こんにちは,DSOC R&Dグループ インターン生の内田と申します.昨夏のR&Dインターンにも参加しており,実はSansanのブログのどこかに登場済みです.夏のインターンではデータ分析周りを経験させていただきましたが,大学での専門が画像処理ということもあり,昨年10月から画像分野のインターン生としてお世話になっています. 現在,名刺画像の超解像を業務として担当しておりますので,私自身の勉強も兼ねて,超解像分野のあれこれを数回に分けて触れていければと考えています.また,私は普段ディープラーニングフレームワークとしてTensorFlow*1を使っているのですが,ここではPyTorch*2に入門して実装もしていきます.
超解像とは
超解像とは入力画像の解像度を高めて出力する技術の総称で,端的に言えば画像を大きくする技術です. 画像を拡大して輪郭がギザギザ*3になった経験はみなさんお持ちだと思います. 超解像では,このような拡大時に発生する歪みを抑えながら自然に画像を拡大します.
実際のところ,ギザギザの補正はそこまで難しい問題ではありませんが,解像度が低下した際に発生する歪みは多岐に渡ります.
非常に極端な例ですが,下図のような縦1x横3の灰色画素(輝度値128)を持つ低解像度画像を縦2x横6に超解像することを考えてみましょう.


SRCNN
このように難しい超解像についての研究は, 2000年以前から表示デバイスの高解像度化に伴って盛んに行われており,辞書ベースの手法が一定の成果を上げていました.
一方,畳み込みニューラルネットワーク(CNN)は2012年ごろから様々な画像認識タスクで応用されてはstate-of-the-artを叩き出していました.
そんな折,2014年にDongらがCNNを超解像に応用したSRCNN*4を発表しました.
2014年当時の話ですが,下図のようにピーク信号対雑音比(PSNR)で従来手法に大きく優っており,超解像分野の研究の方向性を大きく変えました.
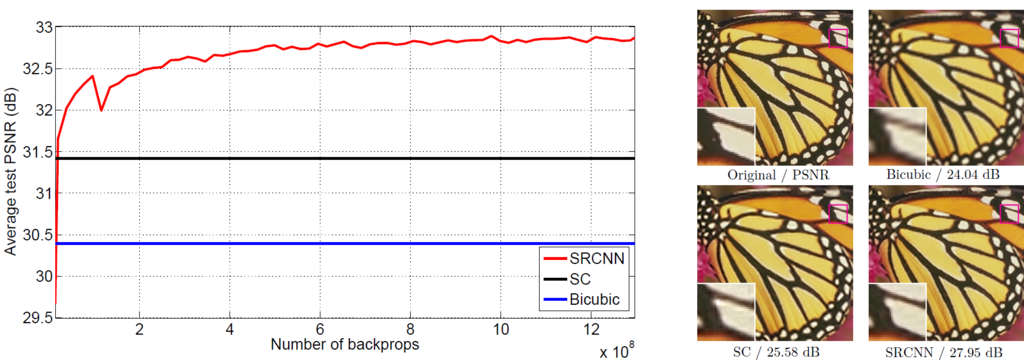
以下では,SRCNNをPyTorchで実装していきます.長くなるので一部省略しますが,コードはGitHubにて公開しておりますので,興味のある方はぜひご参照ください. github.com
モデル
SRCNNは,畳み込み層を3回繰り返す構造をしており,少ない計算量で超解像することができます.
低解像度画像は,事前にBicubic補間で拡大し,出力画像サイズに合わせて入力します.
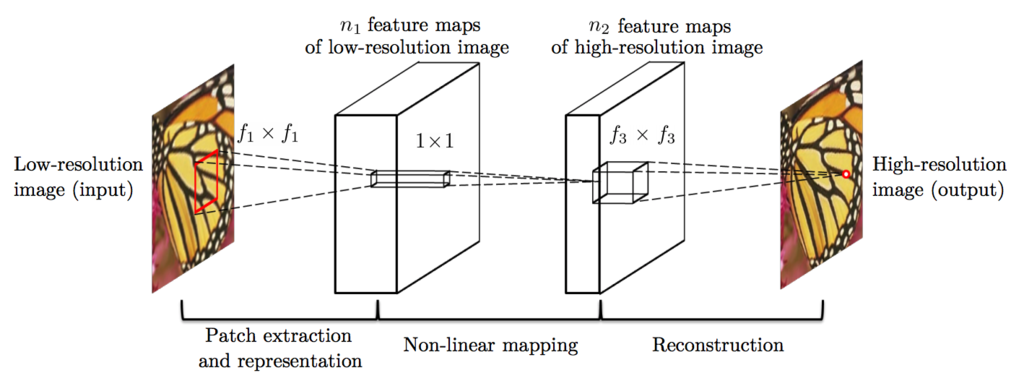
,
はカーネルサイズ,
,
はフィルタ数を示していて,論文では
$$(f_1, f_3) = (9, 5)$$
$$(n_1, n_2) = (64, 32)$$
を採用しています.
カーネルサイズ,フィルタ数およびレイヤ数を大きくすれば画質は向上するのですが,推論時間を鑑みてこの値を採用しています.
PyTorchでモデルを組むと次のようになります.
from torch import nn from torch.nn.functional import relu class SRCNN(nn.Module): def __init__(self): super(SRCNN, self).__init__() self.conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=9, padding=4) self.conv2 = nn.Conv2d(in_channels=64, out_channels=32, kernel_size=1, padding=0) self.conv3 = nn.Conv2d(in_channels=32, out_channels=3, kernel_size=5, padding=2) for m in self.modules(): if isinstance(m, (nn.Conv2d)): nn.init.normal_(m.weight, mean=0, std=0.001) nn.init.constant_(m.bias, val=0) def forward(self, x): x = self.conv1(x) x = relu(x) x = self.conv2(x) x = relu(x) x = self.conv3(x) return x
データ準備
今回はデータセットとしてGeneral-100*5を使います.data/general100.pyを実行すれば,データのダウンロードとランダムでデータ分割できます.
