Sansan-CSIRTの松田です。Sansan に join してから早1年半が経過しました。 先日 AWS Security Roadshow Japan 2020 に「Sansanの成長を支えるセキュリティログの活用と Amazon Elasticsearch Service」をテーマに発表させて頂きました。 こんなに大きなイベントでの登壇は人生初です。しかもAWSです。それはもう緊張しました。開催報告はこちらに記載されていますので、興味のある方はウォッチしてみてください。 また、今回 CSIRT が開発に参画した SIEM on Amazon ES に関するリリースは以下に掲載されています。
時間の関係上、基本的なトピックしかお話できませんでしたので、本ブログではもう少し詳細に書きます。
今回の基盤の必要性
発表内容でも触れましたが、一般的にSIEM(Security Information and Event Management)の機能としては以下の3つです。
- ログを統合的に管理する
- 複数のログを相関的に分析する
- インシデントを発見し管理する
SIEM に最も重点を置くことは、複数のログを管理し長期的に相関分析できる状態とすることです。 なぜなら Sansan は個人情報を扱う会社です。何も起きないように日々高いレベルで対策を実施し、運用しています。 しかしながら、組織を標的とした攻撃というものは用意周到に準備されるものであり、最終的には”いつもと違う”という違和感に気付くことで発見を早めることができます。 その点、違和感という物は簡単にロジックへ落とし込めない物が多く、まだまだ攻撃者が有利な状況が続いていることも理解しています。 だからと言って何もしないと言う訳にはいきません。
違和感に気付く、即ち「インシデントを発見して管理すること」を最終的な目的とするならば、その前提に必要となるログを管理しいつでも検索できる状態を目指すことになります。 ログを管理して、検索できる状態にするという行為は一見簡単そうに見えますが正直辛いです。地味な割には、手間がかかり、いざという時に無いと困るものです。 この当たり前のことをしっかりと実現するために今回 Amazon Elasticsearch Service(以下、Amazon ES)を選択したことは非常に良い決断だったと思っています。
これまでの SIEM 運用で生まれた課題
以前は Splunk という製品を利用していましたが、維持運用にかかるコストが増加しつつありました。 大きく分けると以下の通りです。
- 将来的に扱うログ量とコストのバランスが崩れる*1
- 300GB/日を管理することを想定していたため、ライセンス料が膨大になる
- 大規模なSIEMを運用するために必要なインフラに毎月莫大なコストがかかる
- 便利過ぎる反面、属人化する傾向にある
- 便利だといろいろやりたくなりますが、一度設定してもう二度と使わなくなる機能が多い
- 実際のインシデントを想定すると、標準的な機能及び可視化で十分なケースが多く高度な機能はいらない
- 簡単にはスケールができない*2
- 日々増加するログ量に柔軟に対応できない
- 簡単にスケールアップ、スケールアウトができない
- 検索にはリソースを多く消費し、分析しようにも待ち時間が長く使い物になら無い
これから発生するインシデントが事前に原因が分かっているものであれば、たくさん準備して事前に可視化すれば良いと思います。 現実的にはそう簡単ではなく、すぐに原因が分からないことが多いです。その上で、どんな状態でも最速で原因を突き止め特定する必要があります。 そのためには、まず、「当たりを付ける」ことが非常に重要です。調査の第一歩としての違和感を如何に多く収集できるか。 そして、その違和感を的確に分析することができるか、これがインシデントレスポンスの基本かつ重要な考え方です。
当たりを付けるためには、あらゆるログを瞬時に検索して一秒でも早く違和感に気付くことができる状態を作ることが重要です。*3
CSIRT が扱うログ
現在取り扱っているログの内訳としては以下の通りです。
社内系ログ
- Firewall 関連ログ
- Windows 関連ログ
- DNS ログ
- DHCP ログ
- EDR 関連ログ
- IDaaS 関連ログ
- クラウドストレージサービス系ログ
- グループウェアサービス系ログ
プロダクト系ログ
- WAF 検知ログ
- AWS サービス系ログ
- AWS セキュリティ系ログ
