本記事は,Sansan Advent Calendar 2021 第18日目の記事です.
こんにちは,研究開発部の内田です.いつの間にやら季節は進んで,街路樹の葉も落ちたり燻んだり,日常の風景からも寒さを感じるようになってきました.最近は,そんな日常に彩りを加えるべく,お花のサブスクリプションサービスを契約し始めました.私自身花に詳しいわけではないですが,なんとなく気分が上がるのでおすすめです.
さて,本エントリでは 10/15-10/24 の日程で開催いたしました「Sansan × atmaCup #12」について,遅ればせながらのレポートをお届けしたいと思います.
https://atma.connpass.com/event/225124/atma.connpass.com
atmaCupとは?
atmaCupとは,atma株式会社 様が主催するオンサイトデータコンペティションです.データコンペティションは,主催者から出題されるデータに対して,参加者が分析・予測を行い,提出した結果に対するスコアを競うコンペティションです.
コンペティションプラットフォームとしてはKaggleが世界的に有名ですが,atmaCupも国内の上位Kagglerが多く参加し,大変な人気を博しています.そのレベルの高さもさることながら,運営の山口さん (@nyker_goto) からは初心者向け講座が毎回開催されており,初心者でも参加しやすい設計となっています.
弊社としては,昨年もatmaCupを開催しており,今回が2回目となります.前回がネットワークに関するお題で好評いただいたこともあり,今回のお題を予想してくれる参加者がいたりと,開会式前から盛り上がりを見せていました.
以降,今回のお題や解法について詳しく見ていこうと思います.
昨年の資料はこちら
- Sansan×atmaCup#6 Solution発表会 問題の概要と結果発表 / Sansan×atmaCup#6 Issue Summary and Results - Speaker Deck
- Sansan×atmaCup#6 ソリューションの概要 / Sansan×atmaCup#6 Solution Summary - Speaker Deck
- Sansan×atmaCup#6 1st place solution - Speaker Deck
- Sansan×atmaCup#6 Solution - Speaker Deck
お題
今回のお題はズバリ…
「項目ラベルを予測せよ!」
名刺には,氏名・Email等,さまざまな項目の情報が記載されています. 項目ラベルによって,データ化の難易度・セキュリティレベルは大きく変わります. 効率の良いデータ化のためには,文字入力する前に項目ラベルを予測するのが望ましいです. 早い段階で予測が行われるため,項目ラベルの予測結果は後段処理に大きく影響します. したがって項目ラベル予測は,文字列などの情報は使わず,高い精度が求められるタスクとなります.
項目ラベル予測をタスクとして取り扱うにあたり今回提供したデータは,検出した文字列座標と項目ラベルです*1.画像やテキスト等の記載されている内容に関する情報は一切提供しません.問題としては10クラス分類問題で,評価指標はMacro F1でした.
| bcid | left | top | right | bottom | class_id |
|---|---|---|---|---|---|
| 000612e… | 68 | 487 | 721 | 517 | 4 |
| 000612e… | 191 | 552 | 375 | 577 | 5 |
| 000612e… | 192 | 586 | 376 | 610 | 6 |
| 000612e… | 222 | 105 | 893 | 179 | 2 |
| … | ... | ... | ... | ... | ... |
非常にシンプルなデータで,1レコードを見ただけではただの座標値ですから,項目ラベルを当てることは難しいです. ゆえに,項目ラベルをうまく予測するには,同じ名刺内の他の矩形との位置関係をうまくモデリングする必要がありました.
また,今回は意図的にテストデータにのみ出現するクラスを1つ用意しました. いわゆる未知クラスへの対応が必要で,Kaggleでも類似設定でのコンペティションの事例があります*2. このような設定を採用したのには,今後新たな項目をデータ化する可能性があり,その際に学習データが足りない状態でうまく推論できると嬉しいという意図がありました.
まとめると,今回のatmaCupのキモは「レコード間相互関係のモデリング」と「未知クラスへの対応」でした. 解法のサマリは,山口さんからもまとめていただいたので,下記スライドも合わせてご覧ください.
