 技術本部 研究開発部 Architectグループの島です。
技術本部 研究開発部 Architectグループの島です。
前回の記事の続きで、完結編です。Sansan内製の名刺OCRである「NineOCR」の基盤を改良します。 buildersbox.corp-sansan.com
筆が進まないまま前編から1年経ちそうで慌てて書いている次第ですが、そうこうしているうちに、実は更に新しいシステム構成にする話が挙がってきまして、なんとかその前に話を完結させておきます。あくまで取り組んだ当時の判断として開発した内容を以下ご紹介します。
新しい構成
前編ではGoogle CloudかつCompute Engineを使い続けるという結論への過程を述べました。新システムにより運用の課題を丸ごと葬るというおいしいルートは封じられてしまったため、「穏健に」どう改善するか頭を悩ませました。長い試行錯誤がありましたが、結論だけ以下に述べていきます。
マネージド インスタンス グループ (MIG) によるローリングアップデート
前編でも紹介した、従来のシステム構成図を再掲します。
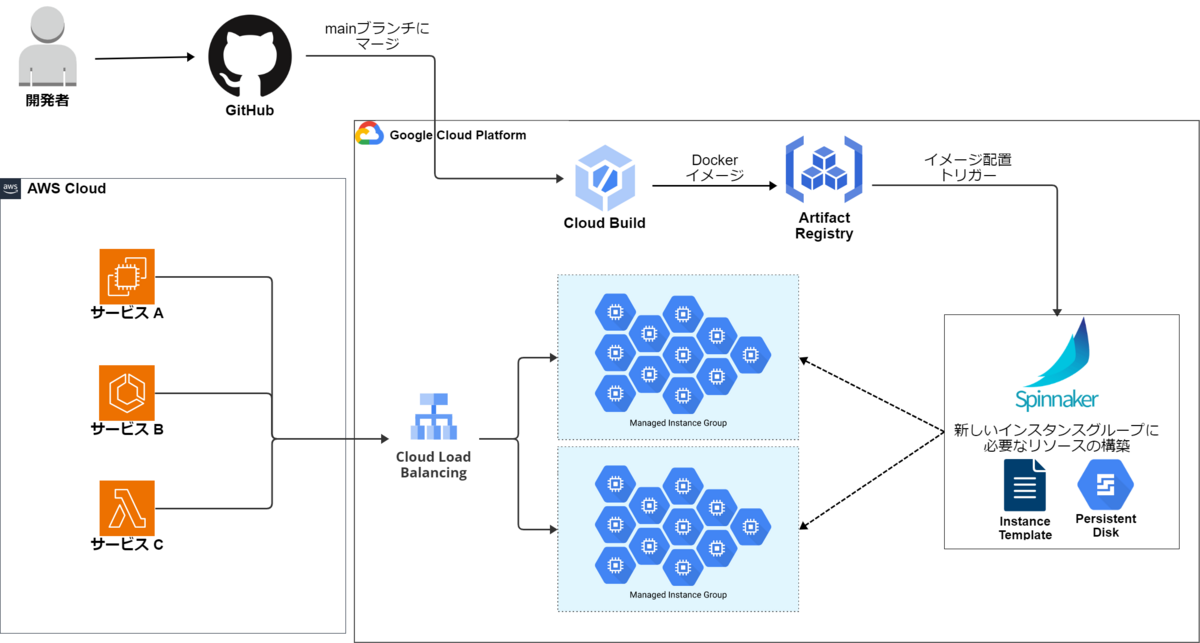
ここでポイントになるのは以下です。
- デプロイ時にMIGを新旧2系統用意し、トラフィックを切り替えていく
- MIGの生成・破棄・トラフィック切り替え、インスタンスのディスク更新等の制御をSpinnakerで行う
このMIGを2系統用意するのが複雑さの一因です。前編にてSpinnakerを退役させたい旨を書きましたが、別の何かに移行するにせよ結局制御を自前で書いていては大差ありません。トラフィック切り替えをほぼノーコードでらくちんにやってくれる何かを追い求めました。
結果として、以下のようになりました。*1
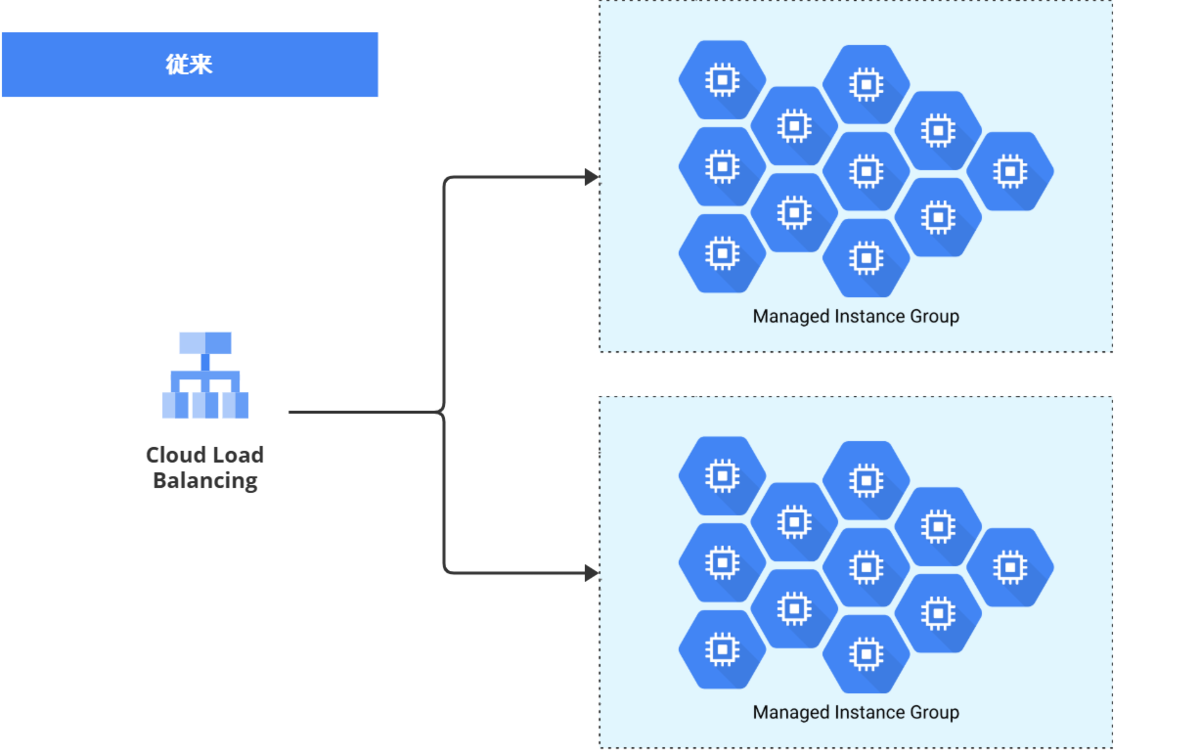
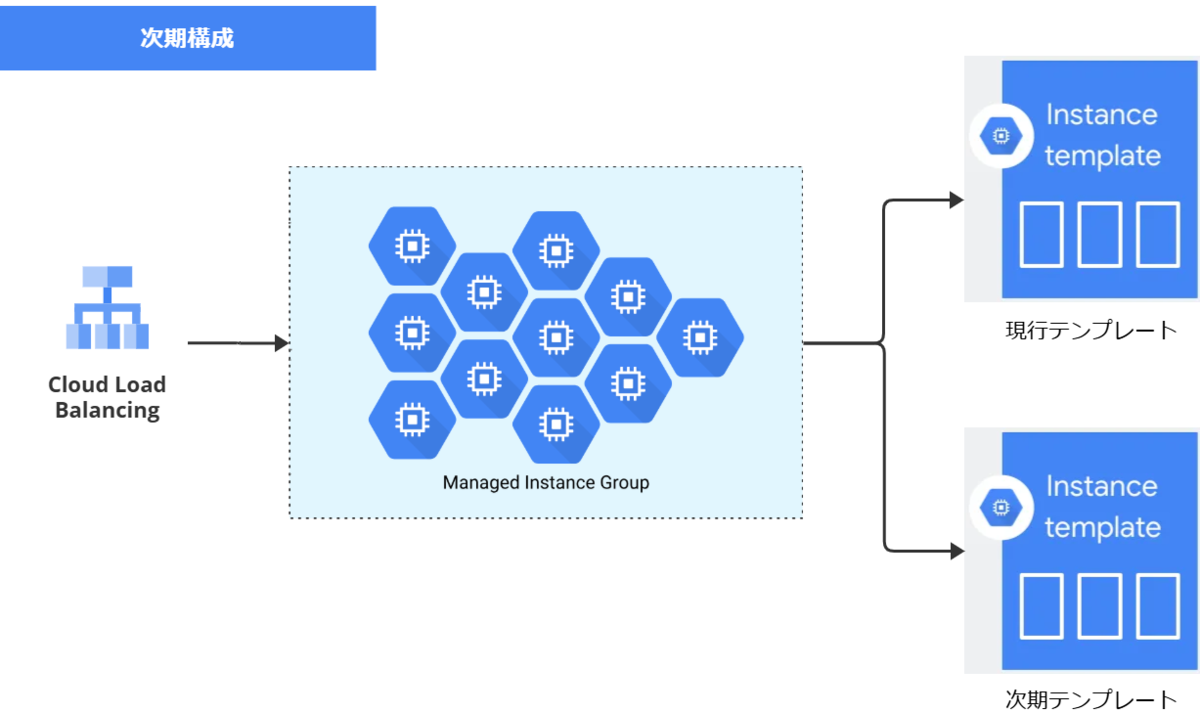
そう、MIGは2個作らなくて良かったのです!MIG自身に、ローリングアップデートのサポートが含まれていました。灯台下暗し。*2
MIG自体を2個作るのではなく、MIGに関連付ける インスタンステンプレート を新旧2種類用意する、と変更することにしました。インスタンステンプレートとは、どのようなインスタンスを立ち上げるかの設計図情報です。MIGに登録してあるテンプレートを旧版から新版へ差し替えるだけで、実際のインスタンスのローリングアップデートはMIGの機能にお任せできます。
カナリアリリースやロールバックも簡単です。以下は、Google Cloudのコンソールにてカナリアリリースを設定する例で、2つのインスタンステンプレートをMIGに登録してそれぞれの稼働台数(パーセント)を設定しています *3。
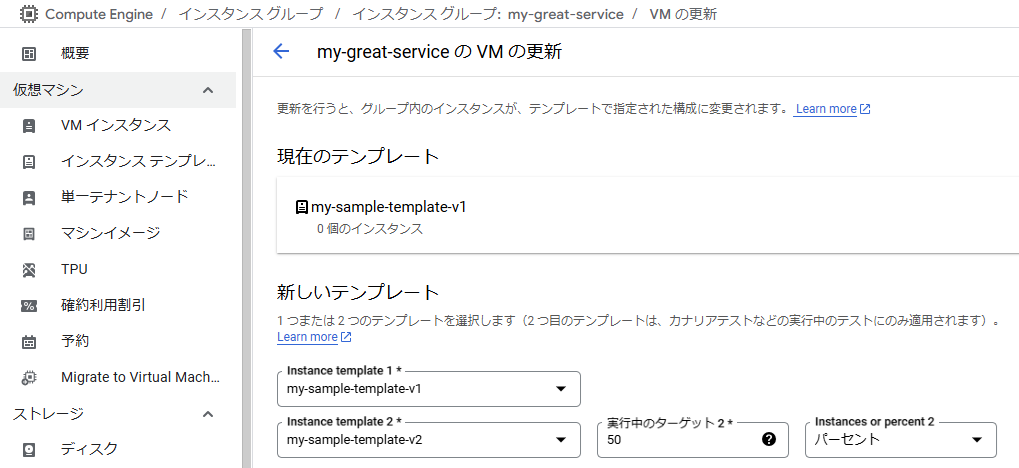
