
こんにちは。技術本部 Bill One Engineering Unit の前田です。前回のブログ から間が空いてしまいました。今回は、私の前回の記事とは趣向を変えて、Bill Oneでこれまで実施してきたSQLを変更することでのパフォーマンスチューニングについて触れてみます。 なお、本記事は【Bill One 開発 Unit ブログリレー】という連載記事のひとつです。
この記事の目的や前提
目的
Bill Oneは2020年5月のローンチ後、ありがたいことに多くのお客様にご利用いただいています。一方、ユーザ数やデータ量増加に伴って過去の負債や非効率な処理が発見されることがあり、それらにエンジニアは都度対応してきました。今回はその中で、SQLを改善することでパフォーマンスを改善させた事例紹介と、そのとき得た知見や教訓などを紹介します。この記事を書くにあたり過去のプルリクエストをざっと調査したところ、古いものだと2021年の5月にSQLパフォーマンス改善が実施され、新しいものだと2023年2月に実施されています。このようにBill Oneではパフォーマンスに継続的に向き合っており、私自身もパフォーマンス改善されるととても嬉しいと感じる人間なので、その一端に触れてほしいという個人的な気持ちもあります。
なお、パフォーマンスの低下はSQLのみで引き起こされるわけではないですが、当記事ではSQLの変更による改善を中心に扱います。また、SQLの実行プランの調べ方なども語りたいのですが、記事があまりにも長くなるため割愛します。その他の事例はいつか書ける機会があったら書きたいです。
環境や前提など
今回の記事は以下の前提で記載しています。環境によっては同じ結果とならない場合があることをご了承ください。
- SQLの実行パフォーマンスは格納されているレコード数、CPU、メモリ、ネットワーク構成、利用しているアプリが持つメモリ状況など、極めて多くの状況によって左右される
- 記事中に出てくるテーブル名やカラム名は全て架空のもの
- SQLはプロダクトからコードを一部抜粋して書き直したものであり、パフォーマンス劣化までは再現できていない(パフォーマンスまで再現したサンプルを作るのは困難でした)
- 一部、意図的にSQLをコメントアウトしている部分があり、そのままでは動作しない
| 環境 | 種類、バージョンなど |
|---|---|
| アプリケーションの種類 | Webアプリケーションのバックエンド |
| DB | PostgreSQL 13 |
| DBの実行環境 | Google Cloud SQL |
| プログラミング言語 | 主にKotlin *1 |
| KotlinからのDB接続ライブラリ | JDBI *2 |
| マイグレーション管理 | Flyway |
Bill OneではJDBIを採用しており、O/Rマッパーを使用していないため、エンジニアは自らの手でSQLを記述する必要があります。そのため、SQLに対する知見が多いと助かる場面があり、SQLの勉強会が盛んに実施されています。
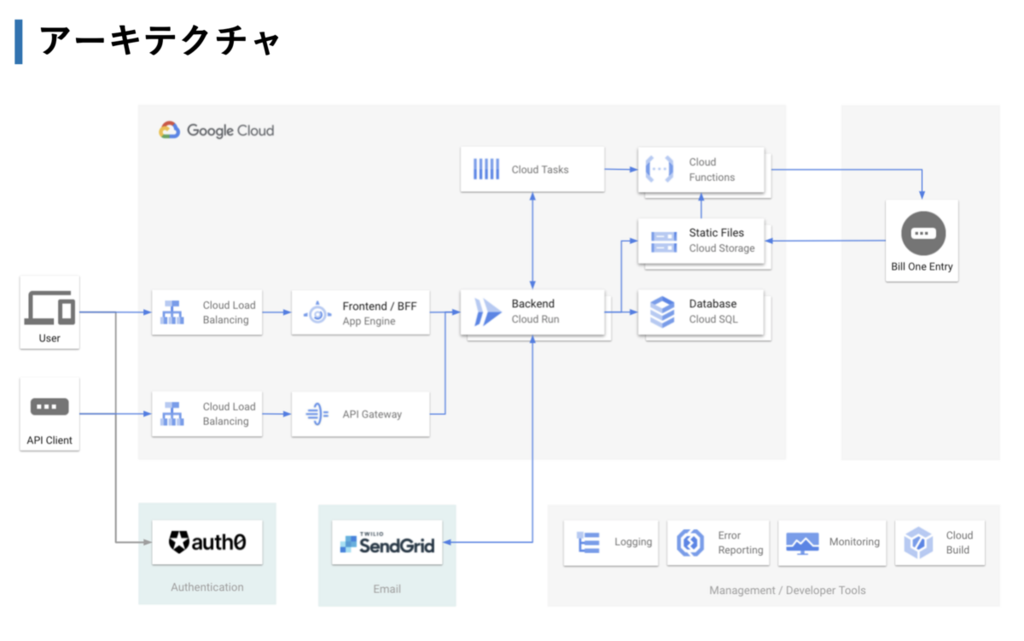
また、システム構成図は簡易的なものになりますが下記画像をご覧ください。 Bill One 開発エンジニアリング 紹介資料 にも掲載してあります。
事前のお断り
Bill Oneでは現状ヒント句を使用していないため、その話は出てきません。ご了承ください。弊社プロダクトであるSansanではヒント句を導入しており、導入経緯等は こちら に記事があります。
また、記事を書いている私は SQLパフォーマンス詳解 や SQLアンチパターン といった書籍を読めておらず、過去所属していた会社でのDWH(データウェアハウス)の保守やレポート生成等で規模の大きいデータを扱った時の経験則でパフォーマンスチューニングに取り組んでいます。そのため、経験則のみ記載するのではなく、記事中の説明ではできる限りPostgreSQL文書にリンクを貼っています。また、本来なら上記書籍を読んだ上で、Bill Oneの事例と関連づけて記事を書いてみたい!と思っていましたが、記事が大きくなりすぎることと、そこまでやると記事がいつまで経っても公開できない状況になるため、当記事はBill Oneの実例と私の経験ベースでの記事となりました。上記書籍を読んで、これまでの経験と紐づけて整理してみるような記事も、いつか書いてみたいです。
SQLでのパフォーマンスチューニング例
Bill Oneで実施されたSQLパフォーマンスチューニングの一部を紹介します。
インデックスを貼る
基本的な内容と思われるかもしれませんが、インデックスを貼ることは大事です。以下のようなカラムにはインデックスを貼ります。
- 外部キーとして指定され、結合に使われるカラム
- PostgreSQLでは、外部キー制約を付与しても参照する側の列には自動的にインデックスが付与されない。こちら の以下の記述の通り。
