
はじめに:なぜ今、Sansanでデータをやるのか
こんにちは。研究開発部 Data Direction Group(以下、DDG)の坂口です。
Data Direction Groupブログリレー(全6回)の記念すべき1つめのブログとなります。
2023年9月に入社し、現在は全社横断のデータ基盤開発と利活用、後述する新規事業のプロダクト開発をリードしています。
昨今、猫も杓子も「生成AI」の時代です。多くの企業がAI活用を模索していますが、私は「AIの価値は、食わせるデータの質と独自性で決まる」と考えています。
私がSansanを選んだ理由はまさにそこにあります。
Sansanには「名刺」というユニークな接点データに加え、Bill One(経理AXサービス)、Contract One(AI契約データベース)といった、企業活動の核心に迫るデータが大規模に蓄積されています。「これらを統合すれば、これまで誰もなし得なかったシナジーが生み出せる。」とワクワクして入社したのを覚えています。
入社から2年半。最初は社内の基盤整備から始まった私の活動は、今まさに「Sansan AIエージェント」という新規事業として、顧客に直接価値を届けるフェーズへ突入しました。
今回は、我々がどのようにして「社内下請け」ではなく「収益を生み出すデータ組織」へと変貌し、独自のAIエージェント開発に挑んでいるのかをお話しします。
フェーズ1:「収益を生み出す」ことにこだわったデータ基盤整備
入社当初、私はData Direction Team(DDT)に配属されました。当時のミッションは、社内に散在するデータを統合する全社横断データ分析基盤「Colossus」の構築と、社内利活用の推進でした。
データエンジニアリングの世界では、基盤構築やガバナンスといった「守り」の領域が注目されがちです。しかし、私はチームをリードする上で「データの活用でちゃんと収益を生み出す組織になる」ことを徹底しました。
エンジニアリングの価値を金額換算することに抵抗がある方もいるかもしれません。しかし、企業活動である以上、PL(損益計算書)にヒットしない活動は「自己満足」で終わるリスクがあります。
たとえ概算であっても、自分たちの施策が「いくらのインパクトを生んだか」を定量化し続ける。これを徹底した結果、社内プロジェクトだけで数千万円規模のインパクトを可視化でき、データ活用の価値を組織に認めさせることができました。
フェーズ2:社内活用から、顧客価値(社外)へ
社内の業務効率化だけでは、生み出せる価値に天井があります。本当の意味でデータを資産化するには、それを顧客価値に変え、トップライン(売上)に貢献する必要があります。
そこで我々は、蓄積したナレッジとデータ基盤をベースに、顧客向けの新規プロダクトである「Sansan BI」、そしてその進化系である「Sansan AIエージェント」の開発へと舵を切りました。