MIGが1つで済むようになったことは、リリースの際に立ち上がるインスタンス数の削減にもなりました。普段インスタンス50台で稼働しているとして、MIGを一時的に2つ用意すると計100台が立ち上がってしまいます。本サービスのインスタンスはアクセラレータとしてNVIDIA T4を使用するのでよりコストがかさみますし、そもそもGPUの確保に失敗する恐れもあります *4。1つのMIGの中でVMの更新をするよう改めることで、置換戦略にもよりますが数台分程度しか追加の稼働をせずに済みます。
以上によって、Spinnakerで苦労していた制御の多くをMIGに移譲することができました。デプロイは「新しいインスタンステンプレートさえちゃんと作れたら良い」という話に単純化できました。次はその話に移ります。
インスタンスは Container-Optimized OS (COS) で構築
課題
従来構成の課題はもう1つあり、それが個別のインスタンス内部の構築です。
「デプロイはインスタンステンプレートを差し替えること」と申しました。この点については従来から変わりありません。インスタンステンプレートに含まれる情報のうち、マシンタイプ、サービスアカウント等々ほとんどの設定は、デプロイの前後で大抵変更されません。変わるのはほぼディスクの中身だけです。ディスクの中に置くアプリケーションデータを差し替えて新規ディスクとして登録し、そのディスクをインスタンステンプレートに紐づけて登録する、という流れとなります。
今回のアプリケーション(NineOCR)はPython製のWebAPIで、DockerイメージとしてArtifact Registryに配置されているものとします*5。GitHub経由でCloud Buildが発動してdocker buildとpushがなされ、Artifact Registryへと配置されます。この後の話をします。
従来、ディスクのOSにはDebianを使用し、中は以下の手順で設定していました。
- 現行版サービスのディスクのコピーを取り、それを起点に設定開始
- ディスクを空けるためデータのお掃除
- aptによるパッケージの更新
- GPU関連のドライバやCUDA等の更新を含む
- Datadogエージェントのインストール
- セキュリティソフトウェアのインストール
- Artifact Registryからアプリケーションのコンテナイメージを取得し、docker run
- スリープしたりダミーリクエストを自身に投げるといった暖機運転をしながら、WebAPIのヘルスチェックが成功するまで待つ
なかなか大変です。この手続きはシェルスクリプトにして1000行以上あり、Spinnakerのワークフローの一部として含まれていました。以下の課題がありました。
- 前バージョンのディスクのコピーを取るという「秘伝のたれの継ぎ足し方式」による課題
- 秘伝のたれを一から作り直すような事態(OSのバージョンアップ等)への対処は困難です。たまにしか起きないので誰も覚えていないこと、中途半端に自動化されていることが要因です(いっそ全部手作業の方がこの点は楽)。
- どうしても次第にディスク容量が増えがち*6で、忘れた頃に突然容量を超過しデプロイ不能になります。これもまた覚えていない中で緊急対応を強いられる重い手作業となり、復旧が結構大変です。