インデックスの方法には多くの選択肢がありますので、外部キー制約の宣言では参照列のインデックスが自動的に作られるということはありません。
- PostgreSQLでは、外部キー制約を付与しても参照する側の列には自動的にインデックスが付与されない。こちら の以下の記述の通り。
- 検索で使われるカラム
- ソートで使われるカラム
- こちら に詳細が記載されている。ただ、現状のBill Oneではここまで複雑な使い方はしていない
また、PostgreSQLのインデックスはカラムだけではなく式に対しても付与できます。例えば以下のようなことができます。この記述は、PostgreSQLの文書にある通りUNIQUEと組み合わせることで大文字小文字を無視して一意性を確保できるなど、有効活用できる場面があります。
create index user_email_index on product_user(lower(email));
Bill Oneでは、上記の用途だけでなくJSONデータ型で格納されたカラムへ頻繁に検索を実施するケースに対応するために、インデックスを用意する場面もありました。
create index email_category_index on mail_event ((json_value ->> 'email'), (json_value ->> 'category'));
このように設定したインデックスは、以下のような検索を実施する場面で有効に作用します。
select * from mail_event where json_value ->> 'email' = 'test@example.com' and json_value ->> 'category' = 'OPEN';
もっとも、インデックスはただ作ればいいというものではなく、適切に使われるようなSQLを書くことが求められます。
インデックスが使われるようにSQLを書き換える
インデックスが使われない一例
例えば、以下のようなテーブルを用意し、documentの情報とそのコメント数を同時に取得するとします。
テーブル定義
create table document ( id uuid primary key, name varchar(255) not null, created_at timestamptz not null ); create table document_comment ( id uuid primary key, document_id uuid not null references document (id) on delete cascade, content varchar(255) not null, created_at timestamptz not null ); create index on document_comment (document_id);
SELECT
select d.id, d.name, dc.comment_count from document d left join ( select dc.document_id, count(*) as comment_count from document_comment dc group by dc.document_id ) dc on d.id = dc.document_id limit 100;
これだけのSQLなら問題はないですが、複雑なSQLの一部に上記のような構文が含まれると以下のような問題が発生することがあります。
left join内の副問い合わせが、オプティマイザが作成する実行プランに大きく左右される- SQLを素直に読むと一回だけ表全体をSELECTして集約してくれそうだが、そうなるとは限らない
limit 100の効果でleft join内が100回実行される実行プランが生成されると遅くなるケースd.id = dc.document_idの部分でインデックスが使用されず、Seq Scanになるケース
- SQLを素直に読むと一回だけ表全体をSELECTして集約してくれそうだが、そうなるとは限らない
- そもそも
left join内のSELECTがテーブル全体を走査する内容であるため、無駄が多い(limitの100だけ取ってきてくれればいい)
そのため、document自体やdocument_commentのレコード数が増える等の要因でパフォーマンスが低下します。レコード数が少ないローカル環境や検証環境では問題なく動作し、リリース後しばらくはレコード数が少ないためやはり問題なく動作しますが、データ量が一定を超えたタイミングでいきなりパフォーマンスが低下します。特にプロダクトの立ち上げ直後など、データ量が少ない状況で気づくのは困難である点は厄介です。
Bill Oneの過去の変更を見ると、インデックスが使われないケースへの対処が複数の場面でなされていたので紹介します。
