こんにちは。研究開発部のMengsay Loemです。
現在は、帳票などの文書画像から情報を抽出・構造化する「データ化技術」の研究開発に取り組んでいます。
本記事ではその中でも、視覚言語モデルを活用したアプローチに注目し、特に異なる情報抽出に特化したVLM(Vision-Language Model)を統合する方法に関する実験と考察を共有します。
※ ここで紹介する実験の内容は、実際の当社サービスで用いている技術とは異なります。
背景:帳票情報抽出へのVLM活用とその課題
帳票からの情報抽出には、近年VLMを VQA(Visual Question Answering)形式に適用する方法が注目されています。簡単に説明すると、VQAとは画像に対して質問を自然言語で与え、それに対する答えをモデルが自然言語で返すというタスクです。以下のようなイメージです。

帳票では、抽出したい情報が多様にあります。例えば:
- 金額系:支払額、小計、税額など
- 銀行系:振込先の口座名義、口座番号など
- 取引系:請求元、支払期日、支払方法など
それぞれの情報ごとに特化モデルを個別に作成するのは有効ですが、運用の観点では以下の懸念があります。
- 複数モデルを同時に管理するコストがかかる
- モデルのホスティング費用や推論リソースが増加する
そこで、すでに個別に高精度化されたVLM同士を統合することで、効率よく汎用的なモデルが作れるのではないかと考えました。
統合前後のイメージは以下の通りです。
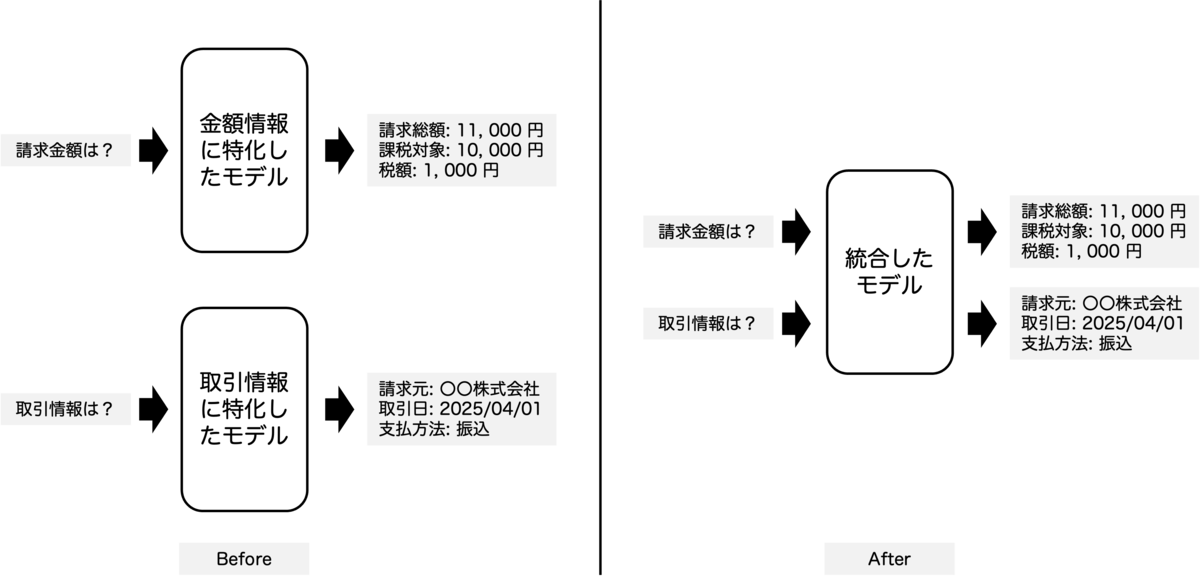
検証対象モデル:内製VLM「Viola」
本実験では、社内で開発中の内製VLM「Viola」を用いています。
簡単な概要は以下の通りです:
- アーキテクチャ: GITベース(Wang et al., 2022)
- 事前学習: 文書画像でOCRを含めて大量に学習済み
- タスク: 帳票などの文書画像から情報をVQA形式で抽出可能
詳細については、こちらをご参照ください。
speakerdeck.com
統合モデルの作成方法
モデルの統合手法としては、近年さまざまな手法が提案されています。例えば、
- 複数のFine-tuning済みモデルを単純または加重平均して統合し汎化性能を改善する Model Soup(Wortsman et al., 2022)や、フィッシャー情報量を用いてタスクの重要度に応じて加重平均を行う Fisher-Weighted Averaging (Matena and Raffel, 2022)
- モデルのパラメータ差分を足し引きすることで新たなタスクへの適応性能を獲得する Task Arithmetic(Ilharco et al., 2023)
- 個別データソースごとにFine-tuningしたモデルとベースモデルとの差分ベクトルを統合に用いることで、データ分布ごとの特徴を柔軟に取り入れる Distribution Edited Model(DEM)(Ram et al., 2024)
今回はこれらの手法の中でも、最もシンプルで直感的な単純な重みの平均に、軽量な追加の微調整を組み合わせる手法を用いて、その効果を手軽に検証しました。
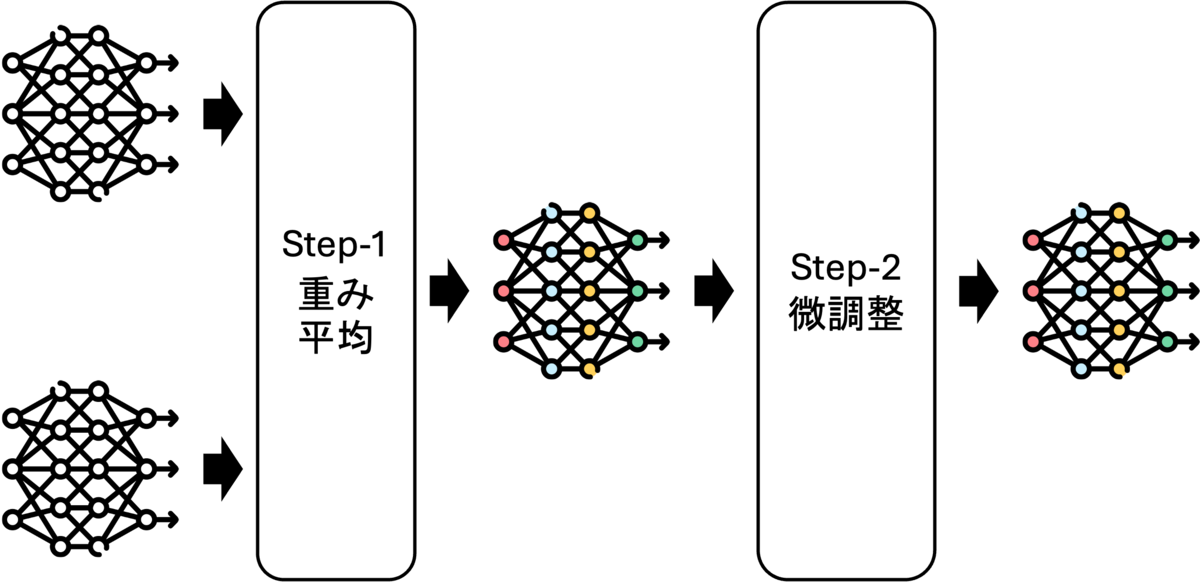
Step-1:パラメーターの平均
今回は以下の2つの特化モデルを統合します。
- ViolaPayment: 金額情報(支払額、小計、税額など)を抽出するタスクに特化したモデル
