- 1. はじめに
- 2. LLM Week とは
- 3. AI導入効果の定量分析
- 4. LLM Week 振り返り共有会
- 5. LLM 縛り解除後の変化(7/14 週以降)
- 6. 今後のアクション
- 7. 終わりに
1. はじめに
こんにちは、Contract One Engineering Unitの高橋です。
先日、開発のほぼすべてをAIに委ねる1週間の実験「LLM Week」を実施しました。
本記事では、この実験から見えてきたAIドリブン開発の効果や課題について、データと共に得られた学びをご紹介します。
2. LLM Week とは
2.1 概要
2025年7月7日(月)〜7月11日(金)の期間で、実装・テスト・ドキュメントまで開発工程のほぼすべてを生成AIに委ねる1週間の実験をしました。この「AIドリブン開発」では、人間はプロンプト設計と最終確認に集中し、AIがコード生成・テスト実行・文書作成を担当するフルスケールの取り組みでした。
2.2 目的
この取り組みの主な目的は、AIスキル格差の解消、AI活用領域の拡大、ナレッジ共有による組織全体の底上げ、そして効果の見える化でした。すでに実務でAIを使いこなしている人とそうでない人との間のギャップを埋め、PBI出しやテストケース整備などの未開拓分野でのAI活用を促進し、分散していた知見を集約することを目指しました。
2.3 ルール
ルールとして、緊急時以外は1行の修正であってもすべてのコードをLLMで生成することを義務付けました。また、メンバーは1日5件を目安にAIドリブン開発での学びをSlackで共有し、Notion API+ClaudeやAIによるWeb検索など、入力作業も極力AIに委任しました。
3. AI導入効果の定量分析
3.1 リリースノート数で見るユーザ価値のデリバリ

2025年4月に開発プロセスへ本格的にAIツールを導入したことで、徐々にリリース数は増加傾向にありました。しかし、LLM Weekで開発を完全にLLMのみに限定した結果、リリース数が急激に減少しました。
3.2 主要開発メトリクス(コミット比率・コード量 / PR 件数 / レビューリードタイム)
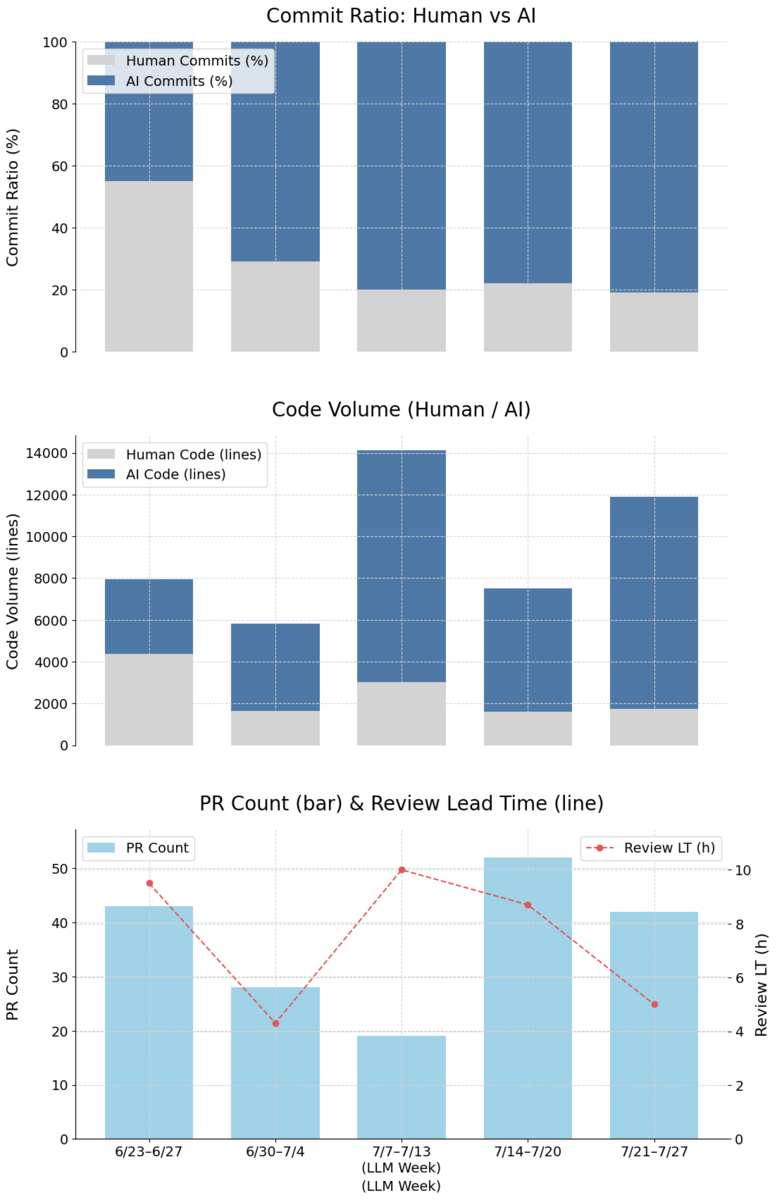
| 期間 | AI コミット比率 | コード量(AI / 人間) | PR 件数 | 平均レビューリードタイム* |
| 6/23–6/27 | 45 % | 3568 / 4376 | 43 | 9.5 h |
| 6/30–7/4 | 71 % | 4162 / 1653 | 28 | 4.3 h |
| LLM Week 7/7–7/13 | ≈80 % | 11094 / 3023 | 19 | 10 h |
| 7/14–7/20 | 78 % | 5925 / 1596 | 52 | 8.7 h |
| 7/21–7/27 | 81 % | 10139 / 1748 | 42 | 5 h |
AIツール導入が開発プロセスに与えた影響を測定するため、AIコミット比率、コード量、PR件数、PRレビューリードタイムの4つの指標を継続的に計測しました。これらのデータから、次のような重要な傾向が明らかになりました。
1. AI コーディングの急拡大
2週間で AI コミット比率が 45 → 71 % に急伸し、LLM Week には 80 % に到達。その後も 80 %前後を維持しています。
2. PR 件数とは対照的に平均レビューリードタイムの増加
PR 件数は LLM Week 中に 19 件と大幅に減少しましたが、その後 52 件に急増。特筆すべきは平均レビューリードタイムの変化で、LLM Week では 10 時間とスパイク状に増加しました。
3.3 分析と考察
LLM Week期間中は、PR件数が減少した一方でコード量が増加していることから、AIコーディングによって複数の大規模PRが生成されていたと考えられます。これがレビューリードタイムの延長を招き、結果的にリリース数の減少にもつながりました。この現象から、AI縛りによるデリバリ速度の低下という課題が明確になりました。
4. LLM Week 振り返り共有会
共有会では、LLM の強みと弱みが明らかになりました。
LLMの強み
- 迅速なコード生成—ボイラープレートコードや反復的な作業を即座に処理