など。その他細かいものも含めると20種類は軽く超えます。
課題の根本対処
今回の基盤に求めたことを簡単にまとめると以下の通りです。
- コストを抑えて大容量のログの取り込みと検索に耐えれる
- 事業の成長によりログ量が増加しても柔軟に対応ができる
- 維持運用しやすく、属人化しない状態となる*4
要するにシンプルにすることです(雑
無駄な機能をそぎ落とし、必要なものだけ残す。 初期の構築にかかるコストはそれなりにありますが、運用してしまえば維持にほとんどコストがかからない状態を目指しました。
解決における重要な2つの要素
発表中ではわかりやすく、5つに分けて説明しましたが、ここでは重要な要素を2つにまとめます。

1. Amazon ES を利用し運用を省力化する
フルマネージドサービスである Amazon ES を SIEM のコア部分に採用したことで、高い可用性を維持しつつ柔軟性も手に入れることができました。AWSコンソール上で柔軟にスケールアップ、スケールアウトできるので運用に必要な工数は最低限で済みます。
2. es-loader を利用しあらゆるログの取り込みに対応する
AWS Security Solutions Architect の中島さんが開発していた SIEM on Amazon ES というソリューションを紹介頂いたことがきっかけで es-loader の開発に参画しました。初期段階からパフォーマンス測定やより使いやすくするための提案やフィードバックを行いました。es-loader はこのソリューションの一機能という位置付けで、CSIRTが扱う多種多様なログをサーバーレスで Amazon ES に取り込むことができます。Amazon S3 にログを放り込めば es-loader がよしなに処理してくれるところが特徴となります。
es-loader
es-loader は取り込むログに応じてカスタマイズして利用することができます。 本ソリューションの最低限抑えておくべき機能をまとめました。
自動的に ETL 処理を行う
ETL 処理の中で正規化の必要性は発表中でも述べましたが重要なので改めて記載します。ログを複数種類管理していると当然のことながら、ログソースごとにフィールド名が異なる場合があります。
送信元IPアドレスのフィールド名が src.ip source.ip srcip sip など、バラバラです。
これらを正規化しない状態でいざ検索しようとしたときに Kibana で送信元IPアドレスが 10.10.10.1 であるログを検索したい場合のクエリは以下のようになります。*5

クエリが複雑化するため、SIEM を扱う上で正規化は前提条件であり、必要不可欠です。 この正規化には基準があり、Elastic Common Schema (以下、ECS)という定義に従っています。 新規のログソースを取り込む場合には上記のドキュメントを参考にマッピングします。*6
# ecs = ECSのフィールド名1 ECSのフィールド名2 # ECSのフィールド名1 = ログのオリジナルフィールド名 # ECSのフィールド名2 = ログのオリジナルフィールド名 ecs = destination.ip destination.port source.ip source.port source.mac host.hostname host.ip event.action network.transport destination.ip = dst destination.port = dpt source.ip = src source.port = spt source.mac = mac host.hostname = dvchost host.ip = dvc event.action = type failed_type network.transport = proto
AWS以外のログの取り込み
詳しくはこちらをご参照ください。主に以下2つの工程で取り込むことができます。
- aws.ini を参考に user.ini を定義する
- user.ini の標準的なマッピングで処理できない場合は、python スクリプトを siem ディレクトリ配下に配置する
|- user.ini
|- siem
|- sf_alb.py
|- sf_linux_dns.py
|- sf_vpcflowlogs.py
|- sf_windows_events.py
|- sf_他のログ種類.py
...
