こんにちは、研究開発部Architectグループの山本です。 昨年に引き続き、研究開発部の新卒社員向けに開発研修を行いました。 今年の研修では、私自身が昨年受けた経験をもとに感じた改善点や部内での技術的なアップデートを踏まえて実施しました。 昨年の記事を読んでいない方でも分かりやすい構成にしたので、ぜひご一読ください。
昨年の記事はこちら。 buildersbox.corp-sansan.com
本記事は前編と後編に分かれています。 主に前編ではローカル環境でPythonでサービスを開発するパートを紹介し、後編ではサービスをデプロイするパートを解説します。
研修の目的
本研修では、新入社員が効率的に業務に必要な知識を獲得し、素早くチームで活躍できるようにすることが目的となります。 最終的には新卒・中途と問わず、R&D内の技術を多角的に学べ、再利用可能な研修にします。
研修の概要
昨年と同様に、ダミーデータで構成される名刺交換履歴から各ユーザの類似人物を表示するWebサービスを作成します。

このサービスは以下の3つのステップに分けて実装されます。
- データソースからデータを取得し、モデルの学習&予測を行うバッチをgokartで作成
- バッチが出力したデータを提供するAPIをFastAPIで作成
- APIから類似人物データを取得し、表示するWebアプリをStreamlitで作成
大まかな変更点としては、
- バッチのデータソースを
Athena->Colossusに変更 - API、APPの追加課題の作成
- terraformでECRを作成する手順の追加
となります。
Colossusとは、R&Dで開発された全社横断データ基盤です。 speakerdeck.com
R&D内のサービス全体としてデータソースをColossusに統一する動きがあり、本研修でも取り入れました。
2つ目の追加課題の作成に関しては、DIやドメイン駆動開発といった要素を実際に手を動かしながら理解できるようにする意図があります。
3つ目のECR作成のパートは、単純なインフラ構築をできる人を増やすことが目的で追加しました。
バッチ編
バッチのデータソースとして、次のような名刺交換履歴を示すテーブルを用意しました。1つの行が一回の名刺交換を意味しています。
| owner_user_id | owner_company_id | user_id | company_id | created_at |
|---|---|---|---|---|
| 29138504 | 2685496293 | 11806122 | 789710164 | 2022-06-26T15:30:43.693079 |
| 128977144 | 7702272602 | 11806122 | 789710164 | 2022-02-28T13:02:21.579818 |
| 351077821 | 6646208106 | 11806122 | 789710164 | 2021-01-15T20:41:22.127413 |
| 574143553 | 5228064161 | 11806122 | 789710164 | 2021-08-02T16:17:08.831122 |
| 579994816 | 6221642784 | 11806122 | 789710164 | 2023-05-05T00:56:30.033660 |
| 584865611 | 5411900211 | 11806122 | 789710164 | 2021-01-10T21:21:51.592997 |
owner_user_id: 名刺所有者のユーザID
owner_company_id: 名刺所有者の会社ID
user_id: 名刺記載ユーザのユーザID
company_id: 名刺記載ユーザの会社ID
created_at: 交換日時
バッチの全体像は以下の通りです。
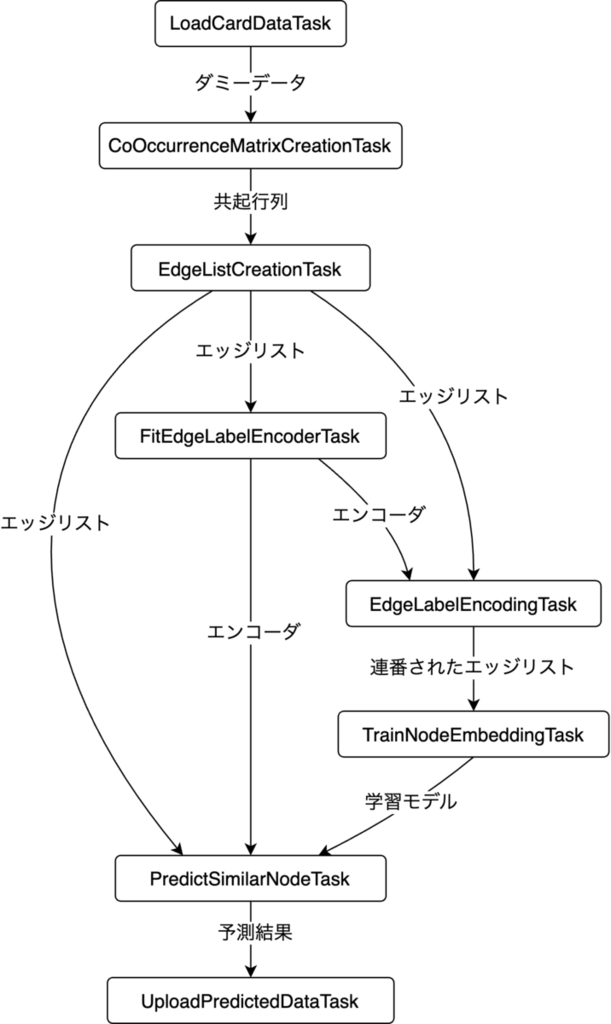
- LoadDataTask: データソース(Colossus)からダミーデータを取得
- CoOccurrenceMatrixCreationTask: ダミーデータから共起行列を生成
- EdgeListCreationTask: 共起行列をもとにエッジリストを生成
- FitEdgeLabelEncoderTask: ノードの値と連番のIDを相互変換するEncoderを作る
- EdgeLabelEncodingTask: ノード番号をEncoderで連番にする
- TrainNodeEmbeddingTask: NodeEmbeddingモデルの学習
- PredictSimilarNodeTask: 学習モデルによる類似人物の予測
- UploadPredictedDataTask: 予測結果をS3にアップロード
LoadDataTaskの実装は次のようになります。
