
はじめに
こんにちは、技術本部Bill One Engineering UnitでBill Oneのアーキテクトを担当している加藤です。最近までSREチームの一員として、Webアプリケーションのオブザーバビリティ1 向上に取り組んできました。開発チームの規模が拡大するなか、誰でも簡単にアプリケーション内部の状態を理解し、信頼性やパフォーマンスに関する問題を未然に防げるようにするためです。
Bill Oneではメインのアプリケーション実行環境としてフルマネージドなCloud Runを使用しています。今回はCloud Runで稼働するWebアプリケーションにOpenTelemetryを適用し、Cloud Trace以外のAPM (Application Performance Management) にトレースを送信した際の学びをご紹介します。
Cloud TraceはGoogle Cloudが提供するトレースサービスで、Cloud RunでCloud Traceを利用する場合の情報は公式のものを含め多く見つかります。一方でCloud Trace以外のAPMを使う場合の情報はそこまで多くなく、その場合に固有のハマりどころもあったので、詳しくご紹介したいと思います。
なお、この記事は【Bill One 開発 Unit ブログリレー】という連載記事のひとつです。
目次
- はじめに
- 目次
- Cloud RunとOpenTelemetry
- Cloud Runにおけるトレース伝播の特徴
- Cloud RunでCloud Trace以外のAPMを使う場合の困りどころ
- 問題への対応方法
- Cloud RunでOpenTelemetryを使う場合のその他の注意点
- まとめ
Cloud RunとOpenTelemetry
Cloud RunはGoogle Cloudが提供するフルマネージドなコンテナ実行環境で、Webアプリケーションを手軽にデプロイして運用できます2 。Cloud Runのリクエストログやメトリクスは自動で収集され、Cloud LoggingやCloud Monitoringで閲覧できますが、アプリケーション内部の状態を知るためには自前での実装が必要です。
アプリケーション内部の状態を知るために近年一般的に使われるのがOpenTelemetryです。ログやメトリクスなどのテレメトリーデータを特定のベンダーに依存せずに扱うための標準仕様で、さまざまな言語でのライブラリ実装も充実しており、手軽に使い始められます。OpenTelemetryで収集したデータをAPMベンダーに送信する場合、後からベンダーを変更したくなったとしてもアプリケーション実装の変更は最小限で済みます。
OpenTelemetryが扱うテレメトリーデータは大きく次の3つに分けられますが、この記事では主にトレースに注目します。
- トレース:複数のコンポーネント間のリクエストの経路や処理の流れを表すデータ
- メトリクス:アプリケーションやシステムのパフォーマンスや状態を数値化したデータ
- ログ:アプリケーションの動作やイベントを記録したデータ
Cloud Runにおけるトレース伝播の特徴
マイクロサービス環境など、1つのリクエストの処理に複数のCloud Runが関わる場合、トレースのコンテキストを伝播させることで、一連の処理の流れを追えるようになります。Cloud Runにおけるトレースの伝播には特徴的なところがあるので紹介します。
なおCloud Runに限らず、App EngineやCloud Functions、Load Balancingでも同様の挙動になります。
特徴1: 外部からのリクエストに自動的にx-cloud-trace-contextヘッダーが付与される
Cloud Runでは、Google Cloud外部からのHTTPリクエストに自動的に x-cloud-trace-context ヘッダーが付与されます。 x-cloud-trace-context ヘッダーは次のような構成になっています 3。

このとき、Trace IDは一連のリクエスト群に対応し、Span IDは個々のリクエストに対応します。例えば、次のようにCloud RunのUpstreamサービスからDownstreamサービスにリクエストをプロキシする場合、Trace IDは同じでSpan IDはそれぞれ異なります。
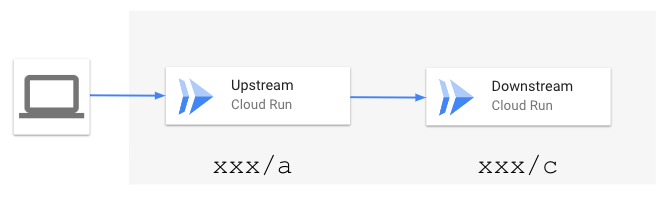
Cloud Runのリクエストログには自動的にこのTrace IDとSpan IDが書き込まれるほか、Webアプリケーションが出力する構造化ログにこれらの値を含めることで、リクエストの一連の流れを簡単に追えます。
特徴2: Span IDはCloud Runによって自動的に書き換えられる
ここで興味深いのが、Upstreamから受け取った x-cloud-trace-context ヘッダーを、Downstreamに送信するリクエストのHTTPヘッダーにそのまま付与するだけで、下流のCloud Runでは新しいSpan IDを観測できることです。つまりSpan IDはCloud Runによって自動で書き換えられます。
これによって、アプリケーションでSpan IDを書き換えるという手間なく、個々のリクエストを識別できます。
特徴3: x-cloud-trace-contextヘッダーとtraceparentヘッダーの値は連動する
もう一つ興味深いのが、 traceparent ヘッダーも付与されることです。 x-cloud-trace-context ヘッダーがGoogle Cloud独自のヘッダーなのに対し、 traceparent はW3Cで標準化されたヘッダーで、次のような構成になっています。

