さらには、pipeline関数を用いたstreamの処理方法であるため、適宜バックプレッシャーを管理可能です。
パフォーマンス測定用にサンプルコードを作成しました。以下に示す通り、適切にメモリ使用量がハンドリングされていることが分かります。
import fs from "fs"; import { pipeline } from "stream/promises"; const readableStream = fs.createReadStream("large_file.csv"); const sleep = (ms) => new Promise((resolve) => setTimeout(resolve, ms)); const obs = pipeline( readableStream, async function* (source) { for await (const chunk of source) { await sleep(10); console.log(JSON.stringify(process.memoryUsage())); yield chunk.toString(); } }, async function* (source) { for await (const chunk of source) { // noop } } ); await obs;

Async Iterator helpers
また、現在TC39として Async Iterator Helperが提案されています。
Node.jsにおけるArrayのように、メソッドチェーンの形で非同期イテレータを扱う構文でありとても分かりやすいと感じます。
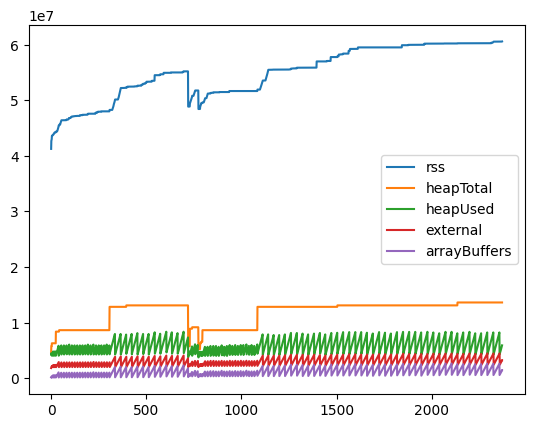
現在提案中であるためNode.jsにはまだ実装されておらず、polyfillを用いて同じようにメモリの使用量を測定しました。結果、適切にチャンクに分割されて処理がされていました。
import fs from "fs"; import { aiter } from "iterator-helper"; const readableStream = fs.createReadStream("large_file.csv"); const sleep = (ms) => new Promise((resolve) => setTimeout(resolve, ms)); const fileIterator = aiter(readableStream); const obs = fileIterator.map(async (data) => { await sleep(10); console.log(JSON.stringify(process.memoryUsage())); return data.toString(); }); for await (const _ of obs) { // noop }
まとめ
- stream APIには2つのモードがある
- RxJSは push型の思想であり、streamから作成したObservableでもバックプレッシャーを無視する
- IxJSは pull型であり、RxJSと共通の文法に加えてバックプレッシャーをケアした記載が可能
- 簡単な処理であれば pipelineに非同期ジェネレータ関数を適用するのが一番お手軽
| 種類 | 最大メモリ使用量 (150MBのファイルを読み込んだとき) |
|---|---|
| RxJS fromEvent | 202MB |
| RxJS from | 202MB |
| IxJS from | 62MB |
| pipeline + 非同期ジェネレータ | 56MB |
| TC39 Async iterator helper | 58MB |
私たちのチームでは Web アプリ開発エンジニアを募集しています。Web アプリ開発だけではなくデータエンジニアリングなど、幅広い業務を経験できます!
*1:昔のRxJSはバックプレッシャーをサポートしていた、という記載 があり、それを信じていた点は反省です。
*2:IxJSにも fromEvent APIがあり、そちらを利用すると(ご想像の通り) 213MBのメモリ使用量になりました。