単にSELECT句に移動させる
PostgreSQLのSELECTのページ によると、SELECTのSQLは以下の順番で実行されます。
- WITH句(あれば)
- FROM句*3
- WHERE句(あれば)
- GROUP BY句(あれば)
- SELECT句
- その他構文
つまり、FROM句に書かれたSQLは、基本的に必ず実行されます。また、この順序で大事なことは前に実行された結果を後続で参照できる点です。すなわち、WHERE句で特定テーブルのカラムを参照したければ、そのテーブルをFROM句に加える必要があります。逆に言うなら、WHERE句で必要ない値はFROM句で取得する必要はないです。
そこで、最初のSQLを以下のように書き換えます。
select d.id, d.name, ( select count(*) as comment_count from document_comment dc where dc.document_id = d.id ) from document d limit 100;
この書き換えにより、dc.document_id = d.id のテーブル結合でインデックスが使用されるようになります。副問い合わせ文のSQLは最大100回実行されますが、インデックスが利用されるため圧倒的に効率的になり、かつ安定します。実際のプロダクトでは、この改善は巨大なSQLの一部を修正するものとして実施されています。その時の実際の実行プランは下記の通りで、大きな改善が見られました。(改善した実行プラン部分の数値のみ抜粋)
変更前(見づらいので改行を入れた)
-> Merge Left Join
(cost=39.95..250977.85 rows=10 width=828)
(actual time=12.526..4489.157 rows=100 loops=1)
変更後
-> Nested Loop Left Join
(cost=5.82..5880.08 rows=10 width=851)
(actual time=0.427..171.525 rows=100 loops=1)
SELECT句に移動 + WHERE句での絞り込みを個別に実施する
過去の変更を調べていたところ、同じ例が二つあったので紹介します。例えばこういうテーブルがあったとします。
-- 文書本体 create table document ( id uuid primary key, name varchar(255) not null ); -- 文書のフィールド定義。各文書で同一の定義となる create table document_field ( id uuid primary key, name varchar(255) not null ); -- 文書に紐づいているフィールドの値 create table document_field_value ( id uuid primary key, document_id uuid not null references document (id) on delete cascade, field_id uuid not null references document_field (id) on delete cascade, value varchar(255) not null ); create index on document_field_value (document_id); create index on document_field_value (field_id);
そして、document検索の仕様は文書と、その文書のフィールド値も一緒に見たい、文書のフィールド値の文字列で検索したいというものだったため、それを一回で取得できるように下記のようなSQLを記述しました。
-- 修正前イメージ select d.id, d.name, fields.json from document d left join ( select dfv.document_id, json_agg(json_build_object( 'field_id', df.id, 'value', dfv.value )) as json from document_field_value dfv inner join document_field df on dfv.field_id = df.id group by dfv.document_id ) fields on d.id = fields.document_id where -- ユーザが検索条件として指定したら出現する。長いので省略 exists(select * from json_array_elements(fields.json) -- ...以下略
