研究開発部Architectグループの堤です。最近は研究開発部の技術や成果物について紹介する記事をいくつか書いてきたのですが、 今回は、下記記事で紹介した"Smart Captured"(略してスマキャプ)の開発の中で行った「Core ML化」について深堀りしたいと思います。
今回のテーマ
上に載せた記事内で、スマキャプでは以下の機械学習モデルの推論処理をオンデバイスで行っている、と書きました。
- 名刺検出(名刺の矩形を検出)
- 名刺切り出し(セグメンテーション)

それぞれのモデルはTensorFlowで学習しています。
さらにiOSでは、モデルをCore MLに変換することで、大幅なパフォーマンス向上に成功しています 1。
- 矩形検出は300%高速化(18 fps → 55 fps)
- セグメンテーションも推論時間は0.01〜0.02[s]
さらに、機械学習モデルの推論処理のためのCPU負荷が下がることで、UIの描画やユーザーインタラクションのレスポンスも改善されます。下図は、変換前・後のモデルを切り替えてCPU使用率を可視化したものになります。
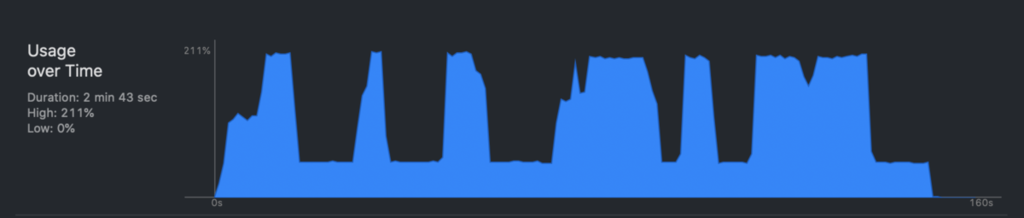
本記事ではこのCore ML化の具体的な手順や勘所について、詳しく解説します。
なぜCore ML化すると速くなるのか
そもそもなぜCore ML化すると速くなるのか、について解説しておきます。
Core MLは、機械学習モデルをiOS, macOS, watchOS, …に組み込むためのApple製のフレームワーク, モデルフォーマットなのですが、
iOSで機械学習モデルの推論処理を行うための選択肢はCore ML以外にもいくつかあります。
- TensorFlow for iOS (TensorFlow Mobile) 2
- TensorFlow Lite
- PyTorch Mobile (LibTorch)
ただし、TensorFlow for iOS (TensorFlow Mobile) や PyTorch Mobile (LibTorch) では、すべてがCPUで処理されます。また TensorFlow Lite はGPU (Metal) をサポートしていますが、Neural EngineはそもそもAPIが公開されていないため、Apple公式で提供されているモデルフォーマットであるCore MLを利用する以外にNeural Engineで処理させる手段がありません。
まとめると、以下のようになります:
- TensorFlow for iOS (TensorFlow Mobile) → CPU
- TensorFlow Lite → CPU, GPU
- PyTorch Mobile (LibTorch) → CPU
- Core ML → CPU, GPU, Neural Engine
Core MLがiOSデバイスの性能を最も活かせる(ので、Core ML化すると速くなる)というわけです。
Neural Engineについて
Neural Engineは、ニューラルネットワークの演算を高速処理するプロセッサです。ANE (Apple Neural Engine) とも呼ばれます。
ANEはNPU (Neural Processing Unit) の一種で、ANE以外でNPUで有名なものとしてはGoogleのTPUがあります。 3
ANEは2017発売のiPhone 8, iPhone X以降のiPhone / iPadに搭載されていますが、Core MLによって利用されるANEは2018年発売の(iPhone XSやXRに搭載されている)A12 Bionic以降となります。
ANE自体の性能も毎年上がっています。 4
The A14 has a 16-core Neural Engine that is twice as fast as the previous generation, and can perform 11 trillion operations per second.
The A15 has a 16-core Neural Engine, with the same amount of cores it can perform 15.8 trillion operations per second (43% faster than the previous generation).
すなわち、ここ数年に発売されたiOSデバイスの多くでは、機械学習モデルのCore ML化による高速化が期待でき、最新デバイスほどさらにその恩恵は大きくなる、ということになります。
Core MLモデルへの変換
さて、本記事の本題であるCore MLモデルへの変換について解説していきます。
変換には、coremltools というApple製OSSツールを利用します。
https://github.com/apple/coremltools
coremltoolsのバージョンについて
2022年11月22日現在の最新バージョンは6.1となります。
スマキャプでのCore MLモデル変換に当時利用したバージョンは3系でした。
coremltools 4.0からUnified Converterが登場して、TensorFlow, PyTorchのモデルが同じAPIで変換できるようになったのですが、3系ではTensorFlowモデルからCore MLモデルへの変換には tf-coreml というツールを利用する必要がありました。
https://github.com/tf-coreml/tf-coreml
本記事では当時のバージョン(tf-coreml)をベースに説明しますが、ツールの使い方、エラーと対峙する際の考え方は最新版でもほぼ同じです。
変換してみる
tfcoremlを利用してTensorFlowモデルを変換してみましょう。引数には入力モデルのパス、出力パス、入出力ノード名やshapeを与えます。
import tfcoreml mlmodel = tfcoreml.convert( tf_model_path = tf_model_path, # .pbモデルのパス mlmodel_path = mlmodel_path, # .mlmodel出力パス input_name_shape_dict = in_dict, # 入力ノード名とshape output_feature_names = out_names, # 出力ノード名 ...)