- ViolaTransaction: 取引情報(請求元、支払期日、支払方法)を抽出するタスクに特化したモデル
上記のモデルのパラメーターをレイヤーごとに平均して統合モデルを作ります。
Step-2:微調整(Fine-tuning)
マージ後、金額・取引の両項目を含む小規模な質問応答データセットを使って統合モデル(ViolaMerged)のFine-tuningを実施しました。
実験結果と考察
情報抽出の性能評価として、1000件の請求書画像を用いて、モデルの抽出結果と正解の完全マッチで評価を実施しました。各ステップで得られたモデルの正解率と出力結果の例は以下の通りです。ただし、本記事で示した実験結果の数値は、検証目的のために用意されたモデルおよび評価データセットに基づくものです。実際にサービスとして稼働しているシステムやモデルの性能とは関係ありません。
| 抽出対象 | 統合前 | Step-1後 | Step-2後 |
| 金額情報 | 94% | 0.2% | 88% |
| 取引情報 | 85% | 0.1% | 76% |
出力例
| 金額情報 | 取引情報 | |
| 統合前 | 請求金額: 21800円、課税対象額: 10000円 (10%)と10000円 (8%)、税額: 1000円 (10%)と800円 (8%) | 請求元: 株式会社〇〇、支払期限: 2024-12-31、支払方法:口座振込 |
| Step-1後 | 請求金額: 21800000、課税対象額: 10000円(10%) 1000000000 | 株式会社請求金額: 100000002024123111110000010000円 |
| Step-2後 | 請求金額: 21800円、課税対象額: 10000円 (10%)と10000円 (8%)、税額: 1000円(10%)と800円 (8%) | 請求元: 株式会社〇〇、支払期限: 2024-12-31、支払方法: 口座振込 |
Step-1の問題点
Step-1では、異なる情報種別に特化した二つのモデル(ViolaPaymentとViolaTransaction)の重みを単純平均しましたが、精度は大きく低下し、出力も著しく崩れました。特に以下の傾向がよくみられました。
- 取引情報に関する質問でも金額情報の出力形式に引っ張られ、誤った形式の応答を生成
- 数字や記号が異常に繰り返され、桁数の多い文字列が出力される
- 出力全体の構造や意味が崩壊
この現象は、異なる出力形式やトークンパターンを持つタスクを、意味の違いを考慮せずに単純に平均することで、タスクごとの出力特性が干渉し合った結果と考えられます。
Step-2の効果
Step-1の統合モデルに対して、金額情報と取引情報の両方を含む小規模なデータを用いて、追加学習を行った結果、出力の形式は大きく改善し、精度も部分的に回復しました。出力の構造が復元され、意味的にも読み取れるようになり、金額情報・取引情報ともに、統合前モデルに近い水準まで回復しました。ただし、いずれも完全には元の精度に戻らず、微細な性能劣化が残っています。
議論
Model Soup(Wortsman et al., 2022)では、同じタスクに対してFine-tuningされた複数のモデルを重み平均することで、汎化性能の改善が確認されています。これは、タスクの出力形式や表現パターンが類似していることにより、モデル間の干渉が少ないためと考えられます。
