iOSエンジニアの堤です。先日3月28日に開催された弊社主催のLTイベントで、「WhisperKitがだいぶ良いので紹介する」というタイトルで発表しました。
スライドはこちら:
本記事は、同発表をベースとしつつ、(LTでは時間が足りないので)発表ではカットした内容を盛り込んで記事として再構成したものになります。
WhisperKitとは
iOS/macOSオンデバイスで動く音声認識のすごいやつ
- 速い
- 精度も良い
- 多言語対応(日本語含む)
- オープンソース
デモ:標準の音声認識フレームワークSpeechとの比較
音声ファイルの書き起こし速度を比較 1 してみた。
Speech
→ 15分の音声ファイルの書き起こしに6分程度かかる。 2
WhisperKit
WhisperKitによるiOSオンデバイス音声認識、Releaseビルドで試すとさらに爆速でした。15分の音声ファイルの書き起こしが51秒で完了。baseモデル利用、デバイスはiPhone 15 Pro。 pic.twitter.com/He3a0FQntn
— 堤修一 / Shuichi Tsutsumi (@shu223) 2024年3月27日
→ 15分の音声ファイルの書き起こしが51秒で完了。
なぜ速いのか - WhisperKitの系譜
OpenAI Whisper
- OpenAIによって開発された音声認識モデル
- 精度とパフォーマンス、そしてオープンソースであることから利用が一気に広がった
whisper.cpp
- Whisperの高速推論版
- 各種プラットフォームへの最適化もされている
- macOS/iOS向けにはMetal, Accelerateもサポート
- Core MLモデル版もリリースされている
関連:
Core ML とは
- 機械学習モデルをiOS、macOS、etc. に組み込むためのApple製のフレームワーク, モデルフォーマット
- CPU・GPU・Neural Engine (ANE) を利用し、メモリ占有量と電力消費量を最小限に抑えつつパフォーマンスを最大限に高めるように設計されている
関連:
whisper.cpp から WhisperKitへ
- whisper.cpp の Core ML版よりもさらにAppleハードウェアを活かすようカリカリに最適化
- Core ML版 whisper.cpp より 1.86倍〜2.85倍 高速 3
argmax社とApple
- 開発元のargmax社は Appleの
ml-ane-transformersリポジトリの中の人の会社 - つまりそもそもTransformerモデルをCore MLで最適化してiOS/macOSで動かせるようにする流れ 4 の元祖にあたる人(たち)が最適化を行っている
モデルサイズとメモリ消費量
各モデルのファイルサイズ一覧
| WER | File Size (MB) | |
|---|---|---|
| large-v2 | 2.77 | 3100 |
| large-v2_949MB | 2.4 | 949 |
| large-v2_turbo | 2.76 | 3100 |
| large-v2_turbo_955MB | 2.41 | 955 |
| large-v3 | 2.04 | 3100 |
