
本記事はSansan Advent Calendar 2024、18日目の記事です。
はじめに
こんにちは、研究開発部 Automationグループの李欣耘(リキンウン)です。普段はBill Oneの請求書情報に関する作業効率改善に従事しています。
早いもので今年も残すところあと少しです。皆さまはいかがお過ごしでしょうか。先日あざだらけでREDLINEから帰ってきた私は、今年トータル31本のフェスやライブも行ったせいで、とてつもなくお金に困ってます。
今日は、気づいたらversion.11まで公開されたYou Only Look Once(以下、YOLO)について、話していきたいと思います。至らない部分もあると思いますが、ご参考になれば幸いです。
YOLOとは?
YOLO(You Only Look Once)は、画像や動画から物体をリアルタイムに検出するためのアルゴリズムです。初めて登場したのは2016年のYOLOv1 [1]で、当時から「速さと検出精度を両立させた」と話題になりました。それ以降、数々の改良を経て、幅広い分野で活用されています。
YOLOでは図1に示すように、画像をグリッドセルとして扱い、それぞれのセルがバウンディングボックス(以下、BBox)を物体に当てはめる役割を担っています。それと同時に、クラス確率(例えば、P(couch|object))も計算されます。最後に、同じクラスとして認識された重なっている状態の領域を抑制するため、Non-MaximumSuppression(以下、NMS)処理を行い、BBoxとクラスラベルが出力されます。「この辺にソファーがあるよ」とか「こっちはテーブルだよ」といった結果を教えてくれます。

他の物体検出器と比べてみた
物体検出といえば、世の中にはYOLO以外にもいろいろな物体検出アルゴリズムがあります。ここでは、代表的なアルゴリズムとYOLOを比較してみます。
- Faster R-CNN [2]
- 物体検出器の中に、初めてend-to-endで検出できるようになったモデル
- 精度がめっちゃ高いけど、その分処理速度が遅め [3]
- K40を使用する際の速度:5 FPS (VGG [4])
- mAP: 37.0% (COCO [5], ResNet101 [6])
- SSD (Single Shot MultiBox Detector) [3]
- YOLOと同じく、物体の検出とクラス識別を同時に行う
- 速さと精度のバランスが特徴
- Nvidia TitanXを使用する際の速度:59 FPS
- mAP:74.3% (VOC2007 [7])、25.1% (COCO [5])
- DETR (DEtection TRansformer) [8,9]
- TransformerのAttentionメカニズムを用いて物体検出を行う
- 提案領域生成やNMSを省略し、end-to-endで学習する
- 高精度で、複雑なシーンに対応可能
- mAP: 54.3% (COCO [5], ResNet101 [6])
- デメリットとして、計算コストが高く、リソースを多く消費する
- T4 GPUを使用する際の速度:74 FPS (ResNet101 [6])
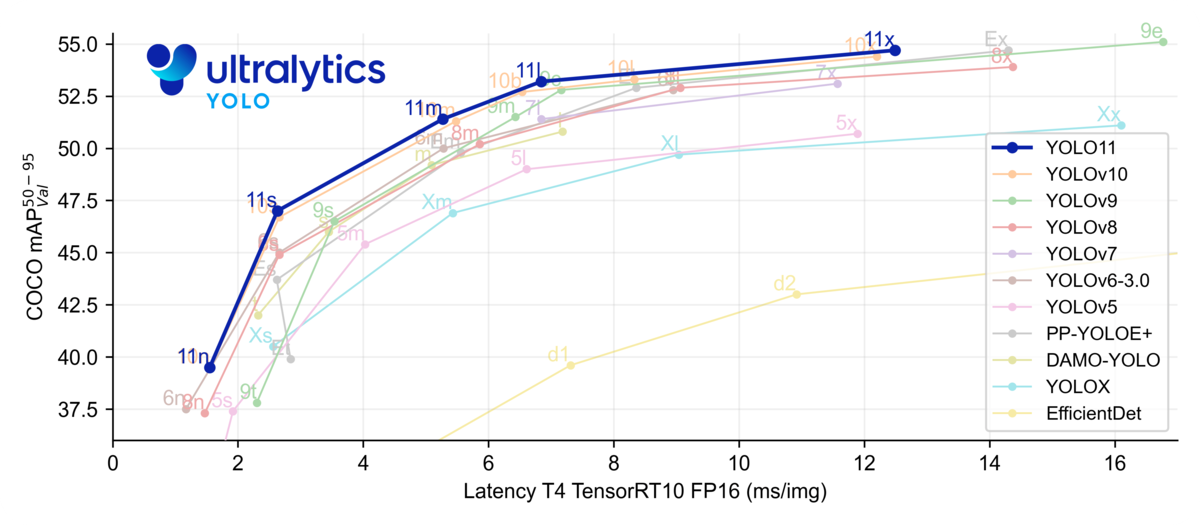