- 定型作業(リネーム、テストテンプレート作成)の効率的な自動化
- PRの説明文やコミットメッセージの適切な作成
LLMの弱み
- コード品質のばらつきと保守性への懸念—意図せず冗長なコード(重複テストなど)や、人間がレビューしにくい複雑なコード(巨大な関数、深いネスト)を生成する傾向がある
- コードベース全体の一貫性を損なうリスク—チーム内で暗黙的に共有されているルールや「お作法」を反映できず、既存のコードとの一貫性を損なう可能性がある
- プロンプト(指示)の質への過度な依存—指示が曖昧だと、AIが善意で解釈を広げすぎ、結果的に意図から外れた「それらしい」コードを大量に生成してしまう
5. LLM 縛り解除後の変化(7/14 週以降)
LLM Week 終了後はAI強制ルールを撤廃し、
- 得意領域(雛形生成・単調修正・文書作成)は積極的にAIに任せる
- 苦手領域(設計意図の反映・可読性の確保)は人間が主導し、AIには具体的なプロンプトを与える
というハイブリッド運用にシフトしました。
さらに、LLM Week全体を通じて全メンバーのAI開発環境が整備されたことと、Slackでの知見共有が活発に行われたことでAIドリブン開発が組織全体に浸透しました。
この結果、平均レビューリードタイムはLLM Weekの10時間から翌週8.7時間、さらにその翌週には5時間へと半減しました。同時に、AIコミット比率は約80%を維持し、AIが生成するコード量も従来水準を保っています(LLM Weekの11,094行→7/14-7/20週の5,925行→7/21-7/27週の10,139行)。一方、リリース数は3件から6件へと微増したものの、LLM Week以前の水準には回復していません。つまり「AIの活用量を維持しながらも、レビュー効率の改善には一定の成果が見られた」と言えます。プロンプトテンプレートの整備とセルフレビューの徹底により改善は進んでいますが、AIコード生成の特性によるボトルネックがまだ存在する可能性があり、今後のプロセス分析でこれらを特定していく必要があります。
6. 今後のアクション
LLM Week とそれに続く継続的改善により得られた知見から、次のアクションを設定しました。
1. 実装リードタイムの可視化
カンバンの各ステータス(Ready、Doing、InReview、Done)のタイムスタンプを取得し、工程ごとの所要時間を詳細に計測します。これによりAIツール導入後のボトルネックを特定できます。
2. AI レビューの本格導入検証
GitHub Copilot ReviewとCode Rabbitを用いたコードレビューの品質を詳細に分析し、誤検出や見逃しのパターンを特定してインストラクションを最適化していきます。
3. プロンプトテンプレートの継続改善
「関数分割」「コメント最小化」「テスト追加」などの必須指示を継続的に改善していきます。
7. 終わりに
LLM Weekの実験から得られた知見と継続的な改善活動により、AIを活用した開発プロセスがContract One EUのエンジニアリング文化に確実に根付いています。データが示す通り、80%前後という非常に高いAIコミット比率が安定的に維持されていますが、リリース数の減少やレビューリードタイムの増加も観測されました。AIを効果的に活用するには、明確なプロンプト設計と効率的なレビュープロセスが不可欠であることが明らかになり、単純なAI活用率の向上だけでなく、その質と運用方法が生産性向上の鍵となることがわかりました。
今後は、AIと人間それぞれの強みを最大化するハイブリッド開発アプローチをさらに最適化し、実装からレビューまでの全工程においてリードタイムの短縮と品質向上の両立を目指します。プロンプトテンプレートの継続的改善やAIレビューの導入検証を通じて、さらなる生産性向上を追求していきます。
AIドリブン開発に興味をお持ちの方や、私たちと共に新しい技術の可能性を探求したい方は、ぜひカジュアル面談でお話ししましょう。
Sansan技術本部ではカジュアル面談を実施しています 
Sansan技術本部では中途の方向けにカジュアル面談を実施しています。Sansan技術本部での働き方、仕事の魅力について、現役エンジニアの視点からお話しします。「実際に働く人の話を直接聞きたい」「どんな人が働いているのかを事前に知っておきたい」とお考えの方は、ぜひエントリーをご検討ください。