DSOC R&D アーキテクトの鷹箸です。
今回は、R&D が提供している一部サービスを EC2 での運用から ECS/Fargate に移行した話をします。
R&D では研究開発したものを Sansan や Eight に WebAPI として提供しており、現状稼働している様々なサービスの基本的な構成は EC2 に WebAPI を立てて、手動で必要に応じたスケーリングを実施しています。
要約
- R&D サービスを EC2 から Fargate に移行した
- 負荷に応じてオートスケーリングしてくれるようになった
- リリースも自動化して運用が楽になった
なぜ移行したか
WebAPI へ定期的にバッチで大量のリクエストを送りたいという要望があり、着手に至りました。 この要望が来る以前は、40万件/日を捌く程度だったので、特にスケーリングも発生せず安定稼働させていました。 しかし、要望では一回のバッチ処理の総リクエスト数は数億件となりました。 適宜バッチ処理が走るタイミングで数億件を捌けるようにスケーリングする方法でもよかったのですが、失敗したときに再実行したいとか予期しないコミュニケーションが発生することを考えると、オートスケーリングさせて好きなように好きなだけ叩いてもらえるようにしておくと運用を気にせず楽になるということで移行が始まりました。
Fargate という選択
コンテナオーケストレーションサービスの選択肢としては ECS/EC2 、 ECS/Fargate、 EKS がありますが、今回は ECS/Fargate を選択しました。
メリット
- EC2 を管理しなくて良い
- AWS が後ろでどうにかしてくれるので、こちらが意識することはない
- リソースの割り当てが柔軟
- メモリは 0.5 ~ 30 GB 、vCPU は 0.25 ~ 4 vCPU の間でアプリケーションに合わせて無駄なくカスタマイズできる
- スケーリングの設定が簡単
- CPU使用率やメモリ使用率、ALBへのリクエスト数で設定可能
デメリット
- コンテナに入り、デバッグができない
- EC2 に比べて高価 *1
システムの全体構成
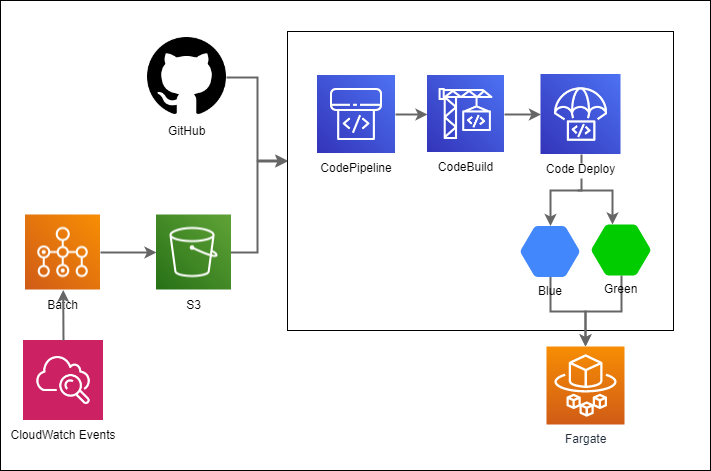
デプロイとリリース
このアプリケーションの場合、リリースのタイミングは2種類(モデルデータの更新とソースコードの更新)あります。 モデルデータは月に1回定期更新を実施しており、S3 へモデルがアップロードされたタイミングでパイプラインが、ソースコードの更新時には GitHub と連携したパイプラインが、それぞれ走るようになっています。
コンテナの運用
アプリケーションのコンテナにはモデルデータを含めない運用をしています。モデルデータの管理については環境変数に S3 のパスを入れてイメージの立ち上がり時にダウンロードしてくるようにしています。 コンテナにモデルデータを含めない理由は、モデルデータのサイズが 5GB ほどあるためイメージに含めるには大きい(データサイズは毎月増加傾向)ことやモデルデータの更新頻度はソースコードの更新頻度より高いため、モデルデータ更新の度にコンテナのビルドを行うよりモデルデータの更新のみを実施したほうが効率的だと考えたためです。ただし、この方法だと運用を始めるといつ時点のモデルデータを使っているのかわからなくなるため、モデルデータのバージョンを取得するエンドポイントを用意しています。
デプロイフロー
デプロイフローについては、前述の通り GitHub や S3 をフックして自動で走り始めますが、モデルデータの更新では適用するデータが問題ないかどうかを人の目でチェックするフェーズ( CodePipeline の手動承認)を設けています。 デプロイには CodeDeploy の Blue-Green Deployment を採用しており、問題が発生した場合にはワンクリックでロールバックできるので安心してデプロイできます。
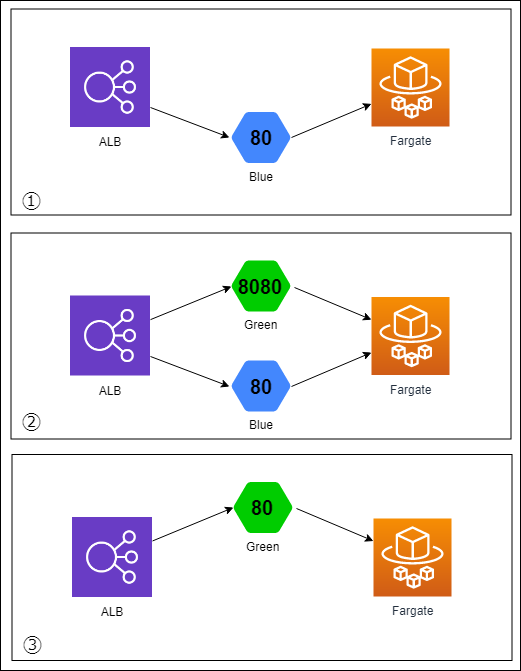
オートスケーリング
ECS/Fargate では、スケールアウトとスケールインが簡単に設定できます。CPU使用率やメモリ使用率、ALBへのリクエスト数で設定が可能ですが今回はCPU使用率を基準にスケーリングしています。ここで注意したいのが、スケールアウトクールダウン期間とスケールインクールダウン期間です。 それぞれ短くしすぎるとCPUの振れ幅が大きい場合にタスク数の増減が激しくなります。リクエストの増減に素早く対応したいと気持ちが急ぎますが、結果としてパフォーマンスが悪くなる可能性があります。今回は、スケーリングする際のCPU使用率を 60%、スケールアウトクールダウンは 60秒、スケールインクールダウンは 600秒に設定して安全に倒しています。
また、タスクがロードバランサに繋がる際の設定値にヘルスチェックの猶予期間があります。ここで設定した時間内はヘルスチェックの判定を無視してロードバランサに接続されることはありません。今回のコンテナは立ち上がり時に S3 からモデルデータをダウンロードしてメモリにロードするまでにそこそこ時間がかかるため、十分な時間を確保してからロードバランサに接続されるようにしています。
おわりに
今回は EC2 から ECS/Fargate への移行を実施しました。 Fargate のデメリットに価格が高いことを挙げましたが諸々調整した結果、最小のタスク数で運用している場合は EC2 での運用とさほど変わらない費用で運用できています。 ECS/EC2 でスポットインスタンスを使えば安くなりそうですが運用面でのメリットが大きいため、多少のコスト増は目を瞑ることにしています。
また、移行が完了してバッチからも数億件の処理が何度も行われていますが、今のところ運用やコミュニケーションに時間を取られたことはなく、日々の運用を意識することなく安定稼働していていい感じです。
R&D では今後もコンテナオーケストレーションの導入を進めていきます。
*1:2019年1月に値下げされて vCPU は 20% 、 メモリは 65% 安くなった