結果
早速ですが,最終のPrivate LBを見てみましょう.未知クラスがあるにも関わらず,0.86-0.88と高い精度が出ているのが伺えますね.
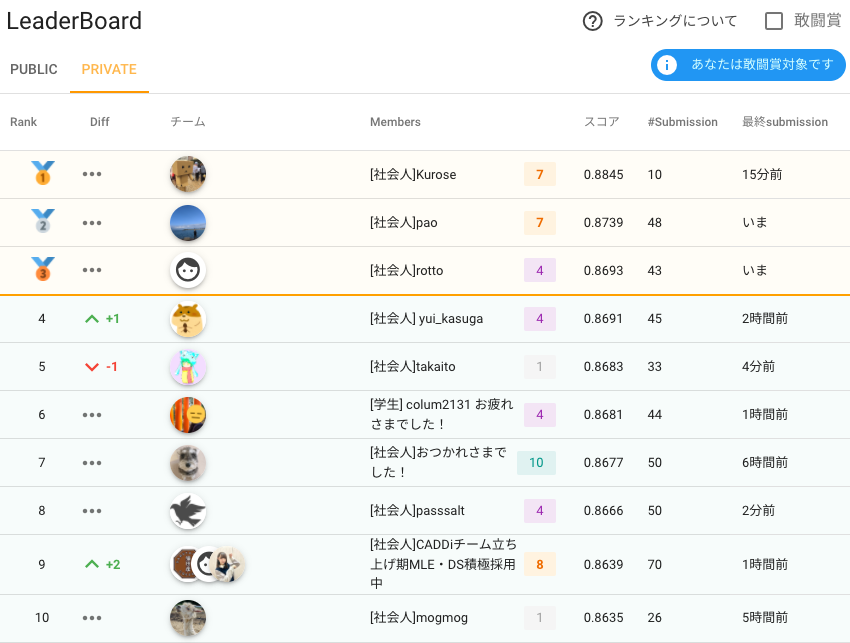
今回は,チーム単位での総合優勝,個人(社会人/学生)のベスト3をそれぞれ表彰させていただきました. 入賞された皆様,おめでとうございます.
- 総合優勝
- Kuroseさん
- 個人の部(社会人)
- Kuroseさん
- paoさん
- rottoさん
- 個人の部(学生):
- colum2131さん
- XS330さん
- T0mさん
加えて,ディスカッションにおけるいいね数で決定される,atmaCup恒例のnyker_goto賞は,「ちょっとだけ -> かなり精度が上がるかもしれないpulpを用いた後処理」というタイトルで投稿された tubo さんに送られました.未知クラスへの対応として後処理が有効なのですが,これを最適化に置き換えて解くことで,大幅にスコアを上げる方法を公開されていました.コメントで「スコア向上しました!」という声が多く見られ,コンペの盛り上がりの一端を担っていただきました.

最後に,Sansanが主催するコンペということで,33位のTTsamuraiさんもサプライズ表彰させていただきました! 賞金ではないですが,弊社自慢のノベルティを送付させていただいております 😆
上位解法
昨年と比べて,参加者数・サブミッション数で約2.5倍と盛り上がりを見せた今回のatmaCupですが,コンペ終了後には例のごとく振り返り会を行いました.学生の部で一位を獲得されたcolum2131さん,総合優勝と社会人の部の2冠王を獲得されたKuroseさんに登壇を快諾いただきまして,豪華メンバーで執り行うことができました.
https://atma.connpass.com/event/229180/atma.connpass.com
colum2131さん
colum2131さんは,コンペを通してGBDT (Gradient Boosting Decision Tree) ベースの方法で戦っていて,コンペ序盤からずっと上位に鎮座されていました.基本的な集約特徴量に加えて,周囲の矩形とのラグ特徴,1st stageモデルの予測値特徴を用いることで,Private LB: 0.7996まで来ていたそうです*3.ここから未知クラスに関して,テストデータらしいデータをAdversarial Validationで抽出し,疑似ラベルをつけて学習することで Private LB: 0.8670,最終的にはtuboさんの後処理で Private LB: 0.8681 までスコアが向上したようです.
colum2131さんはディスカッションにも精力的に投稿されていて,未知クラスの意味やコンペルールについて運営に直接質問してくださったのは大変印象的でした.オープンな場での議論こそデータコンペの醍醐味と私は考えているので,この姿勢を見習いたいと感じました.