class LoadCardDataTask(GokartTask): """Colossusからダミーデータを取得""" def run(self) -> None: sql = """ SELECT owner_user_id, company_id FROM `colossus-access-randd.randd__source__non_entrusted.business_cards_dummy` """ client = bigquery.Client() data_frame = client.query(sql).to_dataframe() self.dump(data_frame)
LoadCardDataTask以外の実装に関してはほぼ昨年と同様なので、詳細が気になる方は昨年の資料をご覧ください。
また、全体のソースコードはこちらにあります。
最終的な出力は、owner_user_idをキー、ユーザとの類似度が高いユーザのuser_idとsimilarityを値とするようなJSONとなります。
{
"4421142743": [
{
"user_id": "5188836446",
"similarity": 0.99
},
{
"user_id": "9157874476",
"similarity": 0.98
},
{
"user_id": "4331163609",
"similarity": 0.95
}
],
.
.
.
}
API編
APIでは、バッチの出力データを返す2つのエンドポイントを作成します。
/persons- すべてのユーザのuser_idのリストを返す
/persons/{owner_user_id}- ユーザ(
owner_user_id)の類似人物情報のリストを返す。
- ユーザ(
テンプレートについて
プロジェクトを一から作るのではなく、cookiecutterというテンプレート生成ツールを用いて作成します。 詳しくは以下の記事をご覧ください。
cookiecutterで展開されるファイルは以下の通りです。
.
├── app
│ ├── config.py
│ ├── container.py
│ ├── guniconf.py
│ ├── __init__.py
│ ├── logging_and_timeout.py
│ ├── log.py
│ ├── main.py
│ ├── models
│ │ └── __init__.py
│ ├── repositories
│ │ ├── batch_result_repository.py
│ │ └── __init__.py
│ ├── routers
│ │ ├── health.py
│ │ ├── __init__.py
│ │ └── person.py
│ ├── schemas
│ │ ├── __init__.py
│ │ └── person.py
│ └── services
│ ├── batch_result_service.py
│ └── __init__.py
├── Dockerfile
├── pyproject.toml
├── README.md
└── tests
├── __init__.py
└── unit_test
├── __init__.py
└── test_sample.py
テンプレートには、ドメイン駆動開発やDIコンテナを実現するための最低限の実装を示すコードがあります。 ドメイン駆動な実装において、3つの層を意識してフォルダを分けしています。

modelsとservicesをビジネスロジック層としていますが、技術的な要件とは関係なく現実に存在するビジネスルールはmodels、実装する上で初めて必要になってくるビジネスルールはservicesという風な分け方をしています。
リバーシを例にとると、「同じ色にはさまれた石がひっくり返される」といった現実のルールはmodels、「盤上の配置をデータアクセス層から取得する」といった実装上のルールはservicesといった感じです。
DIを実現するために、repositories/batch_result_repository.pyにインターフェースが定義されています。これにより、外部依存を含む実装と含まない実装を共存させています。
class IBatchResultRepository(metaclass=ABCMeta): @property @abstractmethod def similar_persons(self) -> dict[str, list[dict]]: raise NotImplementedError class BatchResultRepository(IBatchResultRepository): """S3からバッチ結果を取得""" ... @property def similar_persons(self) -> dict[str, list[dict]]: return self._similar_persons class BatchResultLocalFileRepository(IBatchResultRepository): """ローカルからバッチ結果を取得""" ... @property def similar_persons(self) -> dict[str, list[str]]: return self._similar_persons
