こんにちはニューラルネット老人こと糟谷勇児です。
このようなブログをやっていてなんですが、私自身はほとんどディープラーニングを実務で使っていません。
ディープラーニングがはまるということは、学習データが豊富で、説明力はある程度弱くてもよく、GPUマシンを使っても元が取れるぐらいの価値がある案件です。このような場合、ディープラーニングを使おうが使うまいがある程度成功する案件ということになります。こういう案件なら若手に任せて、老人はみんながさじを投げた案件を頑張るのも役割分担かもしれませんね。
とはいえ基礎知識は重要ということで今回もGPGPUをしていきましょう。
今回はコンボリューショナルネットに必要不可欠な画像のフィルタをCUDAで行う方法について学んでいきます。
行列計算と同じ手は使えない。テクスチャメモリの使用
さて、前回はCUDAで行列の掛け算をやりました。
buildersbox.corp-sansan.com
行列の掛け算では部分行列を高速な共有メモリにスレッドみんなで積み、部分ごとに計算していくという手法を取りました。
同じ方法が今回も使えるのでしょうか。しかし、ある画像部分をフィルタするにはその外周のピクセルを余分に持ってこなければいけません。行列の掛け算ではスレッドが自分の割り当ての場所だけをメモリに積めばよいですが、今回は外周の部分を誰が積むんだ?という問題が出てきます。人間が協調して動いている場合は近場の人が空気を読んで積めばいいんですが、コンピューターの並列化はなかなかそういうわけにもいきません。事前に外周のどの位置を積むかif文で書かなければいけないですし、それを積んでいる間は次の計算に移れないので、外周を積まないスレッドも待ちになってしまいます。
そこで、サンプルのプログラムではテクスチャメモリというものを使っています。
テクスチャメモリを使うことで、キャッシュが効いて高速に取り出せ、取り出す形式も選ぶことができて便利です。
物理的にテクスチャメモリというものがあるわけではなく、キャッシュが効くようにうまくメモリを使う機構のようです。
取り出す速さは、
ブロック間共有メモリ > テクスチャメモリ > 通常のメモリ
という感じになりそうです。
テクスチャメモリ
テクスチャメモリは1次元の画像、もしくは4次元までの画像を保持することができ、座標とチャンネル(RGBなど)を指定するとfloatなどの形式で取り出せます。
テクスチャメモリを使用するとキャッシュが効きやすく通常のメモリより高速と書きましたが、遅くなったというブログもありました。
akasuku.blog.jp
https://zukaaax.com/archives/443zukaaax.com
とはいえ、unsigned charからfloatに変換してから計算をする手間が省けて便利ですね。
入出力の形式(ノーマライズなど)はパラメーターでいろいろ制御できるようです。
もともとは3DCGをリアルタイムレンダリングするために、テクスチャを格納、描画するための機能のようです。
ボックスフィルタとは
周囲n×nの領域の単純平均を取るようなフィルタをボックスフィルタと言います。
3×3の場合はこんな感じですね。
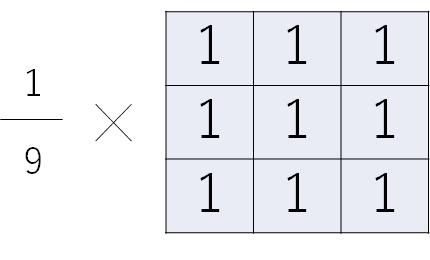
単純に足すだけなので、x方向に足して、それをさらにy方向に足します。
単純に足すと、フィルタの大きさ分の計算量が必要なので、一個ずらすときに左から一個減らして、右の画素を一個足していくというような処理にすることで、フィルタの大きさによらずx方向、y方向それぞれ2回だけの計算で足ります。
ボックスフィルタのサンプル
さて、CUDAのボックスフィルタのサンプルを見てみると、
- 画像をテクスチャメモリに積む
- x方向にフィルタを掛ける
- y方向にフィルタを掛ける
- できた画像を通常メモリにコピーする
という流れになっています。
今回も余分なものをそぎ落として、必要なコードだけのサンプルを自分のプロジェクトで動かしてみましょう。
ソースコードはこちらです。
#include <assert.h> #include <stdio.h> #include <math.h> #include <stdlib.h> #include <string.h> #include "device_launch_parameters.h" #include <cuda_runtime.h> #define checkCudaErrors(err) __checkCudaErrors (err, __FILE__, __LINE__) inline void __checkCudaErrors(cudaError err, const char* file, const int line) { if (cudaSuccess != err) { fprintf(stderr, "%s(%i) : CUDA Runtime API error %d: %s.