Kuroseさん
Kuroseさんは,GNN (Graph Neural Network) ベースの手法で戦っていたようです.実は運営の事前検証では,GNNベースの手法を試しておらずダークホースだったのですが,そのダークホースの手法が優勝を掻っ攫う形となりました.もちろんモデルアーキテクチャの調整だけでなく,エラー分析で得た知見から,未知クラスの人工データを学習データに含めることでグングンスコアを向上させ,最終的には Private LB: 0.8845 でフィニッシュされていました.圧倒的です.
Kuroseさんはコンペ中盤からの参加でしたが,瞬く間に順位を上げて,ついには優勝してしまいました.atmaCupのSlackには #lb-live という順位変動をポストするチャンネルがあるのですが,大きな変動があると <<BIG CHANGE>> という文言とともに参加者からのリアクションが集まります.時には稲妻マークが終われるのですが,今回の追い上げはまさにそんな感じでした.また,未知クラスの特性について「常識的に判断できる」と仰っていて,流石の社会人力を見ました.私もつけたいです.
おまけ: ベースライン
今回,コンペを盛り上げるちょっとしたスパイスとして,「やんちゃなベースライン」を作っていました.つまり,運営なのに上位を狙おうとするムーブをしていたということです.その動向をご覧ください.
記念パピコ #atmaCup pic.twitter.com/Fe9FDBRGAW
— さしすせ奏 (@s_aiueo32) 2021年10月15日
よっこらせ
— さしすせ奏 (@s_aiueo32) 2021年10月18日
勝ちたい! 現在の順位は 2位です。 https://t.co/ODidvlhIGn #atmaCup
そこかしこから「ベースラインとは?」という声が聞かれ,正直怒られないかヒヤヒヤしていましたが,Kuroseさんのようにとりあえず高めのベースラインを超えることを頑張ってくれた方もいたとのことで,結果オーライです.
モデルには位置エンコーディングのない Transformer Encoder を使ったシンプルなもので,上位陣にも同様のモデルを使っていた方がちらほらいたようです.未知クラスについては,名刺の外側に分布していることがわかるので,閾値より外側は全て未知クラスにして提出しました.colum2131さんも同様に閾値を切っていましたが,そこまで筋道立ててやった処理ではないので,そこも見習おうと感じた次第です.
まとめ
本エントリでは,「Sansan × atmaCup #12」のレポートをお届けしました. シンプルなデータだけに色々な解き方があって,運営側としても刺激をもらいましたし,とても楽しめました. 参加いただいた皆様はもちろん,山口さんはじめatma株式会社の皆様,関係者各位に感謝を伝えたく思います. 機会があれば次回も開催したいという思いでいっぱいです.
最後に,研究開発部では一緒に働く仲間を積極的に募集しています. 昨年,今年とコンペに参加してみて「面白そうだな」「もっとデータに触りたいな」「コンペの運営もしてみたいな」など思った方はカジュアルにお声掛けいただけると幸いです*4.
https://recruit.sansan-dsoc.com/recruit.sansan-dsoc.com
*1:Sansan, Eightの名刺データ化の過程で生成されたデータ. 個人情報を含まない統計情報として利用規約の範囲内で提供.
*2:Bengali.AI Handwritten Grapheme Classification - https://www.kaggle.com/c/bengaliai-cv19
*3:この時点で運営の想定は超えていました 😅
*4:もちろん参加していない人も大募集です!