このSQLも先ほどの事例と同じくleft join内で集計を実施しているため、fields on d.id = fields.document_id の部分でインデックスが使用されない場合があります。また、json_aggの関数がFROM句内でレコード数分だけ実行されることになり、それも速度が遅くなる要因となっていました。
先ほどの事例と異なり、今回はWHERE句での値検索が必要なのでFROM句で値を取得しておくのは必須に思えます。が、EXISTS句を適切に使えば回避できます。そのため、以下のように修正しました。
-- 修正後イメージ select d.id, d.name, ( select json_agg(json_build_object( 'field_id', df.id, 'value', dfv.value )) from document_field_value dfv inner join document_field df on dfv.field_id = df.id where dfv.document_id = d.id group by dfv.document_id ) as fields from document d where -- ユーザが検索条件として指定したら出現する。長いので省略 exists(select * from document_field_value dfv2 where d.id = dfv2.document_id and dfv2.field_id = :fieldId and -- ...以下略
修正内容をまとめると下記の通りです。
- FROM句で
json_aggを呼ぶと場合によっては想定以上の回数実行されて遅いので、そもそも呼ばない - 返却する値はSELECT句で個別に取得する。ここはインデックスが効くようなSQLにする
- WHERE句の検索で
document_field_valueテーブルを直接見るように変更する
この変更が可能だったのは、WHERE句に追加すべき検索条件はユーザが入力しない限り利用されず、デフォルトでは入力されることはない点が大きかったです。検索で使用される可能性が低い値を常にFROM句で取得するコストが高いため、大多数のユーザは恩恵が得られます。ただ、EXISTS句の使い方としては正しいもののFROM句で取得していない値で検索を行うという意味でSQLの可読性が下がるというデメリットも一定あるため、状況に応じて適切に使うのが良いと思います。
ついでに紹介すると、Bill Oneでは検索SQLを作るための処理をKotlinで用意しており、ユーザがそもそも検索パラメータを指定しなかった場合WHERE句への出力自体をやらない、ということが簡単にできます。
data class QueryCondition( val conditions: List<String> = emptyList(), val queryParameters: List<QueryParameter> = emptyList(), ) { /* 中略 */ fun addFromParameter(param: Any?, condition: String, placeholder: String): QueryCondition { // 補足: SQLの記述を間違えたらエラーにする require(condition.contains(placeholder)) return param?.let { add(condition, QueryParameter(placeholder, it)) } ?: this } /* 中略 */ }
最新1件を取得する目的のためにウィンドウ関数を使う
例えば、最初に記載したdocumentテーブルとdocument_commentテーブルを結合してdocumentを返す際、最新のコメント1件を一緒に返したいとします。以下のSQLだとdocument_commentの数だけ結果セットが返ってくるため、1件に絞りたいです。
-- サンプル select d.id, d.name, -- ここで最新のコメントだけ欲しい dc.content from document d left join document_comment dc on d.id = dc.document_id;
そのためには、最新の日付を取得してそれと同じ日付のレコードを取得すれば良いということで、以下のようなSQLを書いていました。
-- 修正前イメージ select d.id, d.name, dc2.content from ( select dc.document_id, max(dc.created_at) as created_at from document_comment dc group by dc.document_id ) latest inner join document_comment dc2 on dc2.created_at = latest.created_at inner join document d on dc2.document_id = d.id;