これに伴い、組織も拡大しました。他チームからの合流や積極的な採用を経て、現在は12名(ちなみに自分が入社した時は5名!倍以上!)の「Data Direction Group」として活動しています。
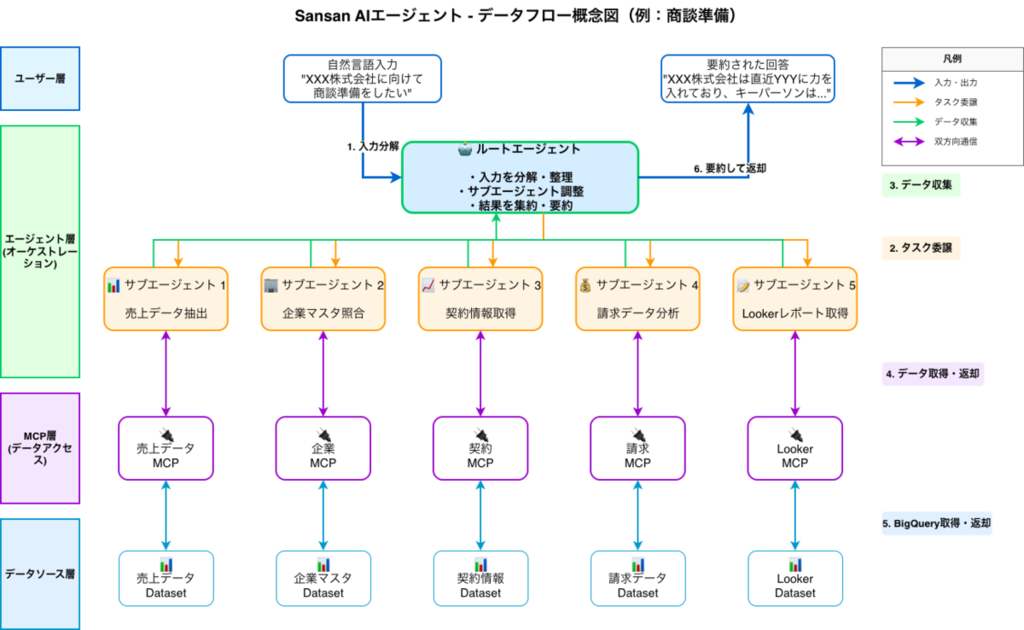
Sansan AIエージェントとは:営業の「行動」を変えるタスク指向型パートナー
我々が開発している「Sansan AIエージェント」は、顧客の営業組織全体がデータに基づいて再現性高く成果を上げられるようにするための、「タスク指向型エージェント」です。
これまでの営業活動では、SFA、名刺管理ツール、契約書、請求書など、社内に散在するシステムから情報を手作業で集め、属人的な経験則で解釈して行動する必要がありました。
Sansan AIエージェントは、これらのデータを「企業」や「人物」単位に統合、文脈を理解した状態で保持し、特定のタスクに特化させた複数のSub Agentを備えています。
最大の特徴は、ユーザーにプロンプトエンジニアリングを求めない点です。
ユーザーは「商談準備」や「ネクストアクションの洗い出し」といったタスクを選択するだけで、AIが裏側で統合されたデータを参照し、「質の高いドラフト(叩き台)」や「実行すべきタスクリスト」を瞬時に提示します。
「データを探す・まとめる」時間をゼロにし、誰もがトップセールスのような質の高い意思決定と行動ができる状態を作る。それがこのプロダクトの狙いです。
Sansan AIエージェントの4つの"価値"
日本のBtoB SaaSにおいて、ここまで本気でエージェントを作りに行ける企業は多くないと考えています。その理由は、Sansanが持つ「構造的な優位性」にあります。
1. 独自の結合キー「Sansan Organization Code(SOC)」
AIがハルシネーション(嘘)をつかず正確に回答するには、バラバラなデータを一意に特定するIDが必要です。AIに「株式会社サトウについて教えて」と聞いて、一意の株式会社サトウに関する回答を得ることはかなり難しいです。
Sansanには、長年築き上げてきた名寄せロジックによるSOC(企業コード)などの強力なID体系があり、名刺、商談情報(Sansanプロダクト上ではコンタクトと呼ばれています)、企業情報、ニュースなどを正確に統合できます。
2. 高精度なデータ化技術とタッチポイントの網羅性
SFA(営業支援システム)に入力された主観的な情報だけでなく、「誰と誰がいつ会ったか」という名刺・メールベースの客観的な事実データを網羅しています。また、Sansanはデータ化に長年向き合ってきたため、高品質なデータの蓄積ができています。
これにより、AIはファクトに基づいた精度の高い提案が可能になります。
3. セマンティックレイヤーの構築
我々はGoogle CloudのLookerなどのBIツールを活用し、ただモデリングするだけではなく、データに「ビジネスの意味」を定義しています。これにより、AIがユーザーの意図を正しく解釈し、SQLを生成したりデータを抽出したりすることが可能になります。