\n", file, line, (int)err, cudaGetErrorString(err)); exit(EXIT_FAILURE); } } cudaTextureObject_t tex; cudaTextureObject_t texTempArray; cudaTextureObject_t rgbaTex; cudaTextureObject_t rgbaTexTempArray; cudaArray* d_array, * d_tempArray; int filter_radius = 11; int nthreads = 32; unsigned int width, height; unsigned int* h_img = NULL; unsigned int* d_img = NULL; unsigned int* d_temp = NULL; inline __host__ __device__ void operator+=(float4& a, float4 b) { a.x += b.x; a.y += b.y; a.z += b.z; a.w += b.w; } inline __host__ __device__ void operator-=(float4& a, float4 b) { a.x -= b.x; a.y -= b.y; a.z -= b.z; a.w -= b.w; } inline __host__ __device__ float4 operator*(float4 a, float b) { return make_float4(a.x * b, a.y * b, a.z * b, a.w * b); } inline __host__ __device__ float4 make_float4(float s) { return make_float4(s, s, s, s); } // convert floating point rgba color to 32-bit integer __device__ unsigned int rgbaFloatToInt(float4 rgba) { rgba.x = __saturatef(rgba.x); // clamp to [0.0, 1.0] rgba.y = __saturatef(rgba.y); rgba.z = __saturatef(rgba.z); rgba.w = __saturatef(rgba.w); return ((unsigned int)(rgba.w * 255.0f) << 24) | ((unsigned int)(rgba.z * 255.0f) << 16) | ((unsigned int)(rgba.y * 255.0f) << 8) | ((unsigned int)(rgba.x * 255.0f)); } __device__ float4 rgbaIntToFloat(unsigned int c) { float4 rgba; rgba.x = (c & 0xff) * 0.003921568627f; // /255.0f; rgba.y = ((c >> 8) & 0xff) * 0.003921568627f; // /255.0f; rgba.z = ((c >> 16) & 0xff) * 0.003921568627f; // /255.0f; rgba.w = ((c >> 24) & 0xff) * 0.003921568627f; // /255.0f; return rgba; } // row pass using texture lookups __global__ void d_boxfilter_rgba_x(unsigned int* od, int w, int h, int r, cudaTextureObject_t rgbaTex) { float scale = 1.0f / (float)((r << 1) + 1); unsigned int y = blockIdx.x * blockDim.x + threadIdx.x; // as long as address is always less than height, we do work if (y < h) { float4 t = make_float4(0.0f); for (int x = -r; x <= r; x++) { t += tex2D<float4>(rgbaTex, x, y); } od[y * w] = rgbaFloatToInt(t * scale); for (int x = 1; x < w; x++) { t += tex2D<float4>(rgbaTex, x + r, y); t -= tex2D<float4>(rgbaTex, x - r - 1, y); od[y * w + x] = rgbaFloatToInt(t * scale); } } } // column pass using coalesced global memory reads __global__ void d_boxfilter_rgba_y(unsigned int* id, unsigned int* od, int w, int h, int r) { unsigned int x = blockIdx.x * blockDim.x + threadIdx.x; id = &id[x]; od = &od[x]; float scale = 1.0f / (float)((r << 1) + 1); float4 t; // do left edge t = rgbaIntToFloat(id[0]) * r; for (int y = 0; y < (r + 1); y++) { t += rgbaIntToFloat(id[y * w]); } od[0] = rgbaFloatToInt(t * scale); for (int y = 1; y < (r + 1); y++) { t += rgbaIntToFloat(id[(y + r) * w]); t -= rgbaIntToFloat(id[0]); od[y * w] = rgbaFloatToInt(t * scale); } // main loop for (int y = (r + 1); y < (h - r); y++) { t += rgbaIntToFloat(id[(y + r) * w]); t -= rgbaIntToFloat(id[((y - r) * w) - w]); od[y * w] = rgbaFloatToInt(t * scale); } // do right edge for (int y = h - r; y < h; y++) { t += rgbaIntToFloat(id[(h - 1) * w]); t -= rgbaIntToFloat(id[((y - r) * w) - w]); od[y * w] = rgbaFloatToInt(t * scale); } } void initTexture(int width, int height, void* pImage) { // copy image data to array cudaChannelFormatDesc channelDesc; channelDesc = cudaCreateChannelDesc(8, 8, 8, 8, cudaChannelFormatKindUnsigned); checkCudaErrors(cudaMallocArray(&d_array, &channelDesc, width, height)); size_t bytesPerElem = (sizeof(uchar4)); checkCudaErrors(cudaMemcpy2DToArray(d_array, 0, 0, pImage, width * bytesPerElem, width * bytesPerElem, height, cudaMemcpyHostToDevice)); checkCudaErrors(cudaMallocArray(&d_tempArray, &channelDesc, width, height)); // set texture parameters cudaResourceDesc texRes; memset(&texRes, 0, sizeof(cudaResourceDesc)); texRes.resType = cudaResourceTypeArray; texRes.res.array.array = d_array; cudaTextureDesc texDescr; memset(&texDescr, 0, sizeof(cudaTextureDesc)); texDescr.normalizedCoords = false; texDescr.filterMode = cudaFilterModeLinear; texDescr.addressMode[0] = cudaAddressModeWrap; texDescr.addressMode[1] = cudaAddressModeWrap; texDescr.readMode = cudaReadModeNormalizedFloat; checkCudaErrors(cudaCreateTextureObject(&rgbaTex, &texRes, &texDescr, NULL)); memset(&texRes, 0, sizeof(cudaResourceDesc)); texRes.resType = cudaResourceTypeArray; texRes.res.array.array = d_tempArray; memset(&texDescr, 0, sizeof(cudaTextureDesc)); texDescr.normalizedCoords = false; texDescr.filterMode = cudaFilterModeLinear; texDescr.addressMode[0] = cudaAddressModeClamp; texDescr.addressMode[1] = cudaAddressModeClamp; texDescr.readMode = cudaReadModeNormalizedFloat; checkCudaErrors(cudaCreateTextureObject(&rgbaTexTempArray, &texRes, &texDescr, NULL)); memset(&texRes, 0, sizeof(cudaResourceDesc)); texRes.resType = cudaResourceTypeArray; texRes.res.array.array = d_array; memset(&texDescr, 0, sizeof(cudaTextureDesc)); texDescr.normalizedCoords = true; texDescr.filterMode = cudaFilterModePoint; texDescr.addressMode[0] = cudaAddressModeWrap; texDescr.addressMode[1] = cudaAddressModeWrap; texDescr.readMode = cudaReadModeElementType; checkCudaErrors(cudaCreateTextureObject(&tex, &texRes, &texDescr, NULL)); memset(&texRes, 0, sizeof(cudaResourceDesc)); texRes.resType = cudaResourceTypeArray; texRes.res.array.array = d_tempArray; memset(&texDescr, 0, sizeof(cudaTextureDesc)); texDescr.normalizedCoords = true; texDescr.filterMode = cudaFilterModePoint; texDescr.addressMode[0] = cudaAddressModeWrap; texDescr.addressMode[1] = cudaAddressModeWrap; texDescr.readMode = cudaReadModeElementType; checkCudaErrors(cudaCreateTextureObject(&texTempArray, &texRes, &texDescr, NULL)); } void freeTextures() { checkCudaErrors(cudaDestroyTextureObject(tex)); checkCudaErrors(cudaDestroyTextureObject(texTempArray)); checkCudaErrors(cudaDestroyTextureObject(rgbaTex)); checkCudaErrors(cudaDestroyTextureObject(rgbaTexTempArray)); checkCudaErrors(cudaFreeArray(d_array)); checkCudaErrors(cudaFreeArray(d_tempArray)); } void boxFilterRGBA(unsigned int* d_src, unsigned int* d_temp, unsigned int* d_dest, int width, int height, int radius, int nthreads){ d_boxfilter_rgba_x<<<height / nthreads, nthreads, 0 >>> (d_temp, width, height, radius, rgbaTex); d_boxfilter_rgba_y<<<width / nthreads, nthreads, 0 >>> (d_temp, d_dest, width, height, radius); } void initCuda() { checkCudaErrors(cudaMalloc((void**)&d_img, (width * height * sizeof(unsigned int)))); checkCudaErrors(cudaMalloc((void**)&d_temp, (width * height * sizeof(unsigned int)))); initTexture(width, height, h_img); } void cleanup() { if (h_img) { free(h_img); h_img = NULL; } if (d_img) { cudaFree(d_img); d_img = NULL; } if (d_temp) { cudaFree(d_temp); d_temp = NULL; } freeTextures(); } int runSingleTest(char* ref_file, char* exec_path) { int nTotalErrors = 0; char dump_file[256]; float msecs = 0.0f; cudaEvent_t start, stop; cudaStream_t stream; cudaEventCreate(&start); cudaEventCreate(&stop); cudaStreamCreateWithFlags(&stream, cudaStreamNonBlocking); printf("[runSingleTest]: [%s]\n", sSDKsample); cudaEventRecord(start, stream);//time