はじめに
こんにちは!名古屋支店でEight事業部プロダクト部に所属する齊藤です。
Sansanに中途入社して2年目を迎えました。
普段はMeetsというサービスの開発・運用に携わっています。
今回人生で初めてビックデータを使った本格的なETL処理を実装することになり、AWS Glueを触りました。
最初はどうチューニングしていいか分からず、思うような処理速度が得られない状態から、最終的には期待以上に早く作業を終わらせることができたので、その中から得られた知見として、チューニングポイントを4つ共有したいと思います。
Glueを使いはじめた人向けの記事になると思います。EMRとの比較は、今後業務で触ることがあれば書きたいと思います。
参考までに
AWS Glueって費用はどれくらい?
AWSサービスを使う時にまず気になるのは料金だと思います。
Glueでよく使うのはメインのETL処理を書くことになるGlueジョブになると思いますが、こちらが実行時間に応じた料金体系で、10分で終わる処理なら大体20〜50円程度になります。
正確には1DPUあたり$0.44/hの料金となっていて、4DPUで実行時間が10分ならば、料金は1実行あたり4 * 10/60 * 0.44 ≒ $0.3となります。
DPUというのはジョブを実行するための処理単位で大きければより高性能になると思ってください。
DPUの値は扱うデータ量等によって変わりますが、今回のケースでは大体2〜5あれば足りました。
より厳密には秒あたりの課金となっていて、Glue ver2の場合は1分未満は1分として、ver1以下の場合は10分未満は10分として計算されるので注意が必要です。
またGlueジョブではspark以外にもpython shellを使うことができ、こちらは0.0625DPUとして実行されます。
どんな処理を作成したの?
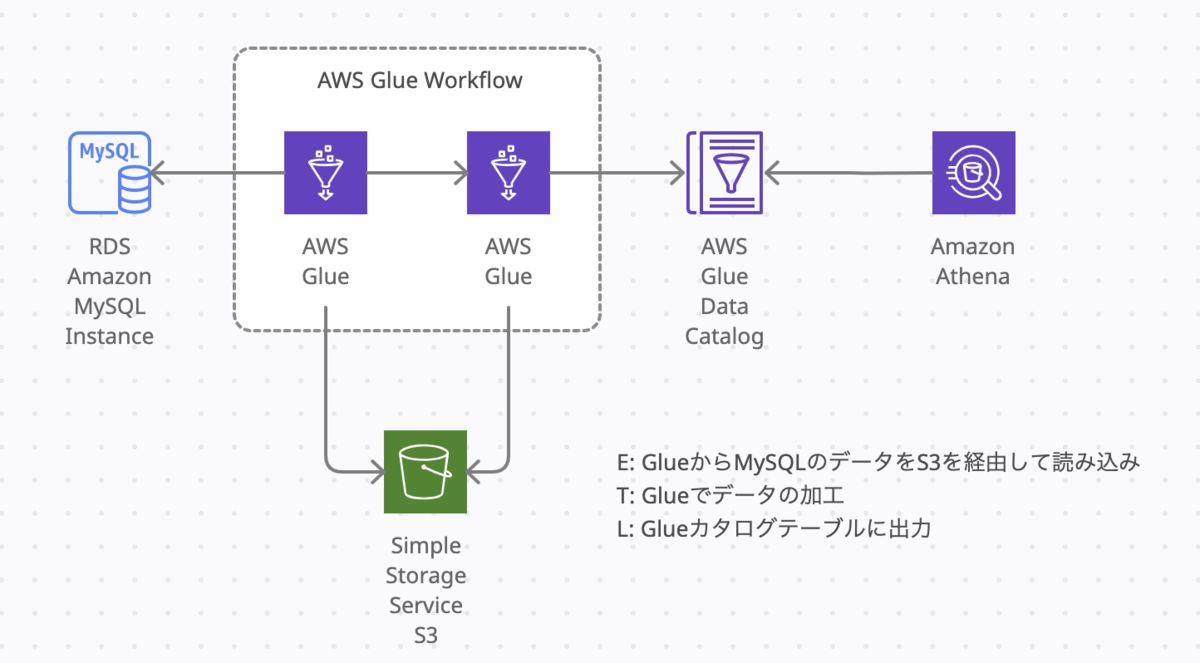
とあるシステムのデータベースからデータを抽出し、求めるデータとなるように加工して、利用するシステム側に持ってくる、というETLを絵にかいたような処理です。
連携するテーブルは十数個に及び、1テーブルあたりのレコード件数は多いもので数億件を超えます。実行間隔は1日に1度実行すれば良いものでした。
最終的にどんな実装になったの?