services/batch_result_service.pyでは、インターフェースIBatchResultRepositoryを引数として類似人物リストsimilar_personsを返す実装をしています。
class BatchResultService: def __init__(self, repository: IBatchResultRepository) -> None: self._repository = repository def get_similar_persons(self) -> dict[str, list[dict]]: return self._repository.similar_persons
DIコンテナは次のように実装されており、変数is_localの値でrepositoriesの具体実装が決められます。
class Container(containers.DeclarativeContainer): """ DIコンテナ """ wiring_config = containers.WiringConfiguration(modules=[".routers.person"]) env_config = providers.Configuration() if get_settings().is_local: batch_result_repository = providers.Resource(BatchResultLocalFileRepository) else: batch_result_repository = providers.Resource(BatchResultRepository, get_settings().batch_result_s3_url_base) # type: ignore[arg-type] batch_result_service = providers.Factory(BatchResultService, repository=batch_result_repository)
研修での実装箇所
このテンプレートで修正する必要のある、サービス固有の実装部分は
repositories- S3、ローカルからデータを取得
routers/persons,/persons/{person_name}のルーティング- ユーザ一覧の取得、類似人物の取得などの具体実装
schemas- responseなどのデータ型をpydantic、panderaで定義 となります。
ここまでは昨年の内容とほぼ変わらないです。興味のある方は昨年のソースコードをご覧ください。 github.com
追加課題
追加課題では、新たに追加された要件を満たすために、インターフェースの追加やDIコンテナの修正に挑戦します。
要件の整理
追加する要件として、バッチの出力結果を部分的に返すだけでなく、owner_user_idにひもづいた名刺や名刺交換履歴に関する詳細な情報を返すようにしたいです。
以下のような名刺情報を示すテーブルが新たに提供されます。
| user_id | company_id | full_name | position | company_name | address | phone_number |
|---|---|---|---|---|---|---|
| 6605351600 | 3882343658 | 近藤 聡太郎 | 技術次長 | 有限会社林鉱業 | 高知県高知市中央町1-2-5 | 080-7086-6882 |
| 4879617459 | 3882343658 | 斎藤 知実 | データサイエンティスト | 有限会社林鉱業 | 高知県高知市中央町1-2-5 | 52-6547-9356 |
| 1015780972 | 3882343658 | 吉田 陽子 | プロジェクトマネージャー | 有限会社林鉱業 | 高知県高知市中央町1-2-5 | 070-6744-7163 |
| 3319975372 | 3882343658 | 山本 和也 | ソフトウェアエンジニア | 有限会社林鉱業 | 高知県高知市中央町1-2-5 | 070-8902-8515 |
| 1668247132 | 8760623742 | 田中 里佳 | リードエンジニア | 有限会社阿部通信 | 千葉県佐倉市栄町1-10-2 | 070-7518-3046 |
| 6997790446 | 8760623742 | 木村 稔 | 課長 | 有限会社阿部通信 | 千葉県佐倉市栄町1-10-2 | 090-9047-1281 |
このとき、以下のようなエンドポイントを実装します。
/v2/cards/- 任意の数の名刺情報を返す。クエリパラメータ
offset,limitにより、出力する最初の要素と要素数を指定する。 - queryの例:
/v2/cards/?offset=1&limit=2
- 任意の数の名刺情報を返す。クエリパラメータ
v2/cards/{user_id}- ユーザ
user_idの名刺情報を返す - queryの例:
/v2/cards/5188836446
- ユーザ
v2/cards/{user_id}/similar- ユーザ
user_idの類似人物の名刺情報リストを返す - queryの例:
/v2/cards/4421142743/similar
- ユーザ
v2/contacts/- 任意の要素数の交換履歴を返す。クエリパラメータ
offset,limitにより、出力する最初の要素と要素数を指定する。 - queryの例:
/v2/contacts/?offset=1&limit=2
- 任意の要素数の交換履歴を返す。クエリパラメータ
v2/contacts/{user_id}- 任意のユーザ
owner_user_idの接点情報を返す。クエリパラメータoffset,limitにより、出力する最初の要素と要素数を指定する。 - queryの例:
/v2/contacts/129138504?offset=0&limit=1
- 任意のユーザ
これらのエンドポイントを、colossusのテーブルから得られる情報と組み合わせて実装します。
新たな実装箇所
すべての実装例はこちらにありますので、もし興味があればご覧ください。
重要な部分だけ抜粋します。
repositoriesに、次のようなInterfaceを定義し、colossusからデータを取得する実装を追加します。
class IBusinessCardRepository(metaclass=ABCMeta): @property @abstractmethod def business_cards_df(self) -> DataFrame[BusinessCardSchema]: raise NotImplementedError @property @abstractmethod def contacts_df(self) -> DataFrame[ContactHistorySchema]: raise NotImplementedError
名刺情報データフレーム(business_card_df)、名刺交換履歴データフレーム(contacts_df)をcolossusから取得しています。
DIコンテナは以下のような実装になります。
class Container(containers.DeclarativeContainer): wiring_config = containers.WiringConfiguration(modules=[".routers.cards", ".routers.contacts"]) env_config = providers.Configuration() if get_settings().is_local: batch_result_repository = providers.Resource(BatchResultLocalFileRepository) business_card_repository = providers.Resource(BusinessCardLocalFileRepository) else: batch_result_repository = providers.Resource(BatchResultRepository, get_settings().batch_result_s3_url_base) business_card_repository = providers.Resource(BusinessCardRepository) batch_result_service = providers.Factory(BatchResultService, repository=batch_result_repository) business_card_service = providers.Factory(BusinessCardService, repository=business_card_repository)
Webアプリ作成編
次のような要件を満たすページを作成します。
- ページのタイトルがある
- 類似人物を調べたい人を選択するselect boxがある
- selectboxで1人を選んだ後に検索ボタンを押す
- 検索ボタンが押されたら、APIを呼び出し、類似人物情報のリストを受け取る
- メインカラムに類似人物ネットワークを描画する
実装内容
Streamlit、ネットワークを描画するライブラリstreamlit_agraphを用いて実装します。
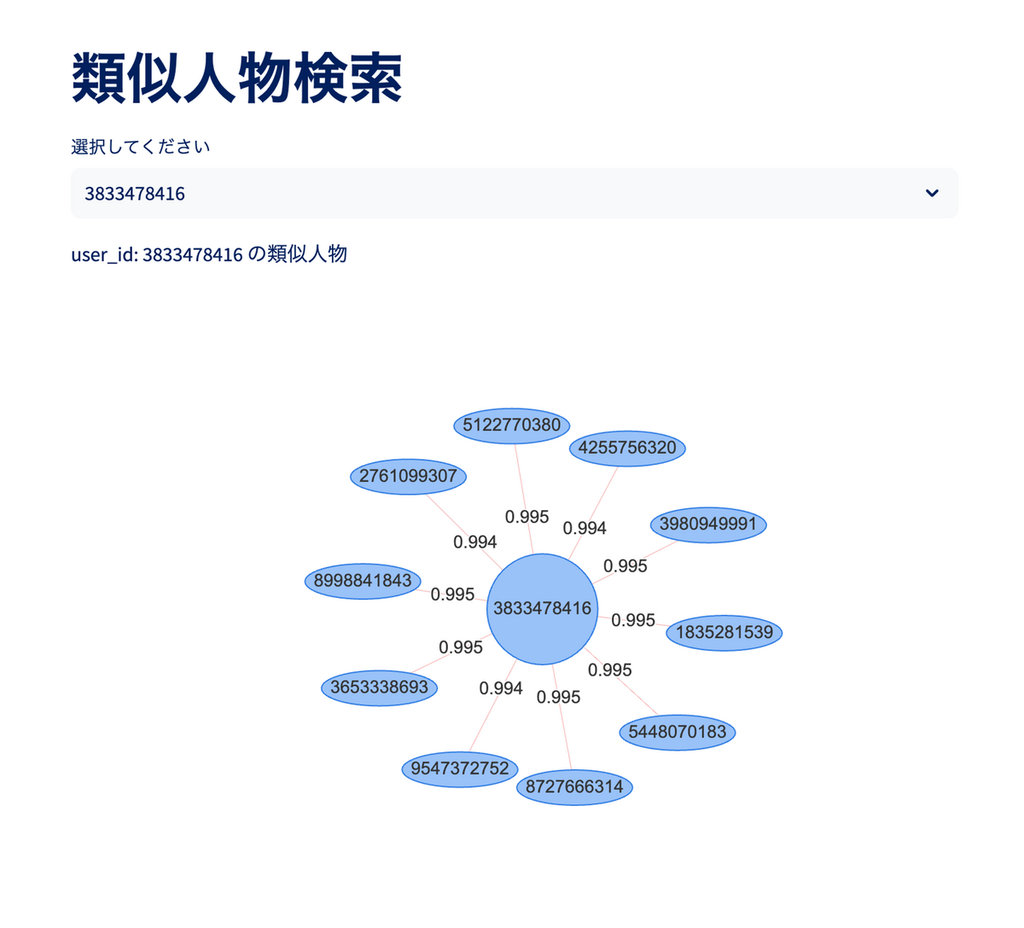
