
こんにちは。研究開発部 Architectグループ データエンジニアの出相(デアイ)です。
本記事は Sansan Advent Calendar 2023 の23日目、および【R&D DevOps通信】の連載記事のひとつです。
データ分析基盤で分析をする際に必要となる分析用メタデータの管理・運用についての取り組みを連載にて紹介します。
2回目となる今回は、分析用メタデータをスプレッドシートでどう管理しているか実装面を中心に書いていきます。
なお初回の記事では、分析用メタデータについて・管理を実現するための方法検討・決定において取り組んだことを書きましたのでよろしければご覧ください。
buildersbox.corp-sansan.com
実現方法
前回の記事のおさらいになりますが、実現方法案を比較検討した結果、開発工数を抑えスピーディに最低限の価値提供が可能であるという点からスプレッドシートでのメタデータ管理を実施することに決めました。
アプリは既存のGoogle ComposerのDagに載せて稼働させます。

管理項目の最新状態を取得する
データセット毎に前回の記事に記載した管理項目を取得します。
内容を自動更新させたい項目についてはBigQueryのINFORMATION_SCHEMAから取得可能です。
項目と取得元INFORMATION_SCHEMAの対応表は下記になります。
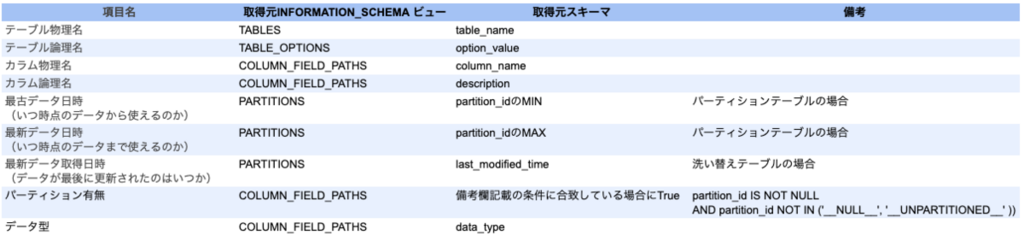
取得する際にパーティション周りで2点ポイントがあります。
- パーティションテーブルと洗い替えテーブルの違いは、PARTITIONSビューのスキーマで判断する
- pertition_typeがDAY以外の場合は、最古データ日時に最適な値を設定させる必要がある
パーティションテーブルと洗い替えテーブルはそれぞれ下記条件で取得しました。
-- パーティションテーブル
partition_id IS NOT NULL AND partition_id NOT IN ('__NULL__', '__UNPARTITIONED__' ))
-- 洗い替えテーブル
partition_id IS NULL pertition_typeがDAY以外のYEAR,MONTHの場合は年始,月初が最古データ日時となる様、partition_idを加工しました。
CASE
-- pertition_typeがYEARの場合は年始、MONTHの場合は月初が最古データ日時となるよう日付まで設定
WHEN regexp_contains(partition_id, '^[0-9]{{4}}$') THEN CONCAT(partition_id,'0101')
WHEN regexp_contains(partition_id, '^[0-9]{{6}}$') THEN CONCAT(partition_id,'01')
ELSE partition_id
END AS dateformatted_partition_id余談ですが、今から考えればDATA_TRUNC関数を使って月初や年初を出しても良かったかなと思いました。
しばらく経ってからコードを見ると気づくことがよくあります。
スプレッドシートを用意する
まず更新対象となるスプレッドシートを用意します。
スプレッドシートはデータセット毎に用意し、表題にはデータセット名を設定します。
また、シートはデータセット内のテーブル全てを一覧管理する「テーブル一覧」と全テーブルのカラム全てを一覧管理する「カラム一覧」の2シートに分けました。
テーブルの情報やデータの更新状態を知りたいときは「テーブル一覧」、カラムの情報が知りたいときは「カラム一覧」を見に行く運用となります。
下記は「テーブル一覧」シートのイメージです。