まずpython shellのGlueジョブを使ってDBからデータレークにデータを抽出し、pysparkのGlueジョブからそれを読み込んでカタログテーブルを作成するようにしました。この2つのジョブをGlue Workflowを使ってつなげて完成です。
同一ジョブにしなかったのは、抽出の処理が2時間かかりsparkでは料金が高くなるのと、sparkを使わなくても出来る処理だったからです。
直接DBからsparkで使用できる形に抽出できればさらに処理速度はあげられましたが、ある理由でそれができなかったためにこの実装で着地しています。
本題:チューニングポイント
以下にGlueを使ったETL処理における4つのチューニングポイントを記載しました。
記事のボリュームが大きくなるので、executor、リパーティションの説明や並列実行等の具体的な内容は省略しています。
1. メトリクスを見よう
まずは大正義、メトリクスを見てのチューニングです。メトリクスはジョブのモニタリングオプションから出力設定をする事ができます。 出力されたグラフから注目するポイントとして以下をあげました。
Job Execution: Active Executors, Completed Stages & Maximum Needed Executorsのグラフで、Max Allocated Executorsの閾値よりグラフが上位に来るならば、DPUの数を増やす事で処理速度の改善が期待できる。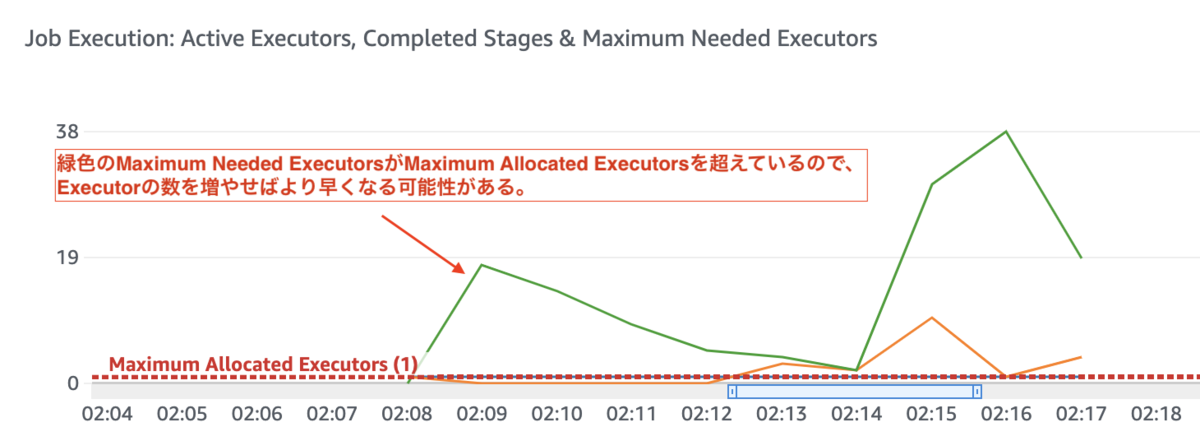
Data Shuffle Across Executorsでグラフが高い位置にあれば、DynamicFrameにデータを読み込む際に加工する条件やグルーピングする条件でリパーティションをすれば、executor間のデータの移動が減り、処理が早くなる可能性がある
CPU Load: Driver and Executorsでexecutorが複数稼働しているのにCPU使用率に偏りがある場合、並列実行が上手くできていない可能性がある。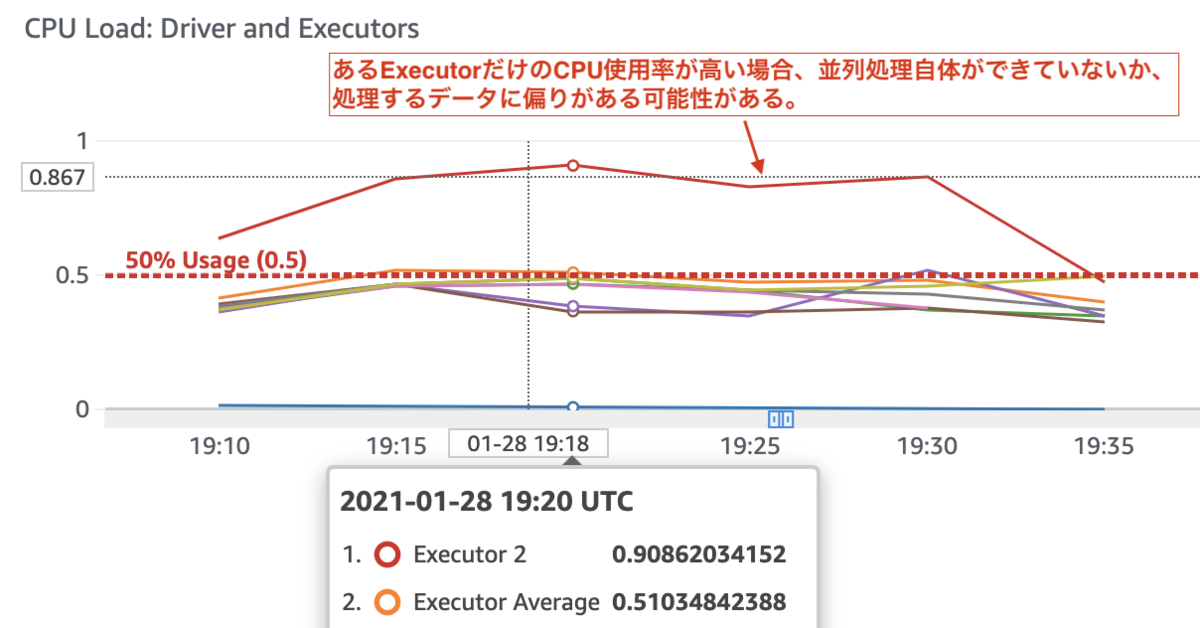
Memory Profile: Driver and Executorsでメモリ使用率が高ければ、worker typeをG.1Xにすれば改善される可能性がある。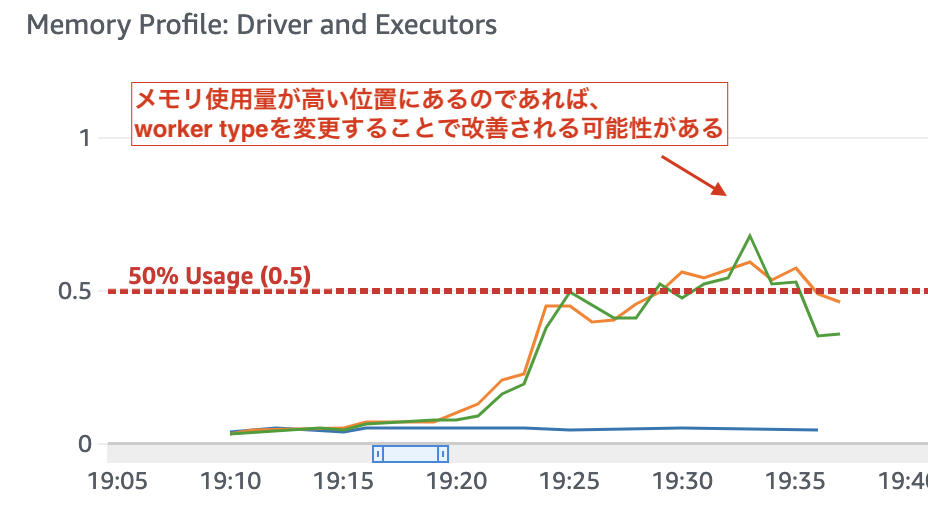
2. DBからデータを抽出する際は並列読み込みを行おう
sparkからODBCを経由してDBからデータを抽出する事ができます。
ここで抽出するデータ量が多い場合、単純にselectすると1つのexecutorにデータを読み込んでしまい、すぐにメモリが圧迫します。
その場合は並列読み込みを行えば、各executorのメモリに読み込まれ速度が格段に早くなるので使いましょう。