- 環境構築のシェルスクリプトの保守に苦労します。「Datadogエージェントのバージョンを上げたい」のような保守作業はどうしてもたまに発生し、手を入れるのに苦労します。そしてそもそもこのシェルスクリプトがSpinnakerインスタンス内で点在していて、どこをいじればいいのかよくわからないという問題も起きていました。
COSによるインスタンス定義
上で述べたようなイメージ初期設定を極力丸投げして、アプリケーションのDockerコンテナだけに注力できれば最高です。結論として、Container-Optimized OS (COS) を使うことでその理想に近い状態を実現できました。
COSについては以下の公式ドキュメント等をご参照ください。大雑把に言えば、「ファイルシステムが基本readonlyで、ほぼdocker runしかできない」OSです。
実際の設定方法はこちらなどが参考になります。以降で実際の活用例を示していきます。
インスタンステンプレートの作成
先にインスタンステンプレートの作成方法を示します。本案件ではgcloudコマンドを使用しました。CI/CD (Cloud Build) から実行されます。
# 日時+gitコミットハッシュ値 でイメージタグ名を決める YYYYMMDD=$(TZ=UTC-9 date '+%Y%m%d') HHMMSS=$(TZ=UTC-9 date '+%H%M%S') SHORT_SHA=$(git rev-parse --short HEAD) gcloud compute instance-templates create \ my-great-service-${YYYYMMDD}-${HHMMSS}-${SHORT_SHA} \ --project=${PROJECT_ID} \ --region=asia-northeast1 \ --machine-type=n1-standard-4 \ --network-interface=subnet=my-subnet,no-address \ --maintenance-policy=TERMINATE \ --provisioning-model=STANDARD \ --service-account=my-great-service@${PROJECT_ID}.iam.gserviceaccount.com \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --accelerator=count=1,type=nvidia-tesla-t4 \ --region=asia-northeast1 \ --min-cpu-platform="Intel Skylake" \ --boot-disk-size=20GB \ --boot-disk-type=pd-balanced \ --no-shielded-secure-boot \ --shielded-vtpm \ --shielded-integrity-monitoring \ --reservation-affinity=any \ --image-family=cos-stable \ --image-project=cos-cloud \ --metadata=google-logging-enabled=true,google-monitoring-enabled=true \ --metadata-from-file=user-data=cloud-init.txt
gcloud compute instance-templates createコマンドの各パラメタについてはドキュメントをご参照ください。