ある時、このSQLのパフォーマンスが悪いことが判明したものの、要件を変えるわけにはいかないため、手を出せずにいました。最新のコメントだけを保持する別のテーブルを作れば良さそうだけど、検索だけのために実装するには開発規模が大きく、機能実装の合間に実施できないという悩みを抱えていました。
色々と案を出し、最終的にはこの事象はウィンドウ関数 を使うことで解消しました。イメージは下記のようなものになります。
-- 修正後イメージ with latest as ( select -- 実際は複数値を返している dc2.document_id from ( select dc3.document_id, rank() over (partition by dc3.document_id order by dc3.created_at desc) as rank from document_comment dc3 -- 実際はパラメータを用いて事前に対象を絞っている ) dc2 where dc2.rank = 1 ) select d.id, d.name, dc.content from document d left join latest l on d.id = l.document_id left join document_comment dc on l.document_id = dc.document_id;
この対応でうまくいったのは、非インデックス列である created_at を結合に使う*4より、先にRANK関数等で先頭のみを抽出(rank = 1 は当然インデックスが使われない)してからインデックス列である document_id で絞った方がデータ量の観点からトータルで見て効率が良いという判断になったためです。というのも、このSQLによる遅延は特定のデータ量を超えた状態でのみ発生し、大多数のケースにおいて問題が起こらなかったためです。この対応後は安定したパフォーマンスになっていますが、これでも問題が起こるなら別テーブルに切り出す等の更なる改善が行われると思います。
なお、例で挙げた「最新のコメント」というものですが、実際の仕様は「入力補助のため、ユーザごとに最後に承認依頼を実施した際に選択した承認情報(次の承認と承認依頼した人、もしくは自身が最終承認者であるか)を、承認依頼の数(最大30)だけ返却してほしい。なお、承認は事後的に自身で取り消しできる、承認依頼を受けた人は承認を差し戻しできる、権限がある人は承認者でなくても承認を強制的に差し戻せる」となっています。そのため、「検索のためだけにユーザが最後に実施した承認依頼」を別テーブルで保持するという変更を入れるのを躊躇していた、ということを付け加えておきます。
全件出力はやらない
Bill Oneローンチ時、請求書一覧画面では検索条件と一致する請求書一覧データをバックエンドが全件返却し、ページネーションをフロントエンドで実装していました。フロントエンド実装の柔軟さには一定寄与したものの、当然のように以下のような問題が起きました。
- データ量が多いユーザだと、Bill Oneのページが開かれる速度が遅い
- 検索を実施しているWebサーバ(Cloud Run)が処理待ちと大量のメモリ消費を起こす*5
- DBに負荷がかかりBill One全体の応答が悪くなる
そのため、問題になったタイミングでバックエンドにページネーション処理を入れました。SQLとしては並び順を固定し、最後に LIMIT と OFFSET をつけるだけであり、プログラムで現在のページ数や1ページあたりの件数を決めれば良いです。
-- この前にSELECT等があると仮定 -- LIMITを使う場合は、順番が一意になるよう強制されるようにする order by xxx limit :perPageCount offset :pageNumber;
ただし、OFFSETは大きな値だと非効率であり、特に後半はパフォーマンスが悪いという問題があります(LIMITとOFFSET)。ただ、Bill Oneの請求書検索画面は様々な列でのソートが必要であり、DBでソートすることが現実的であるため、OFFSETのパフォーマンス悪化の可能性は許容しつつ、最大ページ数に条件を設けることでカバーしています。現時点では1ページあたり100件で100ページまで表示でき、それ以降を閲覧する場合は検索でさらに絞っていただくようにしています。
また、たとえばデータのエクスポート機能で大量のデータをエクスポートしようとした場合にもDB等に大きな負荷がかかるため、一回ごとにエクスポートできる件数に制限を加えるなどの制御が必要となることもあります。ユーザがプロダクトを介して処理できるデータ件数はプロダクトのパフォーマンスとユーザの利便性の間でトレードオフになるケースがあるため、エンジニアとしてはパフォーマンス影響を与えない道を模索しつつも、厳しい場合はプロダクトに制限を加える道を考えることも必要と考えています。