スプレッドシートに反映・更新するロジックは、既存のCloudComposer上のDagとして実装しました。
Dagにした理由としては、既存Composerを利用することで実装・運用・管理面の負荷を減らすことができるためです。
また、読み込むデータ量はBigQuery上にあるすべてのカラム数分程度のため、既存Composerのスペックでも十分に運用可能と判断できました。
スプレッドシートに反映・更新する
スプレッドシートへの反映・更新はPythonのライブラリであるgspreadを利用しました。
Dagからスプレッドシートを更新する際の認証は既存のサービスアカウントに権限追加して実現させました。
gspread自体はドキュメントやノウハウも充実しており大変使いやすいのですが、メタデータ管理として実装する際のポイントがあったのでいくつか紹介します。
Write requests per minute per user エラーで落ちる
データが少ない内は問題なく動いていたのですが、ある日突然下記エラーで中断するようになりました。
Quota exceeded for quota metric 'Write requests' and limit 'Write requests per minute per user' of service 'sheets.googleapis.com'
これはユーザ毎に1分間の書き込み上限として、デフォルト60回が設定されているためでした。
該当プロジェクトのGoogle APIのコンソールから現在設定されている上限を確認、そこから上限緩和申請を出すことで解決できました。
スプレッドシート上の利用者入力値は維持しつつシート内容を更新したい
前回の記事の要件として書いたように、UI(スプレッドシート)上の「自由記述」欄は利用者が自由に知見を書いておける仕様になっています。
テーブルについてはテーブル削除・カラム追加・カラム削除が日々行われ、その最新状態を反映したいです。
これを実現するために、シートのテーブル・カラム情報は毎回洗い替えつつ既存の「自由記述」欄を紐づける実装にしました。
ここでは「テーブル一覧」シートを例に説明します。
1. BigQueryのINFORMATION_SCHEMAからデータを取得し、query_resultに格納
前述の「管理項目の最新状態を取得する」項目で記載したINFORMATION_SCHEMAの情報を取得し、pandasのDataFrameに格納します。
2. スプレッドシートからシート情報を取得し、ss_dataに格納
「テーブル一覧」シートの全データを取得し、pandasのDataFrameに格納します。
3. query_resultとss_dataをキー項目により結合する
merge関数を使用し、キー項目で1,2 のデータを結合したDataFrameを作成します。
# BigQueryデータカタログ(keys_bq_column)とスプレッドシート(keys_sheet_column)のキー同士を結合 # スプレッドシートの項目は、キーとなるカラム名 + スプレッドシートのみに存在する項目(自由記述欄など) merged_df = pd.merge( query_result, ss_data[ keys_sheet_column + self.config[f"COLUMNS_ONLY_IN_TABLE_SHEET"] ], left_on=keys_bq_column, right_on=keys_sheet_column, how="left", ).fillna("")
4. 結合結果できた余計なカラムを削除
3直後ではquery_resultとss_dataで結合に利用した項目が重複して存在した状態になっているため、余分な項目を削除します。
# スプレッドシートに反映する項目の形式にするため、merge結果から結合キーで利用した列を除外 updated_sheet_value = ( merged_df.drop(keys_sheet_column, axis=1).to_records(index=False).tolist() )
5. データに「テーブル一覧」シートのヘッダ情報を付与する
4の最新データにヘッダ情報を付与することで、シートを洗い替え可能なデータ状態にします。
updated_sheet = [
self.config[f"HEADER_OF_TABLE_SHEET"]
] + updated_sheet_value
6. 「テーブル一覧」シートを洗い替える
worksheet.clear()
worksheet.update("A1", updated_sheet)
テーブルやカラムが削除された場合は、スプレッドシートから物理削除はせず背景色をグレーにする対応としました。
これは利用者が該当データに関するメタデータを利用していた場合、急に削除されてしまうと混乱させる恐れがあるためです。
課題
今回の対応で、ひとまずはメタデータの確認およびノウハウを記載できる場は用意できました。
これにより分析時に利用するデータの検索が可能になり、また開発側とのデータ連携時のやり取りやデータ分析基盤チームの運用でも利用できるようになりました。
ただ、いくつか課題も見えてきました。
検索性が悪い
データセット単位でシートが分かれているため、横断的に検索しづらい状態です。
全データセットを1シートにまとめたスプレッドシートも用意しましたが、膨大なデータが常に表示されている状態で使いづらさは否めません。
一方で既存のDataCatalog製品のUIは検索性など優れたものが多いのですが、非エンジニアである利用者が自由にノウハウを記載・即座に反映可能なサービスは現在見つけられていません。
データセットが増えるたびにスプレッドシートを作成する必要がある
データセット毎にスプレッドシートを用意する必要がありシート追加は自動化していないため、連携するデータセットが増えるたびに追加する必要があります。
追加を忘れるとそのデータセットのメタデータが確認できない状態となり、データセットによってメタデータがあったりなかったりする状態は利用者側の利便性が非常に悪いです。
技術負債になりそう
現在は単純な機能しか実装していないですが、それでもスプレッドシートの更新ロジックなどは理解しやすいものとは言えない状態です。
また、今後もしスプレッドシートの自動作成のような機能を追加すればするほど複雑化し、技術負債となる可能性が高まっていきます。
できる限り自前実装部分は簡単なものにして、ノウハウ共有不要にしていきたいです。
今後の展望
スプレッドシートでのメタデータ管理は導入を手軽に行うことができたものの、上記の通り使いづらさや保守面で課題が出てきたため改善していきたいです。
特にUI面の使いづらさは既製のデータカタログ管理ツールを利用し、検索性向上や情報充実化が図れるのではないかと考えています。
弊社では最近データ加工部分にdbtを導入し始めました。
dbtはドキュメント周りも充実しておりデータカタログやリネージも確認可能でGoogle DataCatalogよりも検索性や可視性が優れていると感じるため、メタデータのUIとしてうまく活用できないものかと考えています。

ちなみにdbtを導入し始めた話は次の記事をご覧ください。
buildersbox.corp-sansan.com
まとめ
今回は、分析用メタデータをスプレッドシートでどう管理しているか実装面を中心に紹介しました。
スプレッドシートという非エンジニアでも利用・更新しやすいツールを選んだことで、最新のメタデータを閲覧できる環境を運用できています。
ただ、スプレッドシートならではの課題も見えてきている状態です。
今後はより使いやすく運用しやすいメタデータ管理を模索したいと思いますので、次回以降もどうぞお楽しみに!
私たちのチームではデータエンジニアおよびアナリティクスエンジニアを募集しています。
データエンジニアリングからデータマネジメントまで一気通貫で体験できます。
ご興味のある方、DataCatalog周りの改善をガッツリやっていきたい方、下記ご覧いただけると嬉しいです!
研究開発部門 データエンジニア [全社横断データ分析基盤] / Sansan株式会社
研究開発部門 アナリティクスエンジニア[全社横断データ分析基盤] / Sansan株式会社