初めまして、Sansan DSOC 研究開発部の齋藤慎一朗と申します。(Twitterではsinchir0と名乗っています。) 分析コンペに参加するのが趣味なので、挑戦した内容と結果を定期的にブログで投稿していければと思い、執筆させてもらっています。
今回は、Cassavaの画像からどの病気にかかっているかを判別するCassava Leaf Disease Classificationに参加し、銅メダル(226th/3900, Top6%)でした。
うーん、銅メダル!LB最高のsubと、博打でcleanデータだけ使ったsubも入れてみたけどやっぱダメか〜。ただ画像コンペでは初メダルです🎉 pic.twitter.com/IZxR9bVsSC
— しんちろ (@sinchir0) 2021年2月19日
本記事では
- コンペの概要
- 重要なポイントであったNoisy labelに対して、調べたこと・実験したこと
を紹介したいと思います。
本内容について、3/2(火) 19:00~の分析コンペ勉強会でも紹介させて頂きます。是非参加して頂けると嬉しいです!
また、今回のコンペ参加にあたり、Sansan DSOC 研究開発部 Kaggle部のGCPリソースを大いに活用させて頂きました。 この場を借りて感謝させて頂きます🙇♂️
- どんなコンペだったか
- どんな点がポイントだったか
- コンペに参加したモチベーションは?
- あなたのソリューションは?
- Noisy labelへの対抗策
- testもNoisyなデータへの対抗記録
- 学んだこと
- 反省点
どんなコンペだったか
予測対象
Cassavaの画像から、そのCassavaがどの病気にかかっているかを判別するコンペでした。 判別クラスは全部で5クラスで下記のようなものが存在します。
Cassava Bacterial Blight (CBB)
Cassava Brown Streak Disease (CBSD)
Cassava Green Mottle (CGM)
Cassava Mosaic Disease (CMD)
Healthy

データセット
train : 21397枚, test : 15000枚(31% : Public, 69% : Private)
直近の画像コンペの中では良心的なサイズのデータセットだったと思います。
評価指標
シンプルにAccuracyでした。100枚の画像のうち、90枚の画像のラベルを正しく予測できていれば90%の精度と評価する指標です。
どんな点がポイントだったか
下記3点が重要だったと思います。
- 学習データセットにおける画像のラベリングミスが多いこと
- PublicLBの評価に使われているデータセットもNoisyであること
- LeaderBoard上のスコアに大きな差がなかったこと
順に説明していきます。
学習データセットにおける画像のラベリングミスが多いこと
画像のラベル付けが間違っている学習データが非常に多いこと(Noisy labelと呼びます)が、コンペ初期のDiscussionにて明らかになっていました。
下記画像は、モデルを用いて「Healthy」と予測された画像が、実際には異なるlabelを付けられている画像の一例です。

cleanlabというライブラリを用いて、NoisyDataかどうかを判定した結果が下記のグラフとなります。0,4については20%程度がNoisyと判断されていることが分かります。