traceparent ヘッダーでParent IDと呼ばれる部分が x-cloud-trace-context ヘッダーのSpan IDに相当するので、この記事ではSpan IDの呼称で統一します。 x-cloud-trace-context ヘッダーのSpan IDは10進数表記ですが、 traceparent ヘッダーのSpan IDは16進数表記です。このため2つのヘッダーで別々のSpan IDが付与されているようにも見えますが、どちらのヘッダーを参照しても同じIDを取得できます。
x-cloud-trace-context ヘッダーだけを付与してCloud Runにリクエストを送った場合は、同じTrace IDの traceparent ヘッダーが作られ、逆もまた同様です。
これは筆者の推測ですが、OpenTelemetryなど traceparent ヘッダーに対応しているライブラリを使えば、Google Cloud独自の x-cloud-trace-context ヘッダーを意識しなくてもリクエストをトレースできるようにこのような仕様になっていると考えられます。
Cloud RunでCloud Trace以外のAPMを使う場合の困りどころ
さて、これらの特徴はGoogle Cloudだけを使う場合には便利なのですが、Cloud Trace以外のAPMを使う場合にちょっと困ることがあります。次のようなSpanがある状況を想定して、発生する問題を詳しく見ていきます。なお、以降でSpan(x) は「Span IDが x であるSpan」を意味するものとします。

問題1: Downstreamサービスから見ると、Upstreamサービスの直接の親であるSpan IDがわからない
通常OpenTelemetryのライブラリでは、新しいSpanを作る際に現在のSpanを親として認識します。Downstreamサービスで新しいSpanを作る場合、 Span(c) を親として Span(d)を作ります。
上記の図中で点線で表されている Span(a) や Span(c) はCloud Runが自動生成するもので、通常の利用方法ではアプリケーションからAPMベンダーに送信されません 4 。すると、APMベンダーから見ると図中で塗りつぶしで表されている Span(b) と Span(d) のデータだけが存在し、 Span(b) と Span(d) の間の親子関係が分からなくなってしまいます。
問題2: APMから見ると親を持たないSpanが存在しない
また、APMベンダーによっては親を持たないSpanを「Root Span」として特別扱いする場合があります。上記の図では Span(a) がRoot Spanです。しかし、APMベンダーに送信される Span(b) と Span(d) はどちらも Span(a) やSpan(c) を親として持つため、APMベンダーから見るとRoot Spanが見つからず、特定の機能が使えない場合があります。
検証した範囲では、Splunk APMでは特に問題がないように見えました。しかしDatadog APMではトレースが不完全と見なされ、Root Spanのレイテンシの内訳を見るLatency Breakdown機能が使えませんでした 5 。
問題への対応方法
これらの問題への対応にあたっては、以下の記事を大いに参考にさせていただきました。
記事内でいくつかの対処法が提案されていますが、Bill Oneでは b3 ヘッダーを使って親のSpan IDを伝播することにしました。 b3 ヘッダーは元々分散トレーシングツールのZipkinで使われていたヘッダーが標準化されたもので、次のような特徴を持ちます。
- Cloud RunがSpan IDの書き換えを行わない
- OpenTelemetryの公式Propagatorの一覧に含まれている 6
traceparentヘッダーと構造がよく似ていて読みやすい

問題1への対応
単純に b3 ヘッダーだけを使うと、Google Cloudで使われるTrace IDとは別のTrace IDを発番することになり、Google CloudとAPMでTrace IDの差異が生まれてしまいます。そこで b3 ヘッダーと traceparent ヘッダーの両方を使い、Span IDを参照するときは b3 ヘッダーを優先することにしました。
つまり、 b3 ヘッダーが無い場合(Google Cloud外部からのリクエスト)は traceparent ヘッダーを参照し、 b3 ヘッダーが有る場合(別のCloud Runからのリクエスト)は b3 ヘッダーを参照します。こうすることで、 Span(b) の親は Span(a) となり、 Span(d) の親は Span(b) となるので、問題1が解決します。
例えばOpenTelemetryのJavaでは次の設定をすることで、 b3 ヘッダーを優先できます7。
OTEL_PROPAGATORS=tracecontext,b3

