
こんにちは,DSOC R&Dグループ インターン生の内田です. 勉強会レポートで間が空いたので久しぶりの連載です.
今回も引き続き「超解像歴史探訪-2018年編-」やっ!!!
と思ったんですが,折角なので2018年はすっ飛ばして,先日開催されたCVPR2019にフォーカスしたいと思います.
CVPRとは
CVPR(Conference on Computer Vision and Pattern Recognition)とは,毎年アメリカで開催されるコンピュータビジョン系のトップ会議です. 今年は6月16日から6月20日の間,カリフォルニア州のロングビーチでの開催でした. ここ数年は深層学習ブームに乗っかる形でどんどん投稿数が増え,今年はなんと5,165本の論文が投稿され,そのうち1,294本の論文が採択されました. ちなみにこれは本会議だけの話で,併設で開催されているワークショップも含めるともう大変です. これらはすべて無料で公開されているため,下記から誰でも手軽に読むことができます.
CVPR2019における超解像
まずタイトルで「Super-Resolution」と検索すると,16本の論文がヒットします. タイトルに含まれていないものも合わせると,超解像を取り扱っている論文は大体20本くらいありました. 大まかに目を通してみて,個人的に面白いなと思った論文をいくつか紹介します. 図は論文から引用しています.
Blind Super-Resolution With Iterative Kernel Correction[*1]
従来研究されてきた超解像手法では,高解像度画像(HR)画像に対して,単純なダウンサンプルを適用して低解像度(LR)画像を作成して学習することがほとんどでした. この方法だと,外乱が少なかったりスケールが変わらないような環境下では上手くいくのですが,実環境下では多くの劣化を経由するため,上手くいかない場合がほとんどです.
まずこの論文では,学習セットのカーネルサイズと入力画像のカーネルサイズの不整合が出力画像に与える影響について,次の図を用いて説明しています.
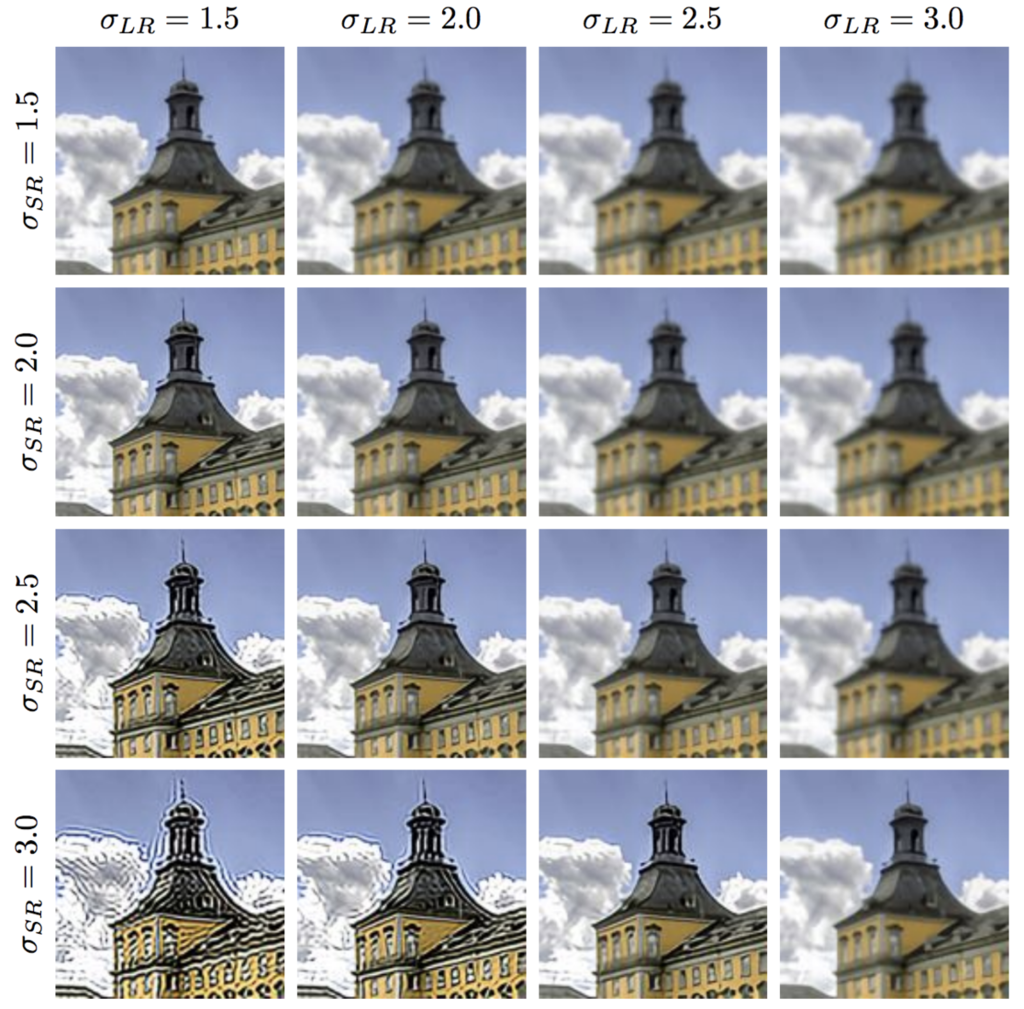
,
は,それぞれ超解像アルゴリズムの想定するカーネルサイズ,低解像度画像に適用されているカーネルサイズを示しています.
