3行で
- アクセスに基づいた推薦のために、文書のどのような情報を使うべきか考えた。
- ニュースの中の名詞、固有名詞、名詞×ジャンル、固有名詞×ジャンルの4つに分けて推薦を行い、ユーザーが興味を持ちそうなニュースを推薦できているかを定性的に確認した。
- 結果として、今回のデータ・手法では、下記3点が分かった。
- 名詞抽出による近傍探索で、ユーザー興味に沿ったニュースが推薦できる
- 固有名詞について、より上手な抽出方法を次の記事で検討する
- 推薦にジャンル情報を活用すると、うまく推薦できなかった場合でもユーザー興味を大幅には外さない推薦となりうる
目次
初めに
本記事は Sansan Advent Calendar 2021 - Adventar の 4 日目の記事になります。 こんにちは。 DSOC R&D グループの齋藤です。
最近ニュースのアクセスログにユーザー興味がどう反映されるか、について考える機会がありました。 例えば「イチロー選手が2000本安打達成」というニュースについてユーザーがアクセスしたとき、ユーザーの興味は「イチロー選手」でしょうか?「野球」でしょうか?それとも「スポーツ」というジャンルでしょうか?それともそれら全てでしょうか?
上記のニュースにアクセスしたユーザーがいた場合、アクセスログに基づいてユーザーにニュースの推薦を行う際にどのようなニュースを提示するのが良いのでしょうか?「イチロー選手」に関するニュースであればどのような内容でも推薦すべきでしょうか?それとも野球全般のニュースを推薦すべきでしょうか?
どのようなニュースを推薦すべきか、については発信媒体や設計思想に依る部分もあるため一概には言えませんが、文書中の何の情報を使うと、どのようなニュースが推薦されるのかを試すことはできそうです。
今回は、ユーザーが1つのニュースにアクセスしたと仮定し、どのような文書の要素を使うとどんなニュースが推薦されるのかをオープンなニュースデータセットを使って試してみます。
タイトルに(その1)とあるように、途中まで行った内容となっているため、後日(その2)を作成します。
実装
コードは全て下記のgithubに公開しています。gokartを用いており、ファイルの取得の部分を含めてpipeline化しているため誰でも再現可能(なはず)です。
手法
下記のような条件を設定しています。
- 文書中から特定の要素を抜き出し、ベクトルに変換し、その類似度を用いて似たニュースを推薦すると仮定します。
- データセットはLivedoorニュースコーパスを利用します。ニュースの収集時期は2012年9月上旬、ニュースの数は約7000です。
- データセットにはニュースのタイトルと本文があり、ベクトルに変換する際には本文のみを利用します。
- 文書は200次元のベクトルへと変換します。学習済みの分散表現として、日本語 Wikipedia エンティティベクトルの2017年2月1日版を利用します。ニュースの収集時期よりも後のため、ニュースに登場する固有名詞を含めた分散表現を多く学習していると考えています。
- 文書を200次元のベクトルへと変換する際には、各単語ベクトルの平均を取ります。
- 形態素解析にはSudachiPyを用い、分割モードCを利用します。
- テキストの前処理として、このコードを適用しています。
以降で具体的に説明していきます、
文書から抽出する要素を決める
抽出要素に関しては、論文A Dynamic Personalized News Recommendation System Based on BAP User Profiling Method (ZHU et al., 2018)を参考にします。
上記論文では、ニュース推薦におけるユーザープロファイル構築方法を提案しています。様々な方法が提案されていますが、その中の一つとしてニュースの「キーワード」「固有表現」「トピック」を抽出し、ユーザープロファイルを構築する方法が記載されています。
- 「キーワード」は、論文中では、ニュース内に登場した単語に対し、ニュース全体のでtf-idfの重みTop10を選んだものとされています。
- 「固有表現」は、特定の人物名などの固有名詞を表します。
- 「トピック」は、ニュースのトピック分布を表します。
この3つの情報に加え、
- 文書からシンプルに名詞のみを抽出したデータ(=「名詞」)
- 元々データセットに付与されているニュースのジャンルの情報(=「ジャンル」)
の5つを利用可能な情報候補として考えます。
整理すると、下記のようになります。
- 「名詞」
- 「キーワード」
- 「固有表現」
- 「トピック」
- 「ジャンル」
今回はこれらのうち、「名詞」「固有名詞」「ジャンル」の3つを利用します。「キーワード」「トピック」については次の記事でまとめます。
つまり下記のような組み合わせでの検証となります。
- 名詞
- 固有名詞
- 名詞×ジャンル
- 固有名詞×ジャンル
文書から要素を抽出する
名詞、固有名詞
- 形態素解析器にて、それぞれ「名詞」「固有名詞」と判別された単語を取得します。
ジャンル
- 今回のデータセットには、ジャンルとして下記の9つが与えられているため、それを利用します。
dokujo-tsushin it-life-hack kaden-channel livedoor-homme movie-enter peachy smax sports-watch topic-news
アクセスしたと想定するニュース
下記2つのニュースを想定します。
- 最強映画『アベンジャーズ』、歴代最速で『アバター』『ハリポタ』越え
- Google、最新プラットフォーム「Android 4.1 Jelly Bean」を発表!7...