問題2への対応
上記の設定をした場合、問題2は残ってしまいます。Span(b) の親は Span(a) となり、 Span(a) はAPMベンダーに送信されないためです。
問題2を解決するためには、次のように設定すると良いでしょう。 こうすると、 Span(b) の親は空になり、Root Spanだと認識されます。代償として、下記の図のようにCloud Runが生成するTrace ID(xxx)とアプリケーションが生成するTrace ID(yyy)に差異が生まれてしまいます 8。
# Upstream OTEL_PROPAGATORS=b3 # Downstream OTEL_PROPAGATORS=tracecontext,b3

Cloud RunでOpenTelemetryを使う場合のその他の注意点
他にもCloud Runにおける注意点があります。
Cloud Runではサイドカーコンテナを利用できない
コンテナ環境でOpenTelemetryを使う場合、サイドカーコンテナでOpenTelemetry Collectorを起動するのが一般的です。しかし、Cloud Runではサイドカーコンテナを使えません。(と書いている側から複数コンテナ機能がPreviewで使えるようになったので、今後に期待です。)
このため、OpenTelemetry Collectorを別途起動するか、APMベンダーに直接テレメトリーデータを送信する必要があります。前者の場合、不正なアクセスを防ぐため、アプリケーションとCollectorの間ではServerAuthenticatorを使うなど、適切に認証を設定する必要があります。
コンテナのコールドスタートの所要時間が増える可能性がある
OpenTelemetryの導入方法によっては、アプリケーションの起動時間が遅くなる可能性があります。例えばJVMアプリケーションを自動計装する場合、Java Agentでクラスローダーの書き換えを行うので、起動時間が遅くなります。Cloud Runはトラフィックに応じてスケールアウトするため、コールドスタートに当たったリクエストのレイテンシが増大してしまいます。
Bill Oneでは、単純にJava Agentを導入した場合、4秒程度で起動していたアプリケーションが9秒ほどかかるようになってしまいました。環境変数で不要な自動計装を無効化したり、CPU Boostを有効にすることで、6秒ほどで起動するようになりました。
他にも、コストはかかりますが最低インスタンス数を設定することで、コールドスタートの可能性を減らすという方法もあるでしょう。
バックグラウンドでCPUが割り当てられないことが影響する可能性がある
Cloud Runでは通常コンテナがHTTPリクエストを処理している間しかCPUが割り当てられず、バックグラウンドで処理を行うのは難しいです。このため、テレメトリーデータを送信するタイミングによってはCPUが割り当てられず、正常に送信できなくてスパン情報が欠落する可能性があります。
この問題はコンテナが継続的にリクエストを処理している場合はあまり起きないので許容するか、コストはかかるもののCPUを常に割り当てる設定をすることで回避できます。
まとめ
この記事では、Cloud RunでCloud Trace以外のAPMを使う場合の注意点をご紹介しました。Cloud Runの特徴を理解し、OpenTelemetryを適切に設定することで、より良いオブザーバビリティを得る助けになれば幸いです。
Bill OneではSRE (Site Reliabilityエンジニア) を募集しています。この記事のような活動を通して、急成長するサービスの信頼性を向上することに興味ある方のご応募をお待ちしております。
- 可観測性と訳されます。書籍 オブザーバビリティ・エンジニアリング では、オブザーバビリティが「システムがどのような状態になったとしても、それがどんなに斬新で奇妙なものであっても、どれだけ理解し説明できるかを示す尺度」と説明されています。↩
- Cloud Run for Anthosはこの記事の対象外です。↩
- 詳細はドキュメントを参照。↩
-
無理矢理送信したとしても、
Span(b)とSpan(c)の親子関係はわかりません。↩ - 未検証ですが、参考記事によるとHoneycombでも利用できない機能があるようです。↩
- PropagatorはOpenTelemetryにおいてトレースのコンテキストを伝播するコンポーネントです。↩
- 後ろに書かれたものが優先されることはドキュメントで見つけられず、実装依存となります。↩
-
未検証ですが、Upstreamで
b3ヘッダーが存在しない場合はtraceparentヘッダーのTrace IDを使ってRoot Spanを生成するような特殊な実装をすれば、Trace IDを共通にできるかもしれません。↩