はじめに
本記事は、Sansan Advent Calendar 2023の6日目の記事です。
こんにちは、研究開発部の齋藤です。
固有表現認識にCRFを試す場面が最近あり、CRFのパラメータ学習を少し勉強しました。折角なのでまとめておこうかと思います。
書籍『形態素解析の理論と実装(工藤拓 著)』を非常に参考にさせて頂きました。
CRF とは?
CRFはConditional Random Fieldsの略語であり、日本語では条件付き確率場と呼ばれます。系列ラベリングに対数線形モデルを適用したものであり、品詞のタグ付けや、固有表現認識においてよく用いられます。
CRFは入力に対し、解析結果
が出力される条件付き確率
を以下のような式で計算します。
ここで、は入力を、
は全ての解候補を表します。また、
は素性(そせい)ベクトルであり、
は重みベクトルを意味します。素性ベクトルとは、分類や予測をするための手がかりです。
はスコアと考えることができます。後ほど具体例を用いて説明するため、今は「何かしらのスコアが入る」ぐらいで理解をしてください。最後に、
は
を表し、すべての解析結果の確率の和を1にするための正規化項です。
CRFにおいて、以下の計算で、を最大化する
を求めます。
CRFの目的関数は以下となります。
が目的関数に入ることにより、CRFがexp(指数分布)で表現されている点が考慮されています。
CRFを例えばSGDのような最適化手法で最適化する場合、勾配の計算が必要になります。を
で微分すると以下のような式になります。導出過程は省略します。
上記の第二項は、全ての解の候補についての計算していますが、解の候補
は入力
の長さが長くなると、指数的にその候補数が増えていきます。そこで、動的計画法を用いて解の候補を効率的に計算しています。詳細は割愛します。
以上より、理解したことをまとめます。
- CRFは入力
に対し、解析結果
が出力される条件付き確率
を計算していること。
- CRFのパラメータ学習における目的関数は、
であり、exp(指数分布)で表現されること。
- 勾配の計算の際に、解の候補
スコアについての具体例
スコアを具体的な例で考えてみましょう。
はスコアであり、
は重みベクトルを、
は素性ベクトルを意味していると説明しました。「Sansan株式会社はEightを運営する」というテキストを分かち書きし、B-組織名, I-組織名, O(その他)のタグのどれかに分類する固有表現認識のタスクを考えてみましょう。今回は、「その言葉がアルファベットのみで構成されているか」という素性ベクトルを適用してみます。その際、スコアがどのように計算されるかを以下の図に示します。
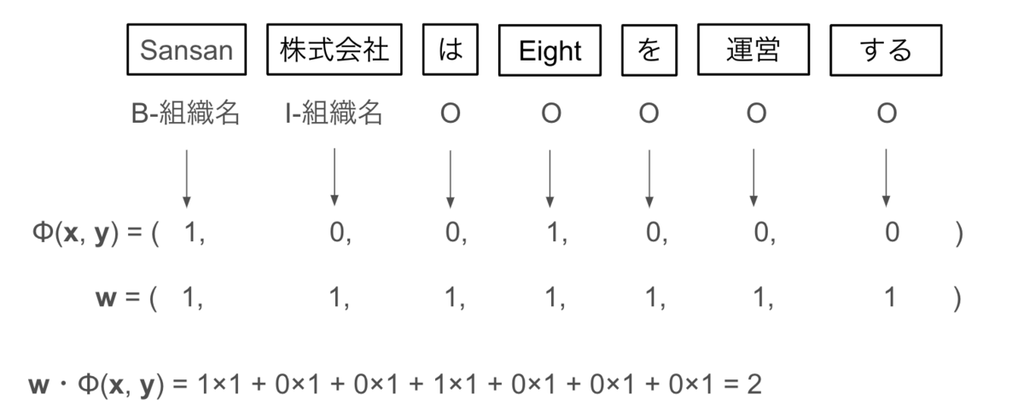
素性ベクトルは「その言葉がアルファベットのみで構成されている」場合には1を、そうではない場合は0を入れています。重みベクトル
は学習の中で変化します。今回は例としてすべて1を与えています。
スコアは、素性ベクトルと重みベクトル
の内積で表現されます。内積によって計算されたスコアを利用し、上述した数式によりCRFの計算が行われます。
最後に
CRFの計算やその仕組みを簡単に紹介しました。より詳しい理解をしたい方は、ぜひ「参照」に載せた書籍を読んでみてください。
参照
工藤拓、形態素解析の理論と実装、近代科学社、2018年