上記二つのニュースのキーワードは「アベンジャーズ」、「Google」と考えられそうです。 そのため、シンプルにニュースタイトルに「アベンジャーズ」「Google」を含むものを確認してみます。
コードはgokartで書かれているため、classでの記載となります。
class CheckNewsTitleTask(GokartTask): def requires(self): return MakeTextLabelDataFrameTask() def run(self): df = self.load() logger.info(df['title'][df['title'].str.contains('アベンジャーズ')]) logger.info(df['title'][df['title'].str.contains('Google')]) self.dump('check news title task')
実行コマンドはpython main.py research_user_interest.CheckNewsTitleTask --local-schedulerです。
実行後、下記のような結果が得られます。
17 即完必至!『アベンジャーズ』BE@RBRICK付き鑑賞券を限定発売 22 “神失格の男”ソーが明かす「アベンジャーズは仲の悪い家族」 30 最強映画『アベンジャーズ』、歴代最速で『アバター』『ハリポタ』越え 31 “最強”が集結、『アベンジャーズ』ポスター画像が世界初解禁 136 『アベンジャーズ』が3週連続1位、ディズニー史上最高記録を達成 207 最強映画『アベンジャーズ』が『ダークナイト』『ハリポタ』越え 254 史上最強の映画『アベンジャーズ』の声優に“最強芸人”雨上がり・宮迫が決定 318 全米で1370万DLを記録、『アベンジャーズ』日本版予告編が遂に解禁 345 【終了しました】“最強”のヒーローが日本上陸!『アベンジャーズ』ジャパンプレミアにご招待 348 ありえないほど“最強”なヒーローが集結、『アベンジャーズ』日本版キャラクター画象が公開 402 全世界を席巻、最強“アベンジャーズ”現象が全米からヨーロッパへと拡大 439 映画『アベンジャーズ』の“最強”ヒーローがストラップに 468 先行上映が決定、ついに“アベンジャーズ現象”が日本上陸 783 “アベンジャーズ現象”日本上陸、早朝の六本木ヒルズに長蛇の列が出現 827 最強のハンマー×盾、『アベンジャーズ』本編映像を先行公開 842 世界はヒーローを待っている! 『アベンジャーズ』が、『ハリポタ』の記録を抜き快進撃 844 最強映画『アベンジャーズ』、“1日限定・数量限定”スペシャル前売券を発売 845 【週末映画まとめ読み】『アベンジャーズ』ワールドプレミアで日米最強女優がそろい踏み Name: title, dtype: object
884 MS Office互換、Google IMEも使える!イザというときのUbuntu環境構築ま...
890 Googleロゴが往年の料理研究家に!本日のGoogleロゴは有名な料理研究家の生誕100周年記念
944 何だこのおもちゃみたいなの? Googleロゴが子供のおもちゃみたいになっている理由
952 何だそうだったのか!Googleロゴがキノコになっている理由
1102 GoogleドライブのファイルをiPhoneからダイレクトに編集する【知っ得!虎の巻】
...