以下は、sf_vpcflowlogs.py を例に action の条件に応じて event.outcome の値を変更しているコードです。
def transform(logdata): action = logdata['event']['action'] if 'ACCEPT' in action: logdata['event']['outcome'] = 'success' elif 'REJECT' in action: logdata['event']['outcome'] = 'failure' else: logdata['event']['outcome'] = 'unknown' return logdata
es-loader 1つで AWS ログだけでなく、AWS 以外のログについても対応できるためログソースが増えても対応にかかる工数は最低限です。 定義する項目はやや多いように感じますが、コメントアウトされている説明文と例に従って迷うことなく定義できるようになっています。 加えて、標準的な ECS マッピングで処理できない場合に python スクリプトによる処理に対応しています。柔軟性を維持しつつ、シンプルに実装されています。
geoip で位置情報を付与する

定期的に Lambda 関数を用いてロケーション情報を取得し、S3 バケットに配置します。 配置された geoip を es-loader が読み込み、位置情報を付与するという仕組みになっています。

上記のように Answer というフィールドを元に位置情報を付与することができます。
考慮すべきこと
本アーキテクチャを最もシンプルに維持するために考慮すべき点を記載します。 試行錯誤して現在の状態になっていますが、今後 AWS のサービスが拡充されることで考慮不要となるところもあるためアップデートによる改善を期待しています。
全般的な考慮点
- ログソースごとに検索可能にしたい期間を定義する*7
- 起こりうる実際のインシデント発生時を想定して期間を決める
- Network に関わる情報量の大きいログは検索可能期間を短くしたり、監査など別の用途で利活用される可能性があるログは長期間検索できるようにする
- ログソースをS3に集める方法を考える*8
- 基本的にはS3レプリケーションを利用してログを配置しますが、現時点でレプリケーションには以下の制約があるため注意が必要です
- レプリケーション設定は複数指定できない
- レプリケーションされたオブジェクトを再度レプリケーションできない
- レプリケーションではなく、エクスポートで直接他のAWSアカウントを指定することも可能です
- 上記の制限がありますが、S3レプリケーションが一番シンプルです
- 基本的にはS3レプリケーションを利用してログを配置しますが、現時点でレプリケーションには以下の制約があるため注意が必要です
- オブジェクト所有者を送信先バケット所有者に変更する
- AWS 以外のログについても Fluentd や Logstash を用いてS3に集約する
- ログを蓄積するS3バケットの構成を考える*9
- ある程度大きな単位でトリガーとなるバケットは区切っておくと良い
- 弊社の場合はプロダクト部門/社内システム部門ごとにバケットを作成しました
- S3 オブジェクトが暗号化されている場合、es-loader で読み込みに失敗する*10
- 復号用の AWS KMS キーを生成、適用し管理する
{kind=link}
Amazon ES に対する考慮点
- 認証の方法を決める
- ドメインの配置方法を決める
- パブリックドメインかVPCドメインか
- ドメインのアクセスポリシーを定義する
- Amazon ES のインスタンスサイズとストレージ容量を見積もる*13
- ウォームノードの必要性と必要なストレージ容量を見積もる*14
- Index Template を作成し、有効化する*15
- ISM を有効化し、ログの検索可能期間をログソースに応じて設定する
- 大きなシャードは number_of_shards を指定し、データノードごとの負荷を分散する
- テンプレートのパラメータに order を活用して明示的に適用する
es-loader に対する考慮点
SIEM on Amazon ES は CloudFormation で Amazon ES ドメイン含めて一括でデプロイできます。 ドメインは作成済みで es-loader だけ利用したい場合は動作に必要な権限を設定し Lambda のみデプロイすれば動作します。
ひとまず構築からという方は手っ取り早く CloudFormation を利用して、あとからカスタマイズをすることで簡単に試すことができます。 es-loader に関してはパフォーマンスや ETL の手間を最小限にするために以下の点について考慮しておくと良いです。