ディレクトリの構造はこんな感じになります.
[root] ├── data │ ├── General-100 │ │ ├── test │ │ │ ├── im_xx.bmp │ │ │ └── ... │ │ ├── train │ │ │ ├── im_xx.bmp │ │ │ └── ... │ │ └── val │ │ │ ├── im_xx.bmp │ │ │ └── ... ├── main.py └── ...
続いて,PyTorch側でデータセットを準備します. 画像を読み込み,Data Augmentationをして高解像度画像とした後.画像サイズを縮小拡大して低解像度画像を作ります.
class DatasetFromFolder(data.Dataset): def __init__(self, image_dir, patch_size, scale_factor, data_augmentation=True): super(DatasetFromFolder, self).__init__() self.filenames = [str(filename) for filename in Path(image_dir).glob('*') if filename.suffix in ['.bmp', '.jpg', '.png']] self.patch_size = patch_size self.scale_factor = scale_factor self.data_augmentation = data_augmentation self.crop = RandomCrop(self.patch_size) def __getitem__(self, index): target_img = Image.open(self.filenames[index]).convert('RGB') target_img = self.crop(target_img) if self.data_augmentation: if random.random() < 0.5: target_img = ImageOps.flip(target_img) if random.random() < 0.5: target_img = ImageOps.mirror(target_img) if random.random() < 0.5: target_img = target_img.rotate(180) input_img = target_img.resize((self.patch_size // self.scale_factor,) * 2, Image.BICUBIC) input_img = input_img.resize((self.patch_size,) * 2, Image.BICUBIC) return ToTensor()(input_img), ToTensor()(target_img) def __len__(self): return len(self.filenames)
DatasetFromFolderは学習データに対して使うものなので,Data Augmentationをしない評価用データセットDatasetFromFolderEvalも別に定義しておきます.
学習
先ほど定義したデータセットを用いてデータローダを作ります.
今回は結果が分かりやすいように倍率をx4に設定してみます.
val_loaderで取得できる画像はそれぞれ異なるサイズを持っているので,batch_sizeは1にしないとエラーになります.
train_set = DatasetFromFolder(image_dir='./data/General-100/train', patch_size=96, scale_factor=4, data_augmentation=True) train_loader = DataLoader(dataset=train_set, batch_size=10, shuffle=True) val_set = DatasetFromFolderEval(image_dir='./data/General-100/val', scale_factor=4) val_loader = DataLoader(dataset=val_set, batch_size=1, shuffle=False)
続いて,モデルと誤差,最適化関数を定義します. 誤差関数には二乗誤差(MSE)を用いますが,超解像では絶対誤差(MAE)を用いることもしばしばです. 論文では,最適化関数として普通の確率的勾配降下法(SGD)を用いますが,今回はAdamを用います. 学習率の設定には少し工夫があり,最終層とそれ以外の層とで別の値を設定します.
model = SRCNN()
criterion = nn.MSELoss()
optimizer = optim.Adam([{'params': model.conv1.parameters()},
{'params': model.conv2.parameters()},
{'params': model.conv3.parameters(), 'lr': 1e-5}],
lr=1e-4)
最後に,学習ループを書きます.
データローダから取得したミニバッチをmodelに入力し,criterionで誤差を計算します.
loss.backward()で勾配を計算し,optimizer.step()でパラメータを更新します.
for epoch in range(50000): model.train() epoch_loss, epoch_psnr = 0, 0 for batch in train_loader: inputs, targets = Variable(batch[0]), Variable(batch[1]) optimizer.zero_grad() prediction = model(inputs) loss = criterion(prediction, targets) epoch_loss += loss.data epoch_psnr += 10 * log10(1 / loss.data) loss.backward() optimizer.step() print('[Epoch {}] Loss: {:.4f}, PSNR: {:.4f} dB'.format(epoch + 1, epoch_loss / len(train_loader), epoch_psnr / len(train_loader))) model.eval() val_loss, val_psnr = 0, 0 with torch.no_grad(): for batch in val_loader: inputs, targets = batch[0], batch[1] prediction = model(inputs) loss = criterion(prediction, targets) val_loss += loss.data val_psnr += 10 * log10(1 / loss.data) print("===> Avg. Loss: {:.4f}, PSNR: {:.4f} dB".format(val_loss / len(val_loader), val_psnr / len(val_loader)))
今回はこの条件で50,000エポック学習してみます.
結果
50,000エポック学習した結果です.
少し分かりづらいですが,左の低解像度画像に比べてエッジやテクスチャがはっきりしていると思います.

まとめ
今回は超解像とPyTorchに入門しました.次回はもうちょっと新しいモデルとか分野の流れをまとめられたらと思います.拙い記事を量産しますが,温かい目で見守っていただけると幸いです!
*1:https://www.tensorflow.org/
*3:輪郭のギザギザ歪みをジャギーといいます.
*4:Chao Dong, Chen Change Loy, Kaiming He, Xiaoou Tang. Learning a Deep Convolutional Network for Image Super-Resolution, in Proceedings of European Conference on Computer Vision (ECCV), 2014
*5:Chao Dong, Chen Change Loy, Xiaoou Tang. Accelerating the Super-Resolution Convolutional Neural Network, in Proceedings of European Conference on Computer Vision (ECCV), 2016