7305 Google、手書き入力検索をAndroidとiOSで提供開始!画面上に直接手書きして検索
7322 Google、最新プラットフォーム「Android 4.1 Jelly Bean」を発表!7...
7350 Google、Web解析サービス「Google Analytics」のAndroid向けアプ...
7352 Google、プリペイドカード「Google Playギフトカード」を正式発表!当初は米国内...
7369 Google、自社ブランドの7インチタブレット「Nexus 7」を発表!7月中旬発売予定で価...
Name: title, Length: 73, dtype: object
もし「”アベンジャーズ”」「”Google”」というキーワードのみに興味のあるユーザーであれば、上記ニュースを推薦する方法で問題なさそうです。 しかし、実際にはもっと多様なニュースが推薦されると体験として嬉しそうです。そのため、次からベクトルによる類似度を用いた方法を検討します。
名詞、固有名詞を抽出
形態素解析器の品詞を元に、名詞と固有名詞を抽出しました。 長いのでコードは割愛しますが、ここら辺で実施しています。SlothLibによるストップワード除去も行っています。
元文書と、名詞抽出後のlist、固有名詞抽出後のlistを一つだけ比較してみます。
- 元文書
4月25日より世界各国で公開され、29カ国で歴代記録を更新するなど驚異的な大ヒットを記録している映画『アベンジャーズ』。全米では5月4日に公開され、週末3日間で『ハリー・ポッターと死の秘宝 PART2』...
- 抽出された名詞
['世界', '各国', '公開', 'カ国', '歴代', '記録', '更新', '驚異的', '大ヒット', '映画', 'アベンジャーズ', '全米', '週末', '日間', 'ハリー', 'ポッター', '死', '秘宝', '0億0万', 'ドル', '興行収入', '勢い', '初', '登場', 'ティム', 'バートン', '監督', 'ジョニー',...
- 抽出された固有名詞
['ハリー', 'ポッター', 'ティム', 'バートン', 'ジョニー', 'デップ', 'シャドウ', 'アリス', '日本', 'ハリポタ', 'ヨーロッパ', '米倉', '涼子', 'スカーレット', 'ヨハンソン', '六本木ヒルズ']
名詞はほぼ意図通りに取れていることが分かります。0億0万となっているのはテキスト前処理の結果です。
固有名詞について、'アベンジャーズ'は固有名詞とラベリングされませんでした。どの品詞になっているか調べたところ普通名詞とラベリングされているようです。
$ echo "アベンジャーズ" | sudachipy アベンジャーズ 名詞,普通名詞,一般,*,*,* アベンジャーズ
更に、人の名前を切ってしまっているのが分かります。 OneNERのような固有表現抽出器を利用することでこのような固有名詞も抽出できる可能性があるかもしれません。次回試す予定です。
学習済みの分散表現がアクセスしたニュースのキーワードを含むかどうか
次に分散表現が今回のニュースに登場するキーワードを学習しているかについて簡単に確認をしてみます。
@inherits_config_params(MasterConfig) class CheckPretrainedVectorTask(GokartTask): model_path: str = luigi.Parameter() def requires(self): return GetPretarinedVectorTask() def run(self): model = gensim.models.KeyedVectors.load_word2vec_format( self.model_path, binary=True ) logger.info(model['アベンジャーズ']) logger.info(model['Google']) self.dump('check pretrained vector task')