PublicLBの評価に使われているデータセットもNosiyであること
コンペ初期の段階から、Noisy labelのデータを除去したデータセットを用いて訓練したモデルでは、PublicLB上のスコアが減少したことが、Discussion上にて報告されていました。このことから「PublicLBの評価に使われているデータセットはNoisyである」ことが分かります。
参考程度に、私が試した場合は下記のようなスコアになりました。
- 学習に全データを用いたモデルのスコア
- CV : 0.8837
- PublicLB : 0.8944
- 学習にcleanデータのみを用いたモデルのスコア
- CV : 0.9206(ちょっとleakしてます。)
- PublicLB : 0.8910
LeaderBoard上のスコアに大きな差がなかったこと
LeaderBoardとは、Kaggleにおける順位表のことです。下記の画像は私の最終順位を表示したLeaderboardですが、私の同じスコアの方が数名いることが分かります。
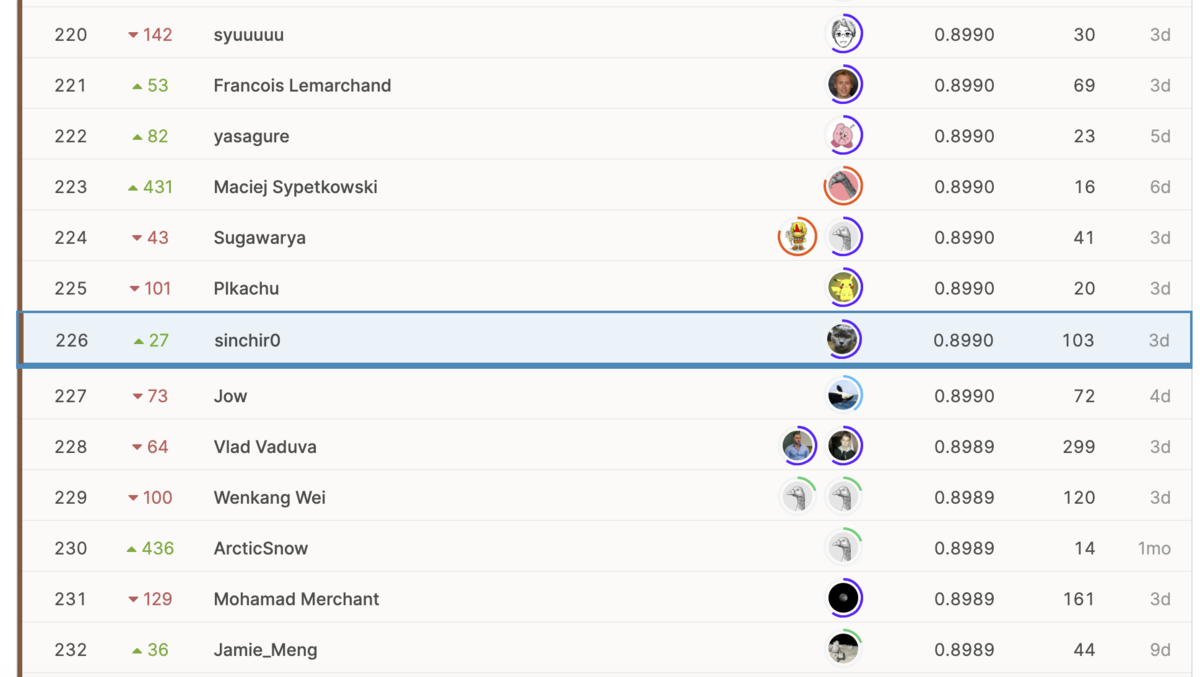
私の最終スコアは、0.8990であり、Private test setの画像数は約10000枚であったため、私のモデルはざっくり10000枚中8990枚のラベルを当てられていたことになります。この順位表のスコアの少し上をみると、0.8992、つまり+2枚当てることが出来ていたら、順位が226位→172~202位のどこかまで上がっていたことが分かります。約10000枚に対して、2枚を当てられるかどうかは誤差、言い換えれば運任せにもなり得ます。
上記3点を考えると、PrivateLBでの最終的なスコアも運に左右される可能性が高く、Twitter上では「おみくじコンペ」と呼ばれたり、KaggleでのDiscussionでも「lottery(宝くじ)」という表現を多く見かけました。
コンペに参加したモチベーションは?
「画像コンペよく分からんからシンプルなタスクのコンペに出たい」という気持ちと 「testもNoisyなデータセットの対抗策見つけたら上位入賞できるのでは?」と思い参加しました。(実現できませんでしたが😂)
あなたのソリューションは?
Kaggleでの一般的な最終subの選び方としてLBのスコアが最高のsub, CVのスコアが最高のsubを一つずつ選ぶものがあり、今回もそれに従いました。
LB最高のsub
(tf_efficientnet_b3_ns, resnext50_32x4d) * (5fold) * (最終epoch4つ) * (TTA10)のmean
詳細は下記となります。
CV : 0.898, PublicLB : 0.903, PrivateLB : 0.899
- model : tf_efficientnet_b3_ns, resnext50_32x4d
- CV : Stratified 5 fold
- loss : LabelSmoothingCrossEntropy(epsilon=0.1)
- optimizer : Adam
- epoch : 15
- scheduler : ReduceLROnPlateau
- size : 512
- TTA : 10
- DataAugmentation :
- RandomResizedCrop
- Transpose
- HorizontalFlip
- VerticalFlip
- ShiftScaleRotate
- Cutout
- Batch Normalization layerのweightを、epoch前半のみ固定