これを名刺検出モデルに対して実行してみると・・・
ValueError: Graph has cycles.
このようなエラーが出ました。
調べてみると、次のように説明されています。
CoreML does not support graphs with cycles at the moment. However, it does support recurrent nodes (RNN, LSTM, GRU etc). When these cells are implemented in TF, they get broken down into cyclic graphs in the frozen .pb file. tfcoreml cannot handle such graphs at the moment. This is a known issue currently. Handling such graphs would require going from the broken down graph structure to the higher level structure and mapping the nodes to an operation that CoreML supports (RNN, LSTM etc).
TFで出力したモデルは、Core MLがサポートしていない循環のあるグラフを生成することがあるようです。
実は、同様のエラーは、(メッセージこそ違いますが)coremltoolsの新しいバージョンでも、変換元がPyTorchモデルである場合でも発生します。 5
こういった場合に、どのように解決していくかを解説します。
coremltoolsの変換エラーを解決する
どこが代用可能か?
今回は "Graph has cycles." エラーということで、循環を構成している部分を切除し、coremltoolsで変換可能な計算グラフにします。
まずはモデルのグラフを見て、切り出す部分のあたりをつけます。
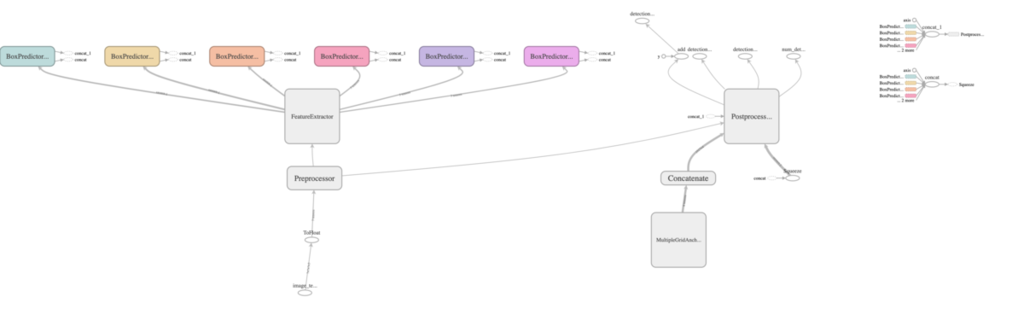
ポイントは、グラフの当該部分を別の手段で代用できるのであれば、そこは切除可能、ということです。
Preprocessor部分は変換コマンドのオプションで付与MultiGridAnchorGeneratorは静的な値で代替可能Postprocessorは同様の処理をSwiftで実装可能
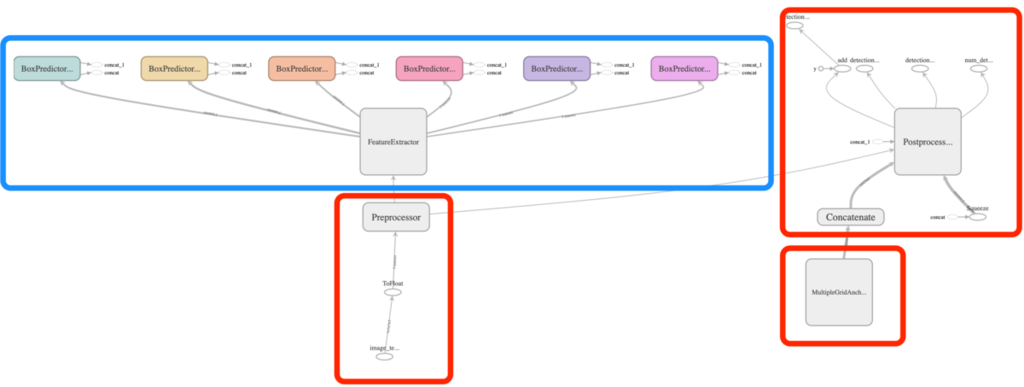
以上の部分を切り出せば、循環のないグラフにできそうです。
サブグラフを切り出す
coremltoolsを使ってサブグラフを切り出します。
from tensorflow.python.tools import strip_unused_lib in_names = ['Preprocessor/sub'] # 入力ノード名の配列 out_names = ['Squeeze', 'concat_1'] # 出力ノード名の配列 gdef = strip_unused_lib.strip_unused( input_graph_def = original_gdef, input_node_names = in_names, output_node_names = out_names, placeholder_type_enum = dtypes.float32.as_datatype_enum)
切り出し後のグラフはこのようになり、
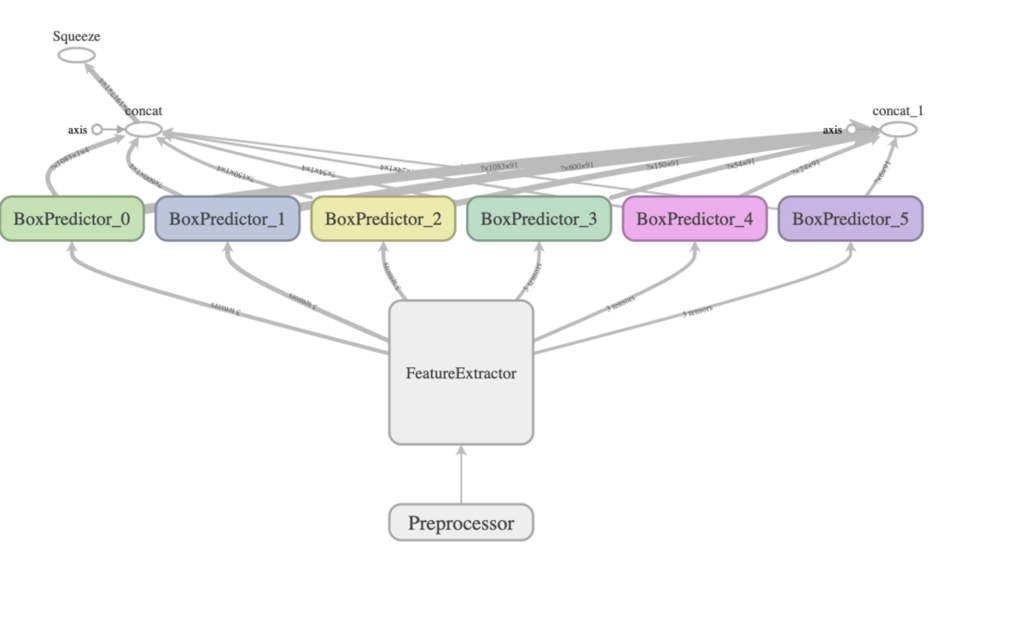
coremltools / tfcoremlのconvert関数も成功するようになりました。