なお、PostgreSQLではSELECTの中の式はLIMITの後に評価するという仕様*6となっているため、LIMIT句によって返却行数を絞っておくのはパフォーマンスに良い影響が出やすいです。
マイグレーションに時間をかけない
SQL自体のチューニングとは話がずれますが、Bill Oneの取り組みの一環として紹介します。
DBを使用しているWebアプリケーションのリリースでは、リリース時にDBにカラムを追加する等のマイグレーションを実施する場合があります。マイグレーションにもさまざまな種類がありますが、種類によってはマイグレーションに時間がかかりすぎたり、テーブルのロックを獲得するのに時間がかかってしまいリリースが終了せず、最悪の場合DBに悪影響が出てしまうケースがありました。また、大きなマイグレーションを実施する際は一旦プロダクトを停止して作業するという手段がありますが、それはユーザにとってもエンジニアにとっても負担を強いることとなるため、できる限り無停止でマイグレーションできるようBill Oneでは心がけています。マイグレーション関連だけで別の記事が一本書けそうなほどのボリュームになりそうなので、簡単に事例を紹介します。
なおBill Oneでは、下記ページを参考にしてかなりマイグレーションが安定しました。この場を借りて御礼申し上げます。
ロックタイムアウト時間を決めておく
マイグレーション時、テーブル全体のロック獲得が必要となるケースがあります。ロックを獲得するには、更新処理等が全て完了する必要がありますが、あまりに長い時間待つと後続の処理がロック待ちでさらに待たされる、という状況になる可能性があります。そのため、Flywayのオプションで lock_timeout を設定し、定められた時間内にロックを獲得できない場合はタイムアウトで一旦マイグレーションを失敗させています。タイムアウトが発生した場合、エンジニアは何度かリリースを試行します。それでもタイムアウトする場合はリリース時間を休日や夜に実施するなどの対策となりますが、下記のように「そもそもロックを獲得しないでマイグレーションする」という方法を取る場合があります。
ロックを獲得しない工夫をする
PostgreSQLでは、CREATE INDEXのページにある通り、インデックスを追加する場合インデックス作成が完了するまで対象テーブルの書き込みは不可になります。そのため、マイグレーション実施時間が長くなるとユーザに影響が出ます。そこで、PostgreSQLのCREATE INDEXに用意されている CONCURRENTLY オプションを使って、必要な場合はロックを獲得せずにマイグレーションを実施*7しています。
チューニング作業について
遅いSQLをどうやって見つけるのか
本番環境で実行されているSQLの中から、実際に遅いSQLを探すのは結構大変です。エンジニア数が少なく環境整備に手が回らない時期は、Cloud MonitoringによるDBのCPU使用率アラート等を駆使して気付けるようにしたり、カスタマーサクセス部からのフィードバックに頼っていたりという状況でした。その場合の調査はCloud Logging に出力した情報を地道に追うという方法でやっていました。ただし、この方法だと、Bill Oneが最も利用される月初に負荷が集中し、そのタイミングで気づくという、完全に後手に回ってしまっている状況になっていました。また、調査がとても大変でした。
現在はQuery Insightsを使う*8ことが多いです。非効率なSQLを探すのに非常に便利です。非効率なSQLが目に見えて分かると、それを修正したい!という気持ちで動く人が増えたような気がします。私もその一人です。
チューニング作業で気をつけるポイント
実際にチューニングを実施する際は自身で EXPLAIN ANALYZE を利用して実行プランを取得してくることが多いです。これはQuery Insightsのみからチューニングに必要な十分な情報が得られない点と、EXPLAIN ANALYZE の場合は以下のような情報が得られる利点があります。
- ある程度、構文ごとに実行時間と利用されているアルゴリズムが閲覧できる
- 余分なSQLを削りながら、どのように実行プランが変わるかその場で確認できる
- Seq Scanのような、明らかに改善できそうな点がすぐ検索できる
EXPLAIN ANALYZE を利用してチューニングを実施する場合の注意点としては、できる限り本番環境に近い環境で実施することが挙げられます。テーブルのリレーション等が同一だとしても、格納されているレコード数によって全く異なる実行プランになることがあるため、判断を誤る可能性があります。
実行プランをどうやって読めば良いのかという別の論点もありますが、今回は割愛します。反響があれば書くかも…?