ここではCOS関連のパラメタを最下部に置きました。--image-family=cos-stable によりCOSのディスクが作られます。*7
COSのインスタンスを立ち上げてSSHで入ってみると実感できますが、びっくりするくらい何もできません。COSインスタンスの初期設定をするためには、cloud-config形式によるcloud-initを使用します。--metadata-from-file=user-data=cloud-init.txt の指定はそれを示していて、cloud-init.txt の中にインスタンスの初期設定を書きます。その説明に移ります。
cloud-init
cloud-initの設定方法については、前述のドキュメント等を参考にします。今回はcloud-init.txtの中身を以下のようにしました。
#cloud-config
timezone: Asia/Tokyo
locale: en_US.UTF-8
users:
- name: myservice
uid: 2000
write_files:
- path: /etc/systemd/system/install-gpu.service
permissions: 0644
owner: root
content: |
[Unit]
Description=Install GPU drivers
Wants=gcr-online.target docker.socket
After=gcr-online.target docker.socket
[Service]
User=root
Type=oneshot
ExecStart=cos-extensions install gpu
StandardOutput=journal+console
StandardError=journal+console
- path: /etc/systemd/system/my.service
permissions: 0644
owner: root
content: |
[Unit]
Description=My Great Service
Requires=install-gpu.service
After=install-gpu.service
[Service]
User=root
Type=oneshot
RemainAfterExit=true
Environment="HOME=/home/myservice"
Environment="IMAGE=asia-northeast1-docker.pkg.dev/PROJECT_ID/my-docker-repository/my-great-service:@DOCKER_IMAGE_TAG@"