YOLOは高速処理で、シンプルな設計から扱いやすいことがよく知られています。精度は最近かなり改善され、用途に応じて多彩なバージョンを選べるようになりました。最近公開されたYOLOv11x [6] はCOCO [5] で評価した結果、mAPは53.4%、Amazon EC2 P4dインスタンスのT4 TensorRT10を使用する際の処理速度は11.3 ± 0.2 [ms] でした。
自身の独断と偏見ではありますが、上記の調査をまとめた結果は以下に示します:
| YOLOv11x | Faster R-CNN | SSD300 | DETR | |
|---|---|---|---|---|
| 速度 | ◎ 非常に速い | × 遅い | ◯ 速い | △ やや遅い |
| 精度 | ◯ 高い | x 低い | ◯ 高いデータセットもある | ◎ 非常に高い |
| 用途 | リアルタイムアプリケーション | 精密な解析や学術研究 | バランス重視の応用 | 高精度検出が必要な場面 |
進化の軌跡
YOLOの進化の歴史をざっと振り返ると、こんな感じです:
| バージョン | 特徴 | 主な改良点 | ライセンス |
|---|---|---|---|
| v1 | シンプルで高速 | グリッドベースの制約 | MIT |
| v2 [10] | Anchor Boxes, YOLO9000 | 9000以上の多様なクラスに対応 | MIT |
| v3 [11] | FPN, Darknet-53 | スケール対応 | AGPL |
| v4 [12] | BoF, CSPDarknet53 | 高効率性 | Apache |
| v5 [13] | PyTorch, 軽量 | 高速トレーニング | AGPL |
| v6-8 [14,15,16] | 小型デバイス向け最適化 | 新アーキテクチャ | GPL |
| v9, 10 [17,18] | 効率的・高速 | パラメータの効率化 | 9:GPL, MIT, 10:AGPL |
| v11 [19] | 高汎用性・効率的 | 多様なタスクに対応 | AGPL |
v5から軽量化されたり、v6-8で小型デバイス向けにも最適化されたり、単なる精度の向上だけでなく、効率や適用可能性にも注力しているのが分かります。また、クラスの多様性に対応できて、現場のニーズに応じた柔軟性を意識しているのが印象的です。
わかりやすいため、v3とv7を適用した結果を示します。間違って検出されたchairをtableと、benchをchairと正しく検出できて、確信度も向上できました(presonラベルは可視化の簡潔性に妨げるため、省略しました。)モデルが良くなったことが目で見てわかります。

さらに、まだ論文化されていませんが、YOLOv11 [21] もあります。検出、セグメンテーション、追跡など、さらに幅広いAIタスクに対応できるようになっています。以下の図3に示すように、従来のYOLOシリーズの強みを継承しつつ、より少ないパラメータでより高い精度と速度を実現し、多様なコンピュータビジョンタスクに対応する効率的で適応性の高いモデルです。
YOLOの考察
YOLOシリーズは、その革新的なアプローチと継続的な改善により、物体検出の分野で確固たる地位を築いてきました。
強みと特徴
高速処理:
- リアルタイムで物体を検出できるっていう速さがYOLOの一番の魅力。監視カメラとか、自動運転車みたいな「今すぐ判断しなきゃ」ってシチュエーションで頼りになります。
汎用性:
- 「これって検出できるの?」みたいな物体も大体検出できます。いろんな分野で使える万能感があります。
シンプルなアーキテクチャ:
- アーキテクチャが他のアルゴリズムに比べてシンプルだから、実装するのも楽です。「とりあえずYOLOで試してみるか」って感じで使い始める人も多いです(私もそうです)。
課題と制約
小さな物体の検出精度:
- 初期のバージョンだと、特に「小さな物体を見つける」っていうのが苦手でした。例えば、群衆の中のスマホとか、広い空に浮かぶドローンとか。最近のバージョンでだいぶ改善されてるけど、完璧とは言えないかもです。
背景との類似性:
- 背景と似たような色とか形の物体を検出するのが難しいときがあります。「カモフラ柄のバッグどこ!?」みたいな状況だと、ちょっと苦戦します。
高解像度画像の処理:
- 高解像度の画像を扱うと、結構計算リソースを食います。しかし、v11ではSlicing Aided Hyper Inference [22]が用いられたため、ある程度カバーしてるみたいです。
YOLOの派生モデルと応用
YOLOは物体検出界隈で「革新」って言われるくらいスゴイ技術です。そのアイデアの汎用性が高すぎて、いろんな分野に応用されまくってます。最近のバージョン、特にYOLOv8以降では、物体検出だけじゃなくてセグメンテーションや姿勢推定といった複数のタスクも同時にできるようになりました。
そして最近だと、なんとレイアウト分析 [23] に特化したモデルまで登場してます。ドキュメント解析とかにめっちゃ役立ちます。
さらに2024年に公開されたYOLOv9は、 PGI(Programmable Gradient Information)とかGELAN(Generalized Efficient Layer Aggregation Network)という技術を組み込んで、精度も速度もとてもアップしてます。
こういう進化のおかげで、YOLOはますます多くの産業で使われるようになってます。監視カメラ、ドローン、自動運転車、さらには工場の自動化まで、YOLOを使った画像や動画の解析が重要になってきています。
なんでそんなにバージョンが多いの?
「なんでYOLOってこんなにバージョンが多いんだ?」と思ったことはありませんか?理由を調べてみると、ちゃんと納得できる話がありました。
継続的な性能アップ
- まず、「もっと速く、もっと正確に」っていう目標があって、研究者たちが新しい技術やアーキテクチャをどんどん試してるんです。
- 例えば、「前のバージョンだと小さい物体を見つけるのが苦手だったけど、次ではちゃんと対応しました!」みたいな感じで進化しています。
- そして、どのバージョンも「少ない計算リソースでどれだけ性能を出せるか」をひたすら追求しています。
ユースケースが多すぎる
- 世の中にはいろんな用途があります。大きなサーバーでがっつり動かす場合もあれば、小さいエッジデバイスでさくっと動かしたいこともあります。
- それぞれに合わせてYOLOを調整する必要があるので、「モバイルアプリケーションにはより軽量のv6が最適!」とか「医療画像解析や自動運転とか高精度が求めれれている時はv8がいい!」みたいに、使い分けができるようになっています。ただし、最新のモデルの方が速いし精度も良いので、とりあえず最新のバージョンを試すのが無難だと思います。
コミュニティの力
- 最後に、これが一番の理由かもしれません。YOLOはオープンソースなので、世界中の研究者や開発者がどんどん改良を提案しています。
- 元祖の提案に関しては、商標として登録してないので、新しいアイデアが次々と出てくると、勝手に新バージョンにアップデートされます。
でも、名前はずっとYOLOのままなんですけど?