| large-v3_turbo | 2.03 | 3100 |
| large-v3_turbo_954MB | 2.47 | 954 |
| distil-large-v3 | 2.47 | 1510 |
| distil-large-v3_594MB | 2.96 | 594 |
| distil-large-v3_turbo | 2.47 | 1510 |
| distil-large-v3_turbo_600MB | 2.78 | 600 |
| small.en | 3.12 | 483 |
| small | 3.45 | 483 |
| base.en | 3.98 | 145 |
| base | 4.97 | 145 |
| tiny.en | 5.61 | 66 |
| tiny | 7.47 | 66 |
WhisperKitの各モデルのWER (Word Error RATE) とファイルサイズ 5
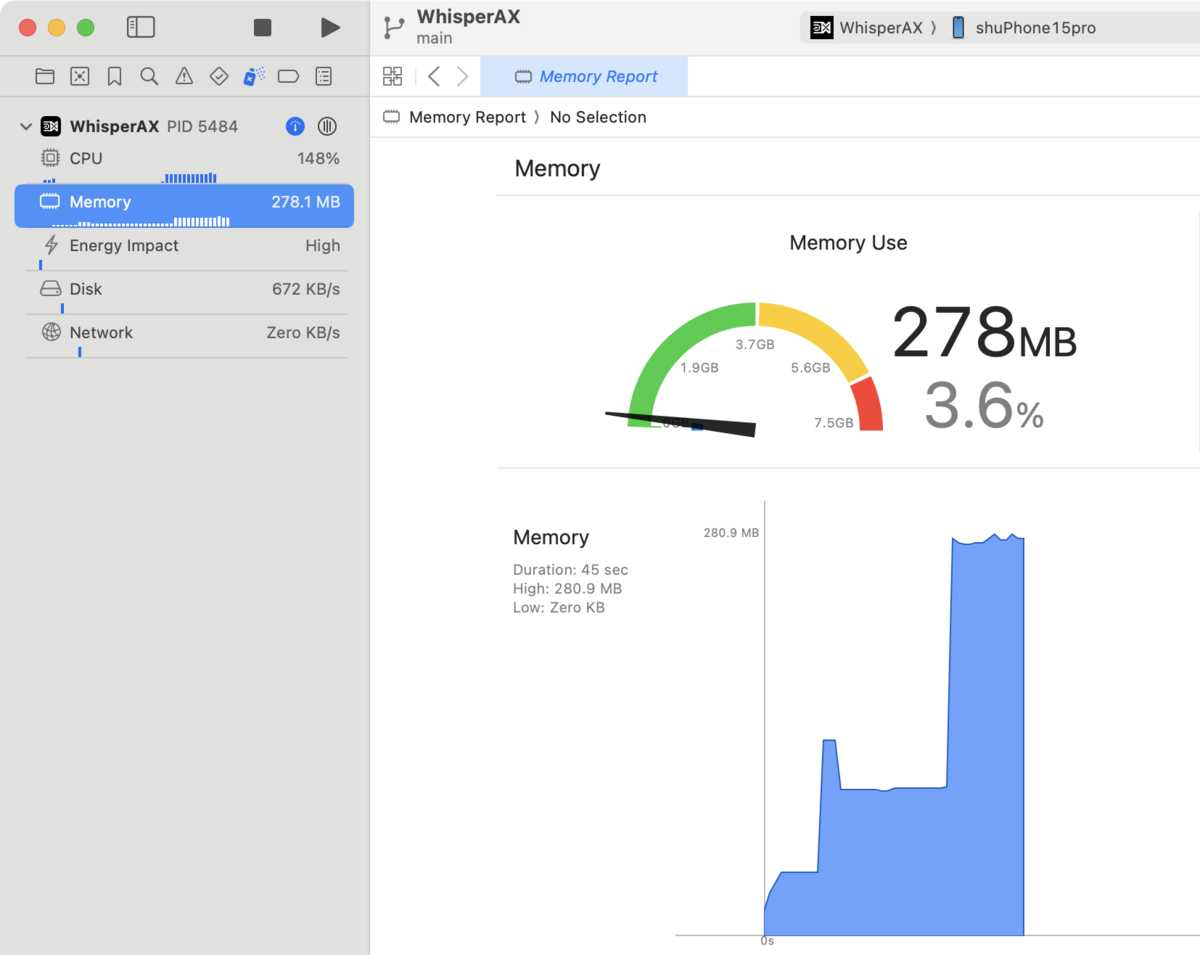
メモリ使用量
最大で300MB未満程度(baseモデル使用時)
アプリへの組み込み方法
Swift Packageを使って 2行 で実装可能
let pipe = try? await WhisperKit() let transcription = try? await pipe!.transcribe(audioPath: path)?.text
本当に2行で実装できるのか?
本当に2行で実装しているの?というところをサンプルコードを追いかけてみた記事がこちら:
more
Swift CLI
- インストール
brew install whisperkit-cli
- 実行
swift run whisperkit-cli transcribe --model-path "foo" --audio-path "bar"
変換ツール
- PyTorchのWhisperモデルをWhisperKit向けに変換するためのPythonツール
- 自前のWhisperモデルをWhisperKitフォーマットに変換できる
詳しい技術解説記事
自分用に整理した記事がこちら:
まとめ
Core ML版WhisperであるWhisperKitを紹介した。
- 速度よし、精度よし
- 多言語対応(日本語含む)
- オープンソース/変換ツールも公開
- ⇒ 自前モデルも利用可能
- Swift Packageで簡単に実装可能
→ iOSオンデバイス音声認識の選択肢として最有力候補では!

- どちらもオンデバイス処理。iPhone 15 Proを利用。↩
- Speechも、これでも昔よりはだいぶ速くなりました。2020年頃に同様の実装で試したときは、実時間での認識が精いっぱい(15分の音声ファイルの書き起こしにほぼ15分かかる)でした。↩
- 出典: WhisperKit — Argmax↩
- Core ML版Stable Diffusion や、ローカルLLMのApple Silicon向け最適化 等々↩
- WERは低いほど精度が高いことを示す。表の出典は https://huggingface.co/argmaxinc/whisperkit-coreml↩