ExecStartPre=/usr/bin/docker-credential-gcr configure-docker --registries asia-northeast1-docker.pkg.dev
ExecStartPre=/bin/mount --bind /var/lib/nvidia /var/lib/nvidia
ExecStartPre=/bin/mount -o remount,exec /var/lib/nvidia
ExecStart=/usr/bin/docker run --rm -u 2000 --volume /var/lib/nvidia/lib64:/usr/local/nvidia/lib64 --volume /var/lib/nvidia/bin:/usr/local/nvidia/bin --device /dev/nvidia0:/dev/nvidia0 --device /dev/nvidia-uvm:/dev/nvidia-uvm --device /dev/nvidiactl:/dev/nvidiactl -p 80:8080 ${IMAGE}
StandardOutput=journal+console
StandardError=journal+console
runcmd:
- systemctl daemon-reload
- systemctl start install-gpu.service
- systemctl start node-problem-detector
- systemctl start my.service
GPUを利用するアプリケーションの設定が結構難しいです。特にdocker runの付近にある長大な記述はほぼおまじないと捉えてもよいかもしれません。Dockerイメージタグの指定の部分はテンプレート的にしており、最後にCI/CDにて穴埋めします。
sed -e s/@DOCKER_IMAGE_TAG@/${COMMIT_SHA}/ \ cloud-init-template.txt | tee cloud-init.txt
サービス起動 (docker run) の前準備として重要なのがGPUドライバのインストールです。COSでは非常に簡単で以下コマンド一発で終わります (参考)。
sudo cos-extensions install gpu
以上で完成です!従来と異なり、毎度まっさらなCOSインスタンスから環境構築するため、秘伝のたれ方式で起きていた問題はほぼ回避できます。
余談ですが、もしGPUを使用しないアプリケーションの場合はこの手引き等に従った方が簡単かもしれません:
VM と MIG へのコンテナのデプロイ | Compute Engine Documentation | Google Cloud
完成後の感想・まとめ
MIGが想像以上に高機能で、多くの課題を解決してくれました。並行して他案件で導入を進めたCloud Runとあわせ、個人的にGoogle Cloudを好むようになった転換点となりました。