- checkpoint ensemble : 最終epoch4つ
CV最高のsub
(tf_efficientnet_b3_ns, resnext50_32x4d, vit_base_patch16_384) * (5fold) * (TTA3)のmean
CV : 0.921, PublicLB : 0.900, PrivateLB : 0.897
LB最高のsubに対して、下記点を変更しています。
- 学習データはcleanlabを用いてcleanと判断されたデータのみ使用
- 使用モデルにvit_base_patch16_384を追加。
- checkpoint ensembleは行わない
- TTAの数を10→3に変更
ちなみに、コンペ終了直前まで、cleanなデータだけに絞らず全データを用いて、更にRandomResizedCropをResizeにしたモデルを追加したensembleの予測値を選択するか悩んでいました。 本モデルはCV: 0.903, PublicLB : 0.900, PrivateLB : 0.901だったため、こちらを選べていたら銀メダルでした。まあKaggleあるあるです😇
Noisy labelへの対抗策
ここから先は、Noisy labelへの対抗策として、コンペ中に紹介されていたものと・自分で試したものを紹介していきます。
対策として大きく二つの軸があるかなと思っています。
- 学習データにfitさせすぎない
- Noisy labelのデータを処理する
順に紹介していきます。
学習データにfitさせすぎない
学習データにfitさせすぎないことが重要なコンペだったと思います。そのための手法としては、下記のようなものが主流でした。
多くのモデルでEnsembleを行う。
どんなコンペでもEnsembleは重要ですが、今回のようなNoisyデータセットでは特に重要だと感じました。 実際に私が試した場合でも、resnext,vit,efficientnetの3つのmeanを取るだけでPublicLBでは約0.005, PrivateLBでは約0.009程度精度が向上しています。
| PublicLB | PrivateLB | |
|---|---|---|
| resnext50_32x4d | 0.8930 | 0.8916 |
| vit_base_patch16_384 | 0.8921 | 0.8899 |
| tf_efficientnet_b3_ns | 0.8975 | 0.8921 |
| 上記3つのmean | 0.9005 | 0.8999 |
Noisyなlabelであることを考慮できるlossを選択する
Noisyなlableに対するlossを利用することもDiscussionで多く議論されていました。 様々な手法が挙げられていましたが、下記3つを紹介させて頂きます。
- lossに対するlabel smoothingの利用
1,0のlabelを、学習時に0.95,0.05などに変換してlossを計算することで、学習データにfitさせすぎないようにする方法です。他のコンペでもよく利用されます。CV,LB共に向上したため私も採用しました。
下記グラフは横軸の予測確率、縦軸にloglossを取っています。labelが1,0の状態をNormal, labelを0.95,0.05の状態に変換してlossを計算したものをSmoothと定義して比較すると、予測確率が0.9や0.1など、極端な予測確率を出す場面において、Smoothではloglossの増加・減少が少なくなることが分かります。