- Elastic Common Schema を理解する
- まずはドキュメントと aws.ini を参考にどうマッピングされているか理解するところから始めます
- AWS以外のログソースはできる限り Beats を活用する*16
- 現在のところ様々な制約があり windows 関連は NxLog というソリューションでログを取得していますが、ECS にマッピングするのは至難の業なので、winlogbeat が良いです
- AWS以外のログをパースするときはできる限り正規表現で処理する*17
- regex1010.com をフル活用して組み立てました
- メモリサイズと関数タイムアウト時間を調整する
- 今のところ1024MB/10分程度が最適のようです*18
- geoip を元に位置情報を付与すると Lambda の処理が低速になる
- ログすべてに付与しているとパフォーマンスが劣化し、コストが増加するだけなのでログの中身を見て決める
- プライベートIPアドレスがメインな Flow ログは対象外としました
運用を初めてから
構築も終わり、現在のログ量は約300GB/日*19です。 ログの検索スピードに関しても文句ありません。もう爆速です。 今回作成したコード類は Github で一元的に管理されているため複数人でのメンテナンスを可能となっています。Elasticsearch と AWS のドキュメントを見ることで問題を解決することが可能になりました。 当たり前のことですが、しっかりと管理して複数人で共有できる状態となりました。まだ細かいところで属人的になっている部分ももちろんあります。 もっとシンプルにしてわかりやすい基盤にして行く必要があると思っています。
運用を開始していくつか更に課題が発生し、それらに対する対応について記載します。
パフォーマンスチューニング
行数の多いログファイルを処理する場合にエラーになる

今回は特に vpcflowlogs が1つのログファイルに100万行という物が存在し、Lambda がどう頑張ってもタイムアウトする問題がありました。これに対して、ログを一定量で分割し SQS に投げ、再度 Lambda を起動する es-loader の素晴らしいアップデート*20によりタイムアウトの問題を解消しました。AWS 以外のログでも出力側で容量の調整ができないものがあった場合に非常に有効的に機能します。

S3アクセスログで基盤が高負荷になる
これはまだ今後の残課題ではありますが、s3アクセスログが2時間に1回出力される仕様により定期的にドメインの負荷が上がります。Index Template によるシャード数の均等化や、Lambda の同時実行数を調整してもログの性質上平準化の効果はありませんでした。AWSサポートに対して要望は上げているところではありますが、そう簡単に実装されそうにないので es-loader 側で対処できるように頑張ります。

細かなエラーへの対応
正規表現の考慮漏れによるエラー
AWSのログはある程度フォーマットが統一化されているので良いのですが、独自に扱うログの中には攻撃的なスクリプトを含むログもあるため、想定していない文字列が含まれていたりもします。これを最初から完全に潰すのは難しく、長期間動作させてみて初めて見つかるエラーもあります。こちらのサイトを活用して最適な正規表現を構築しました。 忍耐力が必要ですが、実装自体はとてもシンプルなため、エラーが発生したときの調査にさほど時間はかかりません。
フィールドのデータ型の考慮漏れによるエラー
しばらく運用していると mapper_parsing_exception が発生しました。例えば、一番最初に読み込んだログのとあるフィールドがたまたま数値であり、動的に数値フィールドとして認識され、次のログの読み込みで文字列だったりするとエラーになります。こちらは適宜 Index Template を修正して対応しました。
コストへの影響
1日300GBを超えるログ量を取り込んでいるため、これを一般的なSIEM製品で実現しようとすると膨大なコストがかかります。 単純計算ですが、1/3 程度に抑えられているものと思います。 ただし、UltraWarm ノードが意外と高価で基盤にかかるコストの大部分が UltraWarm ノードです。 現時点でも十分なコストメリットを享受していますが、RI にも対応していないので今後の料金見直しや RI 対応で更なるコスト削減の可能性もあるという意味ではポジティブに今後のアップデートを期待しています。 そして、Lambda のコストも無視出できないレベルになってきました。1日数GBであれば月に数ドルですが、数百GBになると話は違ってきます。