のときにはボケた画像が出力され,
のときにはエッジ周辺にアーティファクトが発生することが見て取れると思います.
したがって,超解像の実用を考える場合には,入力画像にどんなダウンサンプルが施されているかを推定しながら超解像を行う必要があるといえます.
このように,不明なダウンサンプルが適用されている状態で超解像を行う問題設定を,Blind Super-Resolution*2といいます.
この問題に対し,著者らは次のようなネットワークを用いて反復的にカーネルサイズを調整していく方法(Iterative Kernel Correction; IKC)を提案しています.
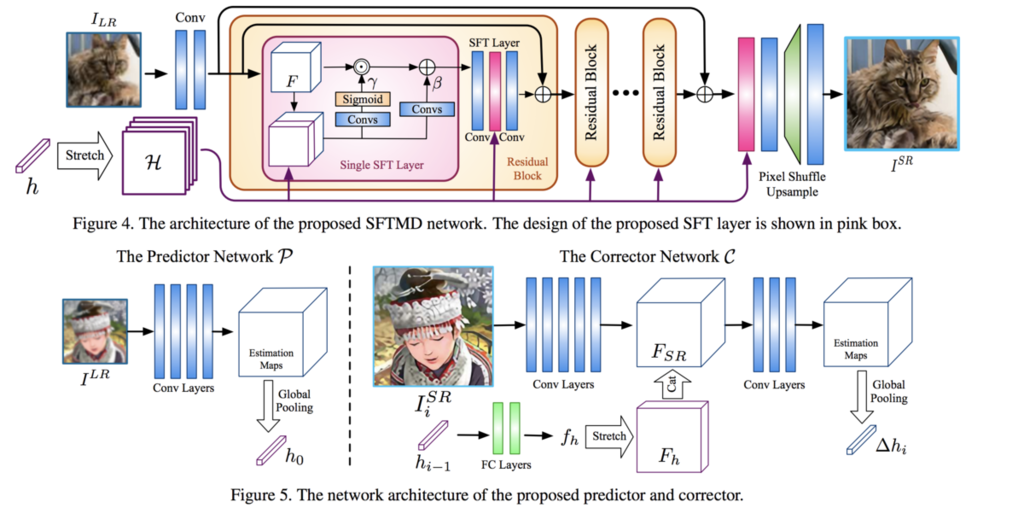
を入力として持つSFTMD,カーネルサイズを推定する推定器
,推定したカーネルサイズの誤差を推定する修正器
によって構成されます.
IKCでは,これらのコンポーネントを次のように反復的に適用することで,カーネルサイズを修正しながら超解像を行なっていきます.
によってカーネル
を推定
- LR画像
と
を出力
を推定
- カーネルを
に修正
- 修正したカーネルと
- 3.から5.の繰り返し
IKCを用いることで,反復ごとにメトリックおよび見た目が改善していきます.

実験では,ランダムなカーネルサイズによってダウンサンプルしたLRを含むデータセットで学習を行い,任意のカーネルサイズおよび倍率で高精度を達成しました.
また,ダウンサンプルしていない実際の画像に対しても自然な結果を得られることを確認しました.

Meta-SR: A Magnification-Arbitrary Network for Super-Resolution[*3]
以前連載で紹介したSRCNN[*4]やVDSR[*5]ではPre-upsamplingを用いていましたが,最近はほとんどのモデルがPost-upsamplingを採用しています. 計算量および特徴抽出の精度に優れるPost-upsamplingですが,1つできなかった事があります. それは 任意サイズへの拡大 です. 1つの画像を解像度の異なる複数のディスプレイに映したい場合,倍率は必ずしも整数になりませんし,入出力解像度ごとにモデルを学習しておくのは現実的ではないため,任意サイズへの拡大は実用面での需要がかなり高いです.
この論文では,Post-upsamplingのまま任意サイズへの拡大を行う方法(Meta-SR)を提案しています.
提案するネットワークの構造は次のような感じです.入力として倍率も入力します.