- Bi-Tempered Logistic Loss
Logistic Lossが持つ、「外れ値に全体のlossが支配される点」「labelが誤っているsampleによって決定境界が広がってしまう点」に対するlossです。
下図では、Logistic Loss、Bi-Tempered Logistic Lossの二つに関して、「clean dataset」「small margin noise」「large margin noise」「random noise」の4つでの決定境界の比較を行っており、Bi-Tempered Logistic Lossがどのデータに対しても、より良い決定境界を持てている事が分かります。
ただし、t1,t2の二つのハイパラを持ち、今回のコンペでは良いパラメータを選べていないと精度向上には繋がらなかったようです。
私の場合、CVは向上しましたが、LBが減少したため採用しませんでした。
Discussionはこちら

- Symmetric Cross Entropy Loss
Noisy lableの場合、ground truthが真の分布ではなく、predictionがある程度真の分布を表すことを考慮したlossです。
私は試してはいませんが、Discussion内では精度が改善したという投稿も見られました。
Discussionはこちら

モデルのBatch Normalizarion layerのweightを学習前半のみ固定する
weightをtrainデータに合わせすぎないという観点で、本手法も紹介されていました。 CV、LB共に向上したため採用しています。
Discussionはこちら
私が使用したコードは下記です。
def freeze_batchnorm_stats(model): for module in model.modules(): if isinstance(module, nn.BatchNorm2d): if hasattr(module, 'weight'): module.weight.requires_grad_(False) if hasattr(module, 'bias'): module.bias.requires_grad_(False) module.eval()
knowledge distillation method
一度予測した結果のoof(soft label)と、groud truthのlabel(hard label)を足し合わせて、soft labelとして再度学習する手法です。

過去コンペのPlant Pathology 2020の1st Solutionで用いられていた手法であり、 Plant Pathology 2020がNoisy Datasetなコンペだったため、本コンペでも有効な可能性がある手法です。
私は、本手法を試せていませんが、Discussion投稿者はスコアが改善したと記載しています。試した方いたら是非教えてください🙇♂️
Discussionはこちら
Noisy labelのデータを処理する
こちらも様々な方法が議論されていましたが、その中でもUpVoteが多かったcleanlabを紹介させて頂きます。
cleanlab(Confident Learning)の利用
Noisy labelを発見する手法として、cleanlabというライブラリの使用が挙げられていました。 このライブラリは、Confident Learning: Estimating Uncertainty in Dataset Labelsという論文の実装です。

この手法では、Noisy label込みで学習したモデルの予測確率を用いて、出力確率が高いclassを真のclassと仮定し、与えられたclassと(仮の)真のclassから同時分布を生成します。 その同時分布と、Noisy label込みで学習したモデルの予測確率を照らし合わせることで、Noisy labelを検出しています。
人が画像をlabelingをする際、狼の画像を犬と間違えることは多くあるが、猫と間違えることは少ないと予想されるため、その気持ちを数式で表現した手法です。
詳しくは「Confident Learning -そのラベルは正しいか?」が非常に分かりやすかったのでそちらを参照して下さい。
また、ライブラリが非常に使いやすいのも一つの特徴で、例えばNoisyデータを見つけたいのであれば
from sklearn.linear_model import LogisticRegression model=LogisticRegression() clf=LearningWithNoisyLabels(clf=model) clf.fit(X_train,y_train)
の後、clf.noise_maskを確認するだけです。
ただし、今回のコンペではこちらの手法を用いるとCVは上がるものの、LBが落ちました。 原因は、本手法ではtrainはNoisyだけれども、testはcleanな場合を想定していますが、今回のデータはtestもNoisyであることが分かっているためです。 この部分を解決できないかなと、いくつか手法を試したので、続いて紹介させて頂きます。
Discussionはこちら
testもNoisyなデータへの対抗記録
ここからは、私がコンペ中に、testさえもNoisyなデータに対して、上記以外の方法で試してみたものを紹介します。ちなみに全部失敗してます。
大きな軸は3つです。
- Noise Classifierの構築
- Cleanlabの考え方を応用
- is_noisyフラグをstackingにて利用
Noise Classifierの構築
まずは、testの中のNoisyデータを判別できるかどうかを試してみました。
CleanlabにてNoisyと判断された画像を1,それ以外を0とした判別器Noise Classifierを構築し、Noiseデータかどうかを見分けようと考えました。 これは、Cassavaの画像をlabelingをする際には、間違えやすい画像と間違えにくい画像が存在する、という仮定に基づいています。
結果として、oofに対するprecisionが22%程度でした。つまり、仮にtestデータの1000枚をNoisyと判断しても、そのうち800枚が誤ってNoisyと判断していることを意味します。 精度の低さからこれはダメそうと考え、撤退しました。
Cleanlabの考え方を応用
Cleanlabでは、与えられたlabelと真のlabelから、そのlabelがどのlabelを間違えられやすいか、という分布(誤り分布と呼びます)を用いて計算を行っていました。 例えば、0というラベルは「0 : 0.77%, 4 : 0.12%, 1 : 0.06%, 3 : 0.03%, 2 : 0.02%」という確率になります。この数値から0は4と最も間違えられやすいことが分かります。