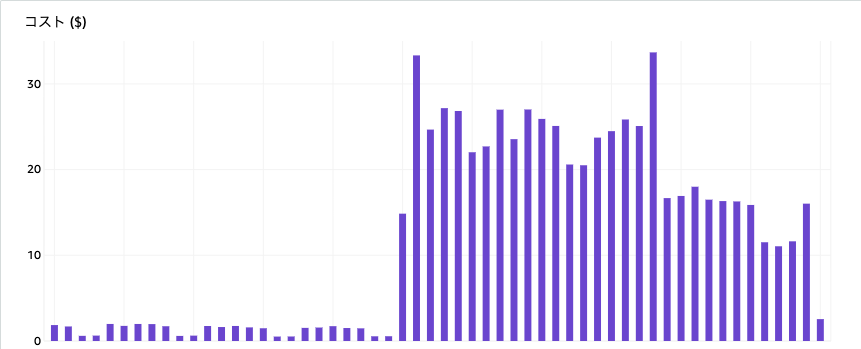
これに対しては、es-loader の処理速度を改善するか大規模用に es-loader をコンテナ化するなどして運用とコストのバランスを見ていきたいと考えています。 es-loader は EC2 上でもバッチとして動作させることはできますが、現時点では Lambda で動作させた方が可用性も高く、運用面でもメリットがあります。
今後の取り組み
基盤は作ったら終わりではありません。組織全体のログも一括管理し横断的に検索できる状態にもっていきます。 社内で起きたインシデントがプロダクト側へ影響していないとは言い切れません。その逆もです。 横断的な検索の一歩先としては、ペネトレーションテストやパープルチーミングを活用し、まずはしっかりと組織の弱点を特定します。 場当たり的な対応ではなく、本基盤を活用し事象を特定します。特定できなかった事象を弱点として、効果的な対策を実施するフィードバックループを回して行こうと考えています。 また、es-loader に対して自動的に IOC を収集して悪性ドメイン及びIPアドレスとマッチングさせるような機能も開発される予定があります。 今後は更に SIEM on Amazon ES を有効活用し、もしもの時の検索基盤では無く、違和感を早期に発見するための最高の SIEM を作り上げたいと思っています。
*1:Splunk は非常に便利ですが高価です。Splunk Cloud 等も検討しましたが、インフラ部分とライセンス価格合わせると年間数千万クラスになってしまうことがわかり断念しました。
*2:EC2 上で動作させていたので、そりゃもう運用が大変でした。
*3:現時点においては、インシデント発生時に分析者のバイアスを軽減する使い方が頻度としては高いです。他のセキュリティ製品の検知をトリガーとしてログが正しいか、間違った分析をしていないかを別の視点で確認します。基礎をしっかりと構築した際には、更に踏み込んで SIEM 本来のインシデントを発見し管理するという領域と向き合います。
*4:コード類はすべて Github で管理し、デプロイも CodeBuild や CodePipeline を利用して実施するようにしました。
*5:場合によってはもっと長文のクエリを完成させなければなりません。これでは一刻を争う有事の際に非効率になる原因にもなりますし、各ログソースの中身を細部まで知っている人しか扱うことができません。
*6:ログソースが src であれば、source.ip にマッピングする。
*7:ストレージ容量の算出や ISM を設定する上で必要になります。
*8:S3に集められればどんな方法でも良いかと思いますが、煩雑にならないようにできる限り手法は絞って実現できないかまずは検証頂くと良いです。S3に入ってさえいれば ETL 処理に失敗しても検索できるなくなるだけでログの欠損はなく安価で長期間保管することができます。
*9:すべて同じバケットに配置しても良いですが、FGAC のアクセスコントロールでバケット名単位で制御するようにしました。管理面や制御をどうしたいかでバケットの構成を考えると良いと思います。
*10:GuardDuty はデフォルトで暗号化されている
*11:現在のところ後から変更できないため、予めどうすかを決めておく必要があります。初期の設定がやや複雑になりますが、非常に便利なので有効化しておくと良いです。
*12:SAMLに関してはこちら。ユーザ管理にIAMを利用する場合はKibanaにCognito認証を有効化する設定が必要です。
*14:UltraWarm を利用することで、大容量のログを長期間検索可能な状態にできます。
*15:こちらを参考に作成しました。シャードの容量にもよりますが、データノードの負荷を均等にするために number_of_shards を指定します。order パラメータを用いて適用されるテンプレートの優先順位を明示的に指定します。重複するパラメータは order 値の高いテンプレートで上書きされます。
*16:Beatsファミリーをログ収集エージェントとして Fluentd または Logstash 経由でログをS3に格納することで、予め ECS にマッピングされたログが取得されているため正規化の処理が不要になります。
*17: re モジュールが最も高速です。下手にモジュールを追加するとパフォーマンスが劣化します。
*18:ETL処理の時間と Lambda 利用料とのバランスなので、引き続き最適な値を探します。
*19:2年前は10GB/日程度でした。将来的に約600GB/日になることが予測されます。
*20:es-loader v2.1.0-beta1 以降で対応しています。現時点ではまだ develop ブランチで利用できる機能となっているようです。