前編で述べたように保守への課題から始めたことなので、あまり自前で凝ったことをしないようにしました。この点は大変成功だったと思います。Google Cloudの便利なマネジメントサービス (MIGとCOS) にうまく乗っかることができました。システム構成は単純化され、コード量は1/10近くまで圧倒的に削減され、かつ全てGit管理に含められた *8 ため、将来にわたってメンテナンスしやすくなりました。
新しいデプロイの流れ
本記事で対象にしたサービス(NineOCR)は普段我々Architectメンバーではなく研究員メンバーが開発・作業することが圧倒的に多いです。MIG上でのVM更新については、ボタン一発で開始できるといった何らかのインターフェイスを用意するかどうか迷ったものの、結局Google Cloudコンソールを直接触ってもらう形で実施してもらうことにしました。100点満点の間違いない選択とはとても言えないのですが、一番マシな選択だったと捉えています。VM更新はパラメータやモード・取り得る状態の数が大変多くて、独自インターフェイスを挟むとサポートが行き届かない恐れがありました。かといってgcloudコマンド ( gcloud compute instance-groups managed xxx ) を実行してもらうのもハードルが高いように思われました。スクリーンショットを添えた操作マニュアルを用意しており、今や研究員たちで自主的にVM更新を行えています。
最終的に、デプロイシステムは研究員メンバーにとっては以下のような使い心地になっています。3. のトラフィック切り替えについてはどうしても人間の判断を要すところがあり、必要十分な自動化具合になったと捉えます。
- 当サービスのGitHubリポジトリにて、pull requestをmainブランチにマージ。
- Cloud Buildが起動:
- mainブランチの状態にてDockerイメージをbuildし、Artifact Registryにpush。
- Artifact Registryのイメージを参照するかたちでインスタンステンプレートが作成される。
- 研究員メンバーがGoogle CloudコンソールからMIGの設定画面を開き、新しいインスタンステンプレートへと置き換えるよう「Update VMs」を実行する。
今後
Compute Engineで、かつ必要最小限でと限定した場合、割と到達点に来たのではと考えていますが、もちろん他の構成の可能性も常にアンテナを張っております。Kubernetesベースの基盤の検討や、Vertex AIのオンライン予測エンドポイントの活用です。また進展があれば記事にするかもしれません。
注意:COSのバージョン・自動更新について
最後に注意点として、COSのバージョン関連について挙げておきます。以下が参考になります。
本記事では、インスタンステンプレートの作成にて --image-family=cos-stable という引数を指定しました。この cos-stable は、記憶している限り2023年後半頃においては最も無難な指定であり、当時LTS版は存在しなかったはずですが、2025年現在は cos-117-lts というようにバージョンを明示したLTS版を使う方が本番運用向けには望ましいようです。本記事では取り組み当時のまま cos-stable