4. FDE(Forward Deployed Engineer)によるラストワンマイルの支援
ここが非常に重要です。どれだけ優れたプロダクトがあっても、顧客ごとのデータ環境は千差万別で、導入してすぐにAIが完璧に動くとは限りません。
我々には、FDE(Forward Deployed Engineer)と呼ばれるエンジニア部隊がいます。彼らは顧客に寄り添い、個社固有のデータモデル構築、業務プロセスの設計、オンボーディングを技術面から支援します。
「プロダクトの汎用性」と「個社ごとの泥臭いデータ整備」のギャップをエンジニアリングで埋めきる。この「プロダクト × 人(FDE)」のモデルこそが、他社にはなかなか真似できない最大の障壁です。
「データはあるけど使えない」という企業が多い中、我々は「使える状態に整備されたユニークなデータ」を持っています。これが最大の武器です。
データ利活用部隊が、プロダクト開発のど真ん中へ
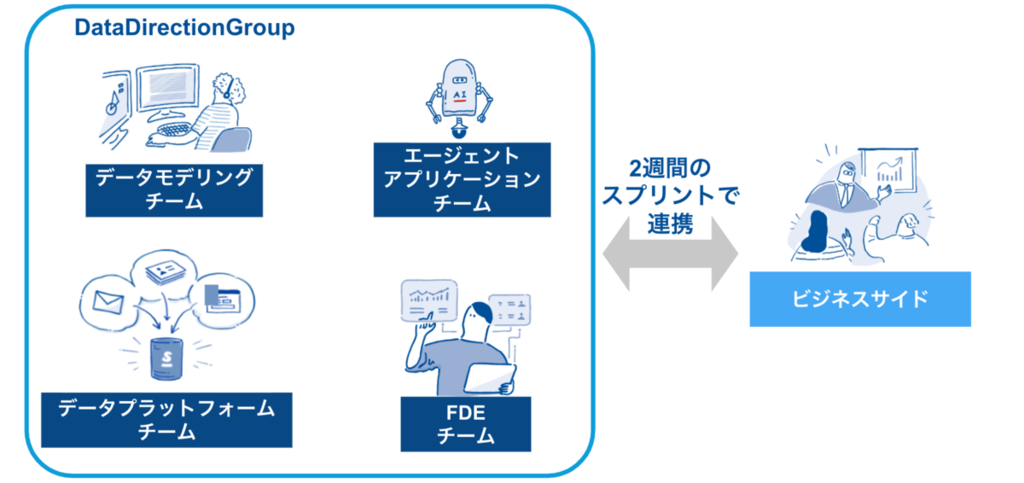
現在、我々DDGは次の体制で開発を進めています。
- エージェントアプリケーションチーム: AIエージェントのコア機能とUI開発
- データモデリングチーム: AIが必要とするデータ連携・セマンティックレイヤーの構築
- データプラットフォームチーム: 全社共通のDWHや開発基盤の整備
- FDEチーム:SansanAI エージェントのプリセールス、顧客への装着支援
これまでは「社内のデータ分析部隊」という立ち位置でしたが、今では「AIプロダクト開発の中核」を担っています。ビジネスサイド(事業責任者やPdM)とも2週間ごとのスプリントで密に連携し、ビジネス戦略を直接エンジニアリングに落とし込んでいます。
最後に:「データから収益を生み出す」を体現したいエンジニアへ
データに関わる人間(特にデータエンジニア、アナリティクスエンジニア)であれば、誰しも「自分の整備したデータが、直接お金を生み出す瞬間」を見てみたいと思うのではないでしょうか。
Sansanには、それを実現できる環境があります。
- ユニークで大規模なデータ資産
- 「収益を生み出す」ことにコミットする組織文化
- 最先端のAIエージェント開発への挑戦権
これらが揃っている環境は、日本ではそう多くありません。
すでにある資産を活かし、本気で世界に通用するAIエージェントを作りたい方。ぜひ一度、お話ししましょう。
Sansan技術本部ではカジュアル面談を実施しています 
Sansan技術本部では中途の方向けにカジュアル面談を実施しています。Sansan技術本部での働き方、仕事の魅力について、現役エンジニアの視点からお話しします。「実際に働く人の話を直接聞きたい」「どんな人が働いているのかを事前に知っておきたい」とお考えの方は、ぜひエントリーをご検討ください。