分割の仕方はDynamicFrameであれば、id mod 9のように余りが同じもので分割し、DateFrameであれば最小のidと最大のid、そして分割数を指定する事で並列読み込みを行う事ができます。
今回の場合、対象のテーブルが上記条件にうまく適合できなかったため、並列読み込みは断念しています。
3. カタログテーブルのパーティション数を増えすぎないように調整しよう
Glueのカタログテーブルはパーティションを指定する事でテーブルのインデックスのように作用し、レコードの検索が早くなります。
ただし、レコードの件数が100,000件あったとして、idを元に100,000件のパーティションを作ると、sparkからのデータ出力にものすごく時間がかかってしまいます。
体感的にはパーティション数を増やすと指数関数的に出力時間がかかるようになりました。パーティション数のリミットはテーブル単位で10,000,000で上限緩和も可能ですが、今回のケースでは1,000程度が最もパフォーマンスが良い結果となりました。
4. Athenaからカタログテーブルを読み出す必要がある場合はファイルサイズは128MB〜256MB以内に抑えよう
パーティション数を減らしても1パーティション当たりのファイルサイズが大きすぎると、今度はsparkからのデータ出力は速くなってもレコードの検索に時間がかかってしまいます。
パーティション内のデータを全部見てしまうので当たり前ですが、両者をバランスのいいところで調整しましょう。ファイルサイズは128MB〜256MBとなるのが最適なようです。
どうしてもどちらかに偏ってしまう場合は、テーブルを分けるなどの対応をした方が総合的に速くなるかもしれません。
おわりに
Glueはフルマネージドであるので、手軽にETL処理を始めるにはとてもいいサービスだと思いました。 またGlueが提供するDynamicFrameのライブラリを使えば、ETL処理も簡単に実装する事ができます。 この記事を読んで、Glueジョブのパフォーマンス改善の参考になれば幸いです。
最後にETL処理の経験がほぼ無い中、数多くのフォローをいただく事で実装まで辿り着く事ができました。この場を借りてご協力いただいた方に改めて感謝です。
参考文献
- https://docs.aws.amazon.com/ja_jp/glue/latest/dg/what-is-glue.html
- https://aws.amazon.com/jp/blogs/big-data/optimize-memory-management-in-aws-glue/
- https://qiita.com/pioho07/items/32f76a16cbf49f9f712f
- https://future-architect.github.io/articles/20181205/
- https://dev.classmethod.jp/articles/reinvent2018-ant326/