誤り分布を利用し、下記のようなことを行いました。
- 誤り分布を、全てのpredの結果にかけてみる。
一番naiveな方法です。案の定、CV:0.8924→0.8335に落ちたため不採用としました。
- 誤り分布を、cleanlabにてNoisyと判別された画像にだけかけてみる。
上記の対象をNoisy labelにだけ絞って、誤り分布をかけてみました。これもCV:0.8924→0.8870に落ちたため不採用としてます。
- cleanlabにてcleanと判断された画像のみを使ったモデルの予測値に、誤り分布をかける。
上述までの方法は全て、Noisy labelな画像も用いて学習したモデル(All model)の予測に対して、誤り分布を適用していました。今回の方法では、Cleanlabelな画像のみを用いて学習したモデル(clean model)にて予測した結果に、誤り分布を適用します。
恐らく現実では、真のクラスに対して、クラス毎に間違えやすさが存在しており、 この方法では、以前までの方法よりも真のクラスをより忠実に再現できるのではないかと考えました。
現実でのラベリングミスの起き方?
testの画像をNoisyと判断する方法ですが、All modelとclean modelの予測値が異なる部分をNoisyな画像と判断しています。
この方法では、LBが0.895→0.894に低下したため、不採用としました。
is_noisyフラグをstackingにて利用
is_noisyフラグを特徴量に与えた状態で、LightGBMにてstackingを行いました。
これは、stacking時にLightGBMがis_noisyかどうかで利用する特徴量を分けてくれたら、という期待を込めています。
結果として、is_noisyを含めた場合はCV:0.8991であり、is_noisyを含めなかった場合はCV:0.8997であったため、不採用としました。
学んだこと
- pytorchの使い方
- pytorch image modelsの使い方
- Snapmix, gradient_accumulation_stepsなどの画像の手法
- Noisylabelに有効なloss
- Confident Learningの考え方、cleanlabの使い方
- Weight & Biasesによる実験管理
反省点
DiscussionやNotebookで有効とされている方法を追うのに時間を使いすぎてしまい、自分で考えた手法をあまり試せなかった。
金メダルを取るためには、DiscussionやNotebookで紹介されていないような方法を自分で見つけ出すことが重要と考えています。今後は自分で手法を考え、試すことを増やして行きたいと思います。CVの計算が一部適当になってしまった。
コンペ後半のensembleの部分や、cleanデータのみを用いた実験の際、CVを算出していなかったり、leakした方法でCVの計算を行っていました。
具体的には、cleanデータのCVを計算する際、一度modelのweightを5fold分出力し、そのweightを読み込み直し、全てのtrainデータに対する予測確率を算出していました。この方法だと、 fold内で学習に使われていたデータも予測対象に含むため、CVが高めに算出されると想像されます。
Trust CVをするためには、正しくCVの値を計算する必要があるため、時間がかかろうともCV値はどんなモデルでも算出し、正確に計算する必要を再認識しました。