また、SQLのパフォーマンスチューニングの結果、結果が修正前と修正後で異なってしまうというケースが考えられます。Bill Oneでは必ずテストを書く文化があることと、バックエンドはControllerからDBまで一気通貫でテストを実施しているため、仮にSQLが誤っていて結果セットが変わった場合はテストに失敗します。SQLの修正に入る前に本当にテストが網羅されているか確認する必要はありますが、テストがあるからこそ安心してチューニングに勤しむことができます。本当にテストは大事です。SQLのパフォーマンスチューニングは一種のリファクタリングなので、本当にテストは大事です(二回目)。
終わりに
感想
今回は、Bill Oneで効果が出たSQLチューニングを紹介しました。仮に非効率なSQLがあったとしても、AlloyDB や Cloud Spanner のようなスケーラブルな仕組みを採用することで影響を減らせる可能性はあるかもしれませんが、非効率なSQLを発見して修正するというプロセスは引き続き必要になると考えています。また、プロダクトのパフォーマンス低下はSQLのみで引き起こされるわけではないことから、DBのCPU使用率アラートで気づくようでは遅いと考えるようになっています*9。そこで、APM(Application Performance Management)の考え方の導入やオブザーバビリティ・エンジニアリングをもとに可観測性に向き合ってみたりと、Bill Oneでは現在でもさまざまなチャレンジが行われています。
また、サービスを素早く立ち上げるという意味では、プロダクトの開発初期はCloud SQL上のRDBで処理を完結させるのはとても楽だしこういったSQLの知見も活用できるため、メリットが大きいと考えています。ただ、プロダクトの成長に伴うデータ量増加や検索要件の複雑化によって、SQLではどうやっても十分なパフォーマンスが出なくなるという状況も考えられます。Bill Oneにおいても、もっと柔軟な検索を考えるならDBではなくElasticsearchへ移行しても良いのではという考えがあり、実際にElasticsearchを使用するならどういう設計にするか検証してみるチャレンジも行われました。とはいえ、これからもRDBのSQLは使う場面は多いと考えているので、この記事が何かの参考になればいいなと思っています。
おまけ
今回の記事を執筆するにあたり、できる限り PostgreSQL 文書 に記載されている内容を参照するようにしました。目的の文書を探すのは結構大変だったのですが、索引を使うと目的としている文書が見つけやすい、という豆知識を共有しておきます。
*1:Bill OneではTypeScriptやGoなどの言語も使用していますが、今回はKotlinの話しか出てこないため
*3:PostgreSQLではFROM句は必須ではない。話を単純にするためにFROM句はあるものとする
*4:created_atにインデックスを付与するという手があったかも、と記事を書きながら思った。が、当時思いつかなかったため試していない
*5:この記事では本題からずれるため詳細は省くが、処理待ちの問題はKotlinので解消させた
*6:式がDISTINCT、ORDER BY、GROUP BYの中で参照されていない限り、という制約がある。具体的にはリンク先の文書を参照
*7:Flyway利用の場合、トランザクションを利用しない設定が必要。参考
*8:一時期、Cloud SQL上でこの機能を有効にするとパフォーマンスが低下していたため、機能をすぐには有効にできなかった
*9:極端な話、大金を積んでDBをハイスペックにしたらCPUの問題は発生しにくくなるため、このアラートに頼るのが適切かどうか怪しい