上記をコマンドpython main.py research_user_interest.CheckPretrainedVectorTask --local-schedulerで実行すると
[ 0.17809798 -0.17465533 -0.06046956 0.35407922 -0.04886274 0.26800132 0.14857833 0.21419288 -0.3726769 -0.20762454 0.07942318 0.01252494 --中略-- -0.05156336 -0.07376201 -0.06714355 -0.13571593 -0.10208955 -0.12648079 -0.01399925 0.15706462]
[ 7.9320557e-02 -5.5103719e-01 -2.7100638e-01 1.7645934e-01 -1.5732516e-01 6.4829379e-01 1.6738310e+00 1.2328705e+00 --中略-- -3.1849390e-01 -1.2619349e-01 9.3402869e-01 -1.0642824e+00 1.2636782e-01 1.0439012e+00 -4.5183241e-01 -9.9771388e-02]
となり、'アベンジャーズ', 'Google'という単語については分散表現を持っていそうと確認できます。
抽出された分散表現のt-SNEによる可視化
抽出された名詞、固有名詞について、要素の全てを200次元のベクトルに変換し、そのベクトルを更にt-SNEで2次元へと変換し可視化します。

色付けされているのは今回のデータセットにおけるジャンルのため、t-SNE上でジャンルが分類がうまくいっていることが分かります。 またジャンル分類の観点では名詞を利用した方がより綺麗に分かれそうです。
名詞・固有名詞ともにある程度分類できており、ベクトル化の方法が大きく間違っていないことを確認できました。
類似度を元に推薦を行う
ここからがやりたいことです。これらの情報を用いて、特定のニュースをアクセスした状況を仮定し、どのようなニュースが推薦対象になるか確認します。 評価は定性的に行いますが、基準は「特定のニュースを読んだユーザーが興味を持ちそうなニュース」が上位に来ているかどうかで判断します。
近傍探索にはannoyを用います。距離にはコサイン類似度を指定します。
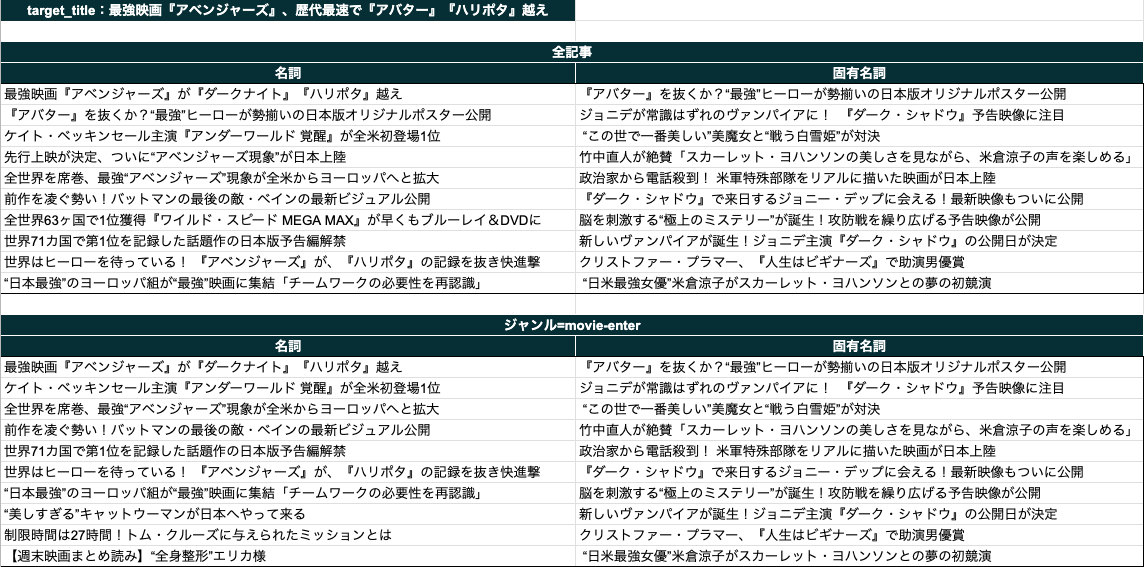
アクセスしたニュースが「最強映画『アベンジャーズ』、歴代最速で『アバター』『ハリポタ』越え」だった場合
名詞、固有名詞を用いた際に、annoyで推薦されるニュースのtop10は下記のようになります。
- 名詞の場合
最強映画『アベンジャーズ』が『ダークナイト』『ハリポタ』越え 『アバター』を抜くか?“最強”ヒーローが勢揃いの日本版オリジナルポスター公開 ケイト・ベッキンセール主演『アンダーワールド 覚醒』が全米初登場1位 先行上映が決定、ついに“アベンジャーズ現象”が日本上陸 全世界を席巻、最強“アベンジャーズ”現象が全米からヨーロッパへと拡大 前作を凌ぐ勢い!バットマンの最後の敵・ベインの最新ビジュアル公開 全世界63ヶ国で1位獲得『ワイルド・スピード MEGA MAX』が早くもブルーレイ&DVDに 世界71カ国で第1位を記録した話題作の日本版予告編解禁 世界はヒーローを待っている! 『アベンジャーズ』が、『ハリポタ』の記録を抜き快進撃 “日本最強”のヨーロッパ組が“最強”映画に集結「チームワークの必要性を再認識」
- 固有名詞の場合
『アバター』を抜くか?“最強”ヒーローが勢揃いの日本版オリジナルポスター公開 ジョニデが常識はずれのヴァンパイアに! 『ダーク・シャドウ』予告映像に注目 “この世で一番美しい”美魔女と“戦う白雪姫”が対決 竹中直人が絶賛「スカーレット・ヨハンソンの美しさを見ながら、米倉涼子の声を楽しめる」 政治家から電話殺到! 米軍特殊部隊をリアルに描いた映画が日本上陸 『ダーク・シャドウ』で来日するジョニー・デップに会える!最新映像もついに公開 脳を刺激する“極上のミステリー”が誕生!攻防戦を繰り広げる予告映像が公開 新しいヴァンパイアが誕生!ジョニデ主演『ダーク・シャドウ』の公開日が決定 クリストファー・プラマー、『人生はビギナーズ』で助演男優賞 “日米最強女優”米倉涼子がスカーレット・ヨハンソンとの夢の初競演