from cudaMemcpyAsync initCuda(); cudaEventRecord(stop, stream); cudaEventSynchronize(stop); cudaEventElapsedTime(&msecs, start, stop); printf("init %f", msecs); unsigned int* d_result; unsigned int* h_result = (unsigned int*)malloc(width * height * sizeof(unsigned int)); checkCudaErrors(cudaMalloc((void**)&d_result, width * height * sizeof(unsigned int))); cudaEventRecord(start, stream);//time from cudaMemcpyAsync boxFilterRGBA(d_img, d_temp, d_result, width, height, filter_radius, nthreads); checkCudaErrors(cudaDeviceSynchronize()); cudaEventRecord(stop, stream); cudaEventSynchronize(stop); cudaEventElapsedTime(&msecs, start, stop); printf("calc with %f", msecs); cudaEventRecord(start, stream); // readback the results to system memory cudaMemcpy((unsigned char*)h_result, (unsigned char*)d_result, width * height * sizeof(unsigned int), cudaMemcpyDeviceToHost); cudaEventRecord(stop, stream); cudaEventSynchronize(stop); cudaEventElapsedTime(&msecs, start, stop); printf("copy with %f", msecs); free(h_result); checkCudaErrors(cudaFree(d_result)); return nTotalErrors; } int main(int argc, char** argv) { int devID = 0; char* ref_file = NULL; width = 2560; height = 1440; h_img = (unsigned int*) (malloc(width * height*sizeof(unsigned int))); runSingleTest(ref_file, argv[0]); }
プログラムのビルド
Visual Studioで普通にこのプログラムを動かそうとするとエラーが出てビルドが通りません。
VisualStudioの.projファイルで、テクスチャメモリ関係の関数を呼ぶソースファイルにCudaCompileを指定する必要があります。
これをしないと、__saturatefやtex2D
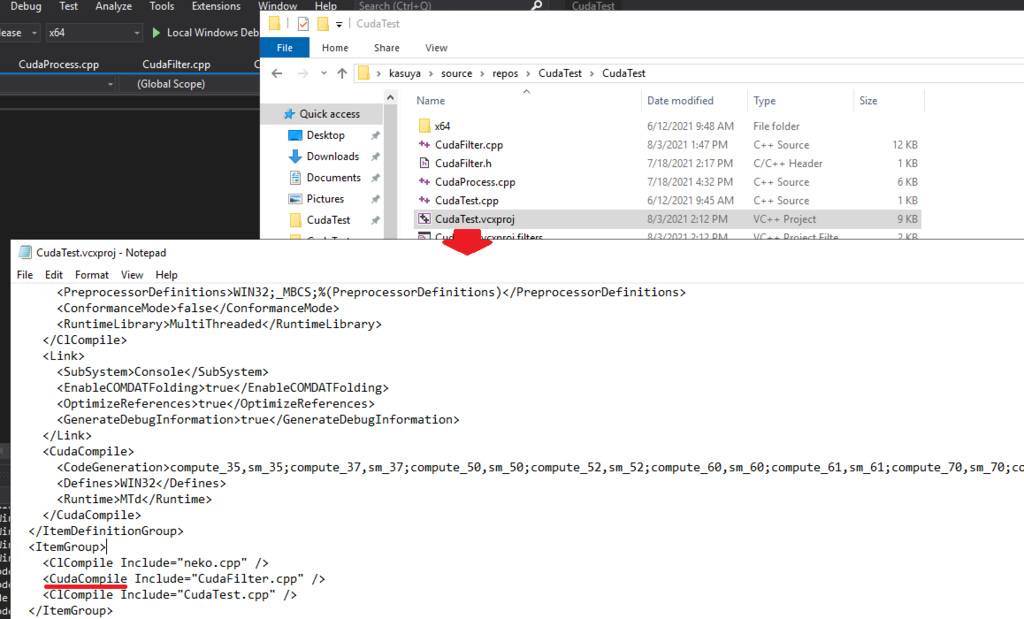
これでビルドできるようになります。
実験
では実際速いのか実験してみましょう。ライバルとしてはOpenCVを使ってみます。OpenCVのboxFilter関数を使用します。
opencv.jp
画像は2560*1440のRGB画像を使用します。結果はこちらです。

まずは合計で見てみるとOpenCV(1CPU)で18.5ms, CUDAで9.57msなので、2倍ぐらいは速いです。とはいえ2倍程度ならフィルタ処理をCPUで並列化したほうが速いでしょう。このようにGPGPUは画像一枚にフィルタを掛けて取り出すだけという用途にはあまり向きません。なぜならどうしても読み込みと計算結果の取り出しのオーバーヘッドが大きいからです。
では次にGPUの計算部分だけを見てみます。1.86msなのでやはり速いですね。テクスチャメモリの読み込みや結果のコピーなどトータルで見ると遅いですが、計算だけなら速いです。つまり、今回もどれぐらいGPUの中でデータを使いまわせるかという話になります。
幸い、コンボリューション層の計算は、nチャンネル画像をmチャンネルにするときはn×m回のフィルタ処理が必要でした。このような場合はテクスチャメモリに入れた画像はm回使いまわせることになるので、効率的に利用できます。仮にm=100のときは、テクスチャメモリは100回使いまわせるので準備時間は実質1/100と考えることができます。
まとめと今後
そんなわけで、今回はCUDAによる画像フィルタでした。画像1枚を処理するだけならCPUのほうが一般的には速いこと、コンボリューショナルネットで使うならうまく使えばかなり速くできそうなことがわかってきました。
大体のCUDAのイメージはついてきましたので、自作のディープラーニングでも活用できるかを検討していきたいと思います。