import os import requests import streamlit as st from streamlit_agraph import Config, Edge, Node, agraph BACKEND_HOST = os.environ.get("BACKEND_HOST", "http://api:8000") def get_persons() -> list[str]: response = requests.get(f"{BACKEND_HOST}/persons/?limit=100", timeout=10) return [result["id"] for result in response.json()] def search_similar_persons(person: str) -> list[dict]: response = requests.get(f"{BACKEND_HOST}/persons/{person}", timeout=10) return response.json() # タイトル st.title("類似人物検索") # 検索対象のユーザー群 persons = get_persons() # select box selected_user_id = str(st.selectbox("選択してください", set(persons))) # 検索ボタンが押された場合 similar_persons: list[dict] = search_similar_persons(selected_user_id) nodes = [] edges = [] st.write(f"user_id: {selected_user_id} の類似人物") # ネットワークの作成 nodes.append(Node(id=selected_user_id, label=selected_user_id, shape="circle")) for person in similar_persons: user_id = person["id"] similarity = str(round(person["similarity"], 3)) nodes.append(Node(id=user_id, label=user_id, shape="ellipse")) edges.append(Edge(source=selected_user_id, target=user_id, label=similarity)) # 描画の設定 config = Config( height=500, directed=False, physics=True, ) # 描画 agraph(nodes, edges, config)
次のようなページが描画されます。
追加課題
APIの追加課題で実装したエンドポイントを用いて、ネットワークのノードにidではなく人物名が描画されるように変更を加えます。
selectboxの候補を人物名で描画するために、APIとの通信部分を修正します。
@pa.check_types def get_persons_df() -> DataFrame[PersonSchema]: response = requests.get(f"{BACKEND_HOST}/v2/cards/?limit=100", timeout=10) return pd.DataFrame(response.json()) @pa.check_types def search_similar_persons(user_id: str) -> DataFrame[SimilarPersonSchema]: response = requests.get(f"{BACKEND_HOST}/v2/cards/{user_id}/similar", timeout=10) return pd.DataFrame(response.json())
PersonSchema、SimilarPersonSchemaは次のように定義します。
class PersonSchema(pa.SchemaModel): user_id: Series[str] = pa.Field(nullable=False) company_id: Series[str] = pa.Field(nullable=False) full_name: Series[str] = pa.Field(nullable=False) position: Series[str] = pa.Field(nullable=False) company_name: Series[str] = pa.Field(nullable=False) address: Series[str] = pa.Field(nullable=False) phone_number: Series[str] = pa.Field(nullable=False) class SimilarPersonSchema(PersonSchema): similarity: Series[float] | None = pa.Field(nullable=True)
@pa.check_typesアノテーションをつけることで、レスポンスのデータフレームのデータ型についてバリデーションをかけています。
全体の実装については、こちらをご覧ください。 github.com
最終的な出力結果は次のようになります。
まとめ
以上が研修の前編になります。 Pythonでサービス開発を行うパートはここで終わりです。 後編では、このサービスをDocker化し、社内のアプリケーション基盤にのせるパートを解説します。