切除したサブグラフを補填していく
元のモデルから切除した部分を別の手段で補填していきます。
まず、Preprocessor 部分の補填ですが、次のように coremltools (tf-coreml) の convert 関数のオプションで代替できます。
mlmodel = tfcoreml.convert(
tf_model_path = tf_model_path,
mlmodel_path = ml_model_path,
input_name_shape_dict = in_shapes,
output_feature_names = out_names,
image_input_names = image_in_names,
red_bias = -1.0,
green_bias = -1.0,
blue_bias = -1.0,
image_scale = 2./255)
次に MultiGridAnchorGenerator 部分を補填します。
名刺検出のモデルはSSD(Single Shot MultiBox Detector)という有名なアーキテクチャを利用しているのですが、このSSDの MultiGridAnchorGenerator 部分は、入力画像が何であれ、出力されるアンカーボックスは同じなので、静的な値で代替可能です。
そこで、オリジナルモデルを使用して事前にアンカーボックスの座標群を出力し、そのデータをSwiftで読み込むように実装することでこの部分を代替しました。
最後に、Postprocessor 部分の補填ですが、ここは同様の処理をSwiftで実装しました。6
まとめ: Core MLモデル変換の基本的な考え方
今回はスマキャプの名刺検出モデル(種類としては物体検出、アーキテクチャはSSD)を具体例として挙げましたが、どういうモデルであれ、変換エラーと対峙する際の「考え方」は共通しています。
エラーを起こしている部分を「どうにかする」という考え方です。
どうにかする手段としては以下があります。
- coremltoolsで切除する
- 切除した部分の補填
- coremltoolsの変換オプションで指定
- iOS側で同等の機能を実装
- 切除した部分の補填
- coremltoolsで置き換える
- カスタムレイヤーの作成も可能
- PyTorch / TensorFlowコード内で置き換える / 削除する
- 同等のOpで置き換える
- iOS用途では必要ない処理であれば削除する
筆者の経験上、最新のcoremltoolsバージョンを利用しても、残念ながらすんなり変換できるケースはほとんどなく、多くの場合はエラーに遭遇します。 大事なのは、エラーが出ても諦めず、上記のようにそのエラーを「どうにかする」手段を持っておくことかと思います。
- 3年前の端末、iPhone 11 Proで計測。↩
-
スマキャプのCore ML化以前のバージョンはこの方式を採用していました。TensorFlowから出力した
.pbモデルをそのまま組み込む方式です。↩ - 参考: https://github.com/hollance/neural-engine/blob/master/README.md↩
- 参考ページ: https://github.com/hollance/neural-engine/blob/master/docs/supported-devices.md↩
-
"Graph is not a DAG!"など。↩ - アーキテクチャはSSDなので、Non-Maximum Suppression (NMS) といったアルゴリズムをSwiftで実装しました。↩