一方、今回の実験では、異なる情報(例:金額情報・取引情報)に特化したモデル同士を単純平均したことで、出力形式の競合が発生し、Step-1では出力の構造が崩壊する結果となりました。これは、Model Soupが前提とする「出力構造の類似性」や「タスク整合性」が、本実験の統合対象には当てはまらなかったことを示唆しています。
Task Arithmetic(Ilharco et al., 2023)は、事前学習済みモデルに対してタスクごとのfine-tuningによって得られるパラメーターの差分(タスクベクトル)を操作することで、モデルの振る舞いを制御する手法です。本実験で用いた単純なパラメータ平均は、構造的にはTask Arithmeticにおける「Learning via Addition」に相当し、ベースモデルからの差分の加重合成によって統合モデルを得るという点で一致します。ただし、Task Arithmeticでは差分ベクトル(タスクごとの変化)を明示的に扱うことで、各タスクの寄与を制御しやすく、干渉が起きにくいという特徴があります。一方、今回の実験では の前提でモデル自体を平均しているため、明示的なベクトル制御は行っておらず、出力の構造的な衝突や崩壊がそのまま統合後に現れやすいという課題がありました。
したがって、構造的にはTask Arithmeticの一形態とはいえ、その柔軟性や制御性を生かしきれていないという点で実用上の差異があります。
今後は、タスク間の出力表現や構造の違いを明示的に扱うような差分ベースの統合(Task ArithmeticやDEMに近いアプローチ)を導入することで、タスク干渉を抑えながらより安定した統合を目指せると考えています。
おわりに
本記事では、視覚的質問応答タスクで個別にファインチューニングされた複数の視覚言語モデルを統合し、帳票情報抽出に汎用的に対応するモデルを構築できるか試みました。現段階では単純な手法でも微調整によりある程度性能を維持できることが確認できました。今後、より洗練された手法を導入することでさらに精度を高め、実用的な統合モデルの実現を目指します。
参考文献
- Wang et al. (2022). GIT: A Generative Image-to-Text Transformer for Vision and Language. NeurIPS.
- Wortsman et al. (2022). Model Soup: Averaging Weights of Multiple Fine-Tuned Models Improves Accuracy Without Increasing Inference Time. ICML.
- Matena and Raffel (2022). Merging Models with Fisher-Weighted Averaging. NeurIPS.
- Ilharco et al. (2023). Editing Models with Task Arithmetic. ICLR.
- Ram et al. (2024). DEM: Distribution Edited Model for Training with Mixed Data Distributions. EMNLP.
Sansan技術本部ではカジュアル面談を実施しています

Sansan技術本部では中途・新卒採用向けにカジュアル面談を実施しています。Sansan技術本部での働き方、仕事の魅力について、現役エンジニアの視点からお話します。「実際に働く人の話を直接聞きたい」「どんな人が働いているのかを事前に知っておきたい」とお考えの方は、ぜひエントリーをご検討ください。