名詞について、全てのニュースがユーザー興味と関係ありそうに感じます。 固有名詞について、'アベンジャーズ'を固有名詞として取得していないため該当映画関連のニュースは上位に来ませんが、映画周りのニュースが上位に来ており、こちらも良さそうです。
上記の要素に対して、同じジャンル内でのニュースに限定すると、下記のようになります。
- 名詞の場合
最強映画『アベンジャーズ』が『ダークナイト』『ハリポタ』越え ケイト・ベッキンセール主演『アンダーワールド 覚醒』が全米初登場1位 全世界を席巻、最強“アベンジャーズ”現象が全米からヨーロッパへと拡大 前作を凌ぐ勢い!バットマンの最後の敵・ベインの最新ビジュアル公開 世界71カ国で第1位を記録した話題作の日本版予告編解禁 世界はヒーローを待っている! 『アベンジャーズ』が、『ハリポタ』の記録を抜き快進撃 “日本最強”のヨーロッパ組が“最強”映画に集結「チームワークの必要性を再認識」 “美しすぎる”キャットウーマンが日本へやって来る 制限時間は27時間!トム・クルーズに与えられたミッションとは
- 固有名詞の場合
『アバター』を抜くか?“最強”ヒーローが勢揃いの日本版オリジナルポスター公開 ジョニデが常識はずれのヴァンパイアに! 『ダーク・シャドウ』予告映像に注目 “この世で一番美しい”美魔女と“戦う白雪姫”が対決 竹中直人が絶賛「スカーレット・ヨハンソンの美しさを見ながら、米倉涼子の声を楽しめる」 政治家から電話殺到! 米軍特殊部隊をリアルに描いた映画が日本上陸 『ダーク・シャドウ』で来日するジョニー・デップに会える!最新映像もついに公開 =脳を刺激する“極上のミステリー”が誕生!攻防戦を繰り広げる予告映像が公開 新しいヴァンパイアが誕生!ジョニデ主演『ダーク・シャドウ』の公開日が決定 クリストファー・プラマー、『人生はビギナーズ』で助演男優賞 “日米最強女優”米倉涼子がスカーレット・ヨハンソンとの夢の初競演
・・・あんまり変わりませんね🤔 ベクトルでの近似探索によりジャンルがほぼ近いニュースを抽出できていた、ということが分かります。
アクセスしたニュースに対する推薦の結果
「Google、最新プラットフォーム「Android 4.1 Jelly Bean」を発表!7...」も同様に試した結果を下記のように表でまとめました。赤文字はユーザー興味とは明らかに外れているニュースを表しています。

Googleのニュースについて、固有名詞のみでの類似(画像「Googleの類似ニュースtop10」右上)ではユーザー興味と関係ないニュースに多くなってしまいました。一方ジャンルで絞った場合(画像「Googleの類似ニュースtop10」右下)では関係ありそうなニュースが上位に来ています。
このことから映画関連のニュースは類似ニュースが取得しやすかったこと、またGoogleのニュースのように類似ニュースの候補が多い場合はジャンルの情報も活用するとユーザー興味を大幅には外さない、ということが分かります。
まとめ
今回のデータ・手法では下記のことが分かりました。
- 名詞による抽出で、ユーザー興味に沿ったニュースは推薦できる
- 固有名詞をよりうまく抽出すると推薦を改善できる可能性がある
- ジャンルの情報も活用すると、うまく推薦できなかった場合でもユーザー興味を大幅に外さない推薦となりうる
また、今回は1つのニュースのみにアクセスした仮定で話を進めていますが、実際には複数ニュースのアクセスが想定できます。 複数ニュースにアクセスがあった場合にどう推薦すべきかについても今後検討していきます。
次回以降やりたいこと
- キーワードの考慮
- 固有名詞をより上手に抽出する
- トピック分布の考慮
- アクセスしたニュースを複数にした場合に推薦すべき内容
最後に
疑問点やおかしいところあったらぜひ教えてください。コメントやTwitterで教えてくれるとありがたいです。
Twitterアカウントはこちら