バージョンはどんどん増えてるのに、名前はずっとYOLOです。「なんで変わらないの?」と不思議に思ったので、こちらも理由を調べてみました。
根本はずっと同じだから
- YOLOの基本アイデアは、「物体の検出とラベル認識を同時に行う」ことです。この革新的なアプローチ自体は変わってないので、名前を変える必要がありません。
- ただ、内部の細かいところはバージョンごとにちょっとずつ進化しています。
ブランド力がある
- YOLOって名前、めちゃくちゃ有名です。機械学習の界隈では「YOLO」と言えばすぐに何のことか通じるくらい認知度があります。
- 名前を変えちゃうとそのブランド力が薄れるリスクがあるので、バージョン番号で進化を示すスタイルを採用してるみたいです。
論文とか引用のしやすさ
- 研究者にとって、論文や研究成果を引用するときに名前が変わるとややこしいです。
- その点、YOLOは名前がずっと一緒なので、「YOLOを使った研究」と言えば世代を超えて通じるというメリットがあります。
まとめ
YOLOは物体検出の分野でめちゃくちゃ注目されているアルゴリズムです。進化のスピードが速すぎて追いかけるのが大変だけど、その分、新しいバージョンが出るたびにワクワクします。来年もさらに面白いアップデートがありそうなので、引き続き注目していきたいです。
参考文献
[1] Redmon, et al. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 779-788.
[2] REN, et al. Faster R-CNN: Towards real-time object detection with region proposal networks. In IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), vol. 39, np.6, 2016, pp. 1137-1149.
[3] Liu, et al. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), 2016, pp. 21–37.
[4] Simonyan, at al. Very Deep Convolutional Networks for Large-Scale Image Recognition. In International Conference on Learning Representations (ICLR), 2015, pp. 1-14.
[5] Lin, et al. Microsoft COCO: Common Objects in Context. In European Conference on Computer Vision (ECCV), 2014, pp. 740-755.
[6] He, et al. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770-778.
[7] Everingham, et al. The Pascal Visual Object Classes (VOC) Challenge. In International Journal of Computer Vision (IJCV), vol. 88, no. 2, 2010, pp. 303–338.
[8] Carion, et al. End-to-End Object Detection with Transformers. In European Conference on Computer Vision (ECCV), 2020, pp. 213-229.
[9] Lv, et al. DETRs Beat YOLOs on Real-time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 16965-16974.
[10] Ultralytics. https://github.com/ultralytics/ultralytics/tree/main?tab=readme-ov-file. Last access: 2024/12/12.
[11] Redmon, et al. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 7263-7271.
[12] Redmon, et al. YOLOv3: An Incremental Improvement. arXiv preprint arXiv:1804.02767, 2018.
[12] Bochkovskiy, et al. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv preprint arXiv:2004.10934, 2020.
[14] Ultralytics. YOLOv5: Improved Object Detection. GitHub repository, 2020.
[15] Li, et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv preprint arXiv:2209.02976, 2022.
[16] Wang, et al. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 7464-7475.
[17] Jocher, et al. YOLOv8: State-of-the-art Real-Time Object Detection. Ultralytics, 2023.
[18] Wang, et al. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv preprint arXiv:2402.13751, 2024.
[19] Wang, et al. YOLOv10: Real-Time End-to-End Object Detection. arXiv preprint arXiv:2405.14458, 2024.
[20] Meng-Jiun Chiou, et al. In Proceedings of the ACM International Conference on Multimedia (ACM MM), 2020, pp. 3431–3440.
[21] Ultralytics. Ultralytics YOLO11. https://docs.ultralytics.com/ja/models/yolo11/. Last access: 2024/12/08.
[22] Ultralytics. Ultralytics ドキュメントYOLO11 、スライス推論にSAHIを使用する. https://docs.ultralytics.com/ja/guides/sahi-tiled-inference. Last access: 2024/12/10.
[23] ZHAO, et al. Doclayout-yolo: Enhancing document layout analysis through diverse synthetic data and global-to-local adaptive perception. arXiv preprint arXiv:2410.12628, 2024.