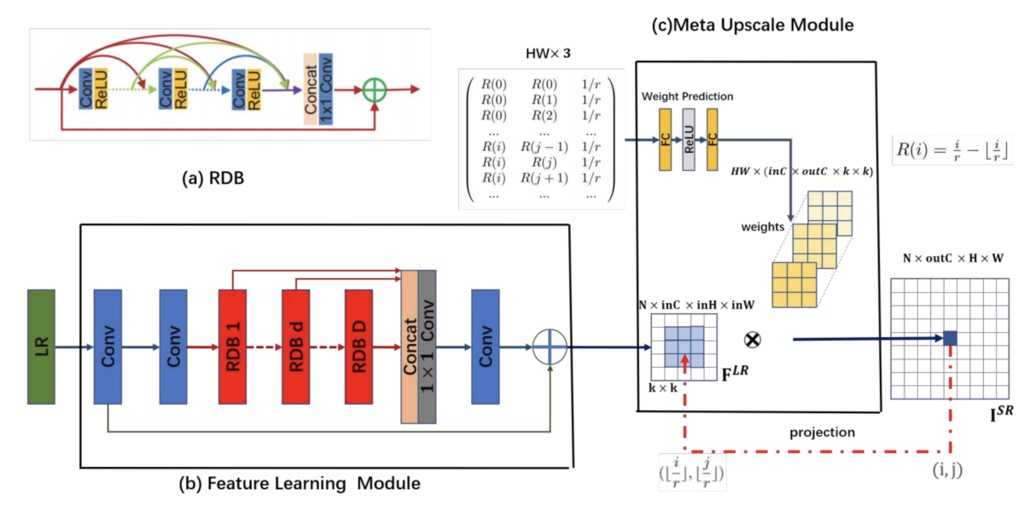
- 入力サイズと倍率
から出力サイズを計算
- 出力位置
に対応する特徴マップの位置を計算:
を線形層に入力してサイズ
のカーネルを推定:
近傍の
- 出力画素を計算:
- 2.から5.を出力画素全てに対して行う
実験では0.1刻みの倍率に対して評価を行なっています.
ただし,任意の倍率での超解像が可能なベースラインはない*6ので,ベースラインをPre-upsamplingに改造した方法と,ベースラインの出力を縮小する方法との比較を行います.
この比較がフェアかどうかは議論の余地があると思いますが,Meta-SRは単一のモデルで各倍率において高精度を叩き出しています.
また,固定倍率での超解像に関してもstate-of-the-artの手法と遜色ない結果を確認しています.
出力結果は次のような感じです.単一のモデルで任意の倍率で拡大できることが分かります.

Towards Real Scene Super-Resolution With Raw Images[*7]
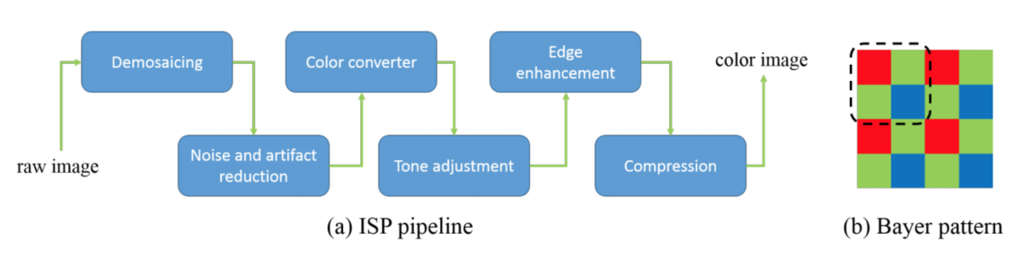
一般的なカメラは,CCDやCMOSのような撮像素子,すなわちイメージセンサを使って光強度を電気信号に変換しています. イメージセンサの受光面上にはべイヤフィルタ(下図(b))が配置されており,これにより色を捕捉しています. べイヤフィルタ通過後の生の信号をRaw画像といいます.
Raw画像は各周波数帯の信号値が格子状に並んでいるものなので,Raw画像から我々が目にするカラー画像を表示するには,信号値の配合や欠損値補間など様々な処理が必要です(下図(a)).
この過程でどうしてもRaw画像の情報の一部は欠落してしまい,画像処理の問題となったりします.
逆に言えば,Raw画像は非常にリッチな情報を持っているため,利用できれば精度向上が期待できます.
この論文では,情報が欠落していないRaw画像から超解像したカラー画像を得る方法(RawSR)を提案しています. まず,RawのHR-LR画像ペアは収集は難しいため,次のようにRaw-HR画像からRaw-LR画像を合成します.
- Raw-HR画像を線形色空間に写像して
を生成
を生成 $$X_{raw} = f_{Bayer}(f_{down}(X_{lin} \ast k_{def} \ast k_{mot})) + n \\ \begin{cases} f_{Bayer}:\text{ベイヤサンプリング} \\ f_{down}:\text{ダウンサンプリング} \\ k_{def}:\text{デフォーカス} \\ k_{mot}:\text{モーションブラー} \\ n:\text{ノイズ} \\ \end{cases}$$
- 汎用的な手法で
を生成
上記で得た,
を入力して,次のネットワークを学習していきます.
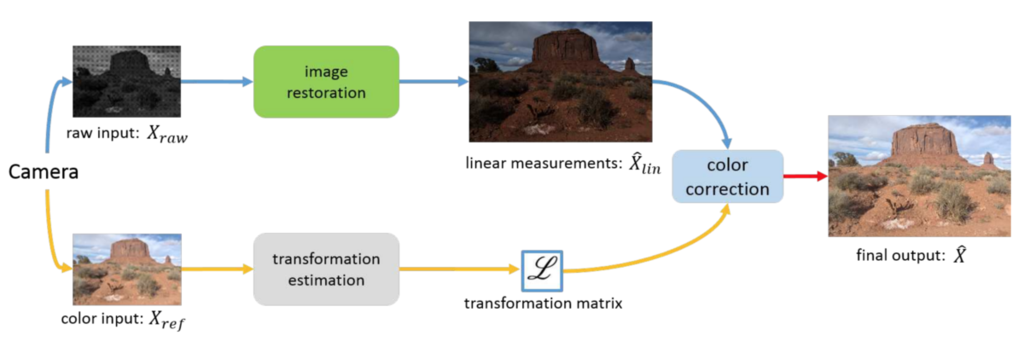
から
を復元することを目標に学習を行います.
また,下のブランチでは,
の色を参照して,線形色空間から非線形色空間への色変換行列
を算出します.
実際には,単一の色変換行列ではうまく行かないため,
は画素毎の変換行列を持つテンソルになります.
実験では,Rawを使って学習することの有効性,画像復元と色変換を分けることの有効性を確認しています.
結果は次のようになっています.
最近ではCNNのモデル軽量化なども盛んに研究されているので,カメラ上に実装されるのもそう遠くはないかもという期待を抱かせてくれます.

Zoom to Learn, Learn to Zoom[*8]
カメラのズームには光学ズームとディジタルズームがあります. 光学ズームはレンズを前後に動かすことにより焦点距離を変化させて像を大きくする方法で,ディジタルズームはセンサの信号を拡大する方法です. 光学ズームは原理上画質の劣化はありませんが,ディジタルズームはすでに画素に焼き付いてしまった情報を拡大することになるので,画質が劣化します. しかし,スマートフォンのような小型デバイスでは,レンズ間の距離が出せないため,基本的にディジタルズームを採用せざるを得ません. とはいえ,カメラ好きの人は「スマートフォンで光学ズームできたら…」という思いを抱いているのではないでしょうか.
この論文では,光学ズームを用いて収集したHR-LR画像ペアで構成されたデータセット(SR-RAW)を提案しています.
画像ペアが共に真値であるため,レンズの歪みなどをモデル化してLR画像を生成する必要がなく,自然にダウンサンプルされたペアを用いて学習することができます.
含まれているデータは,次のように複数の焦点距離で撮影した画像の共通領域となっています.



さぁて,次の論文は
と行きたいところですが,まとめる時間がなかったためこの辺にしておきます.
まとめ
今回はCVPRに採択された論文から4本ピックアップして紹介しました. 個人的に感じたのは,去年までの精度競争は一段落して,実用化への機運がかなり高まっているということでした. IKCやSR-RAWデータセットは決め打ちのダウンサンプルからの脱却みたいなところを目指しています. RawSRはカメラでの使用を念頭に置いていたり,Meta-SRは任意デバイスへの対応を予感させます. 今回紹介できませんでしたが,ステレオ画像や類似画像,動画を用いた手法も提案されてきていて,デバイスの高性能化に伴って,使える情報は使おう的な流れもあります. 近い将来,手元で手軽に超解像できる時代が来るかもしれませんので,これからも注視していく所存です.
*1:Gu, Jinjin, et al. "Blind super-resolution with iterative kernel correction." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
*2:今回は劣化をガウシアンブラーに限定しているので完全にBlindとは言えません.
*3:Hu, Xuecai, et al. "Meta-SR: A Magnification-Arbitrary Network for Super-Resolution." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
*4:Dong, Chao, et al. "Learning a deep convolutional network for image super-resolution." European conference on computer vision. Springer, Cham, 2014.
*5:Kim, Jiwon, Jung Kwon Lee, and Kyoung Mu Lee. "Accurate image super-resolution using very deep convolutional networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
*6:あってもSRCNNやVDSRなど古いやつです.
*7:Xu, Xiangyu, Yongrui Ma, and Wenxiu Sun. "Towards Real Scene Super-Resolution with Raw Images." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
*8:Zhang, Xuaner, et al. "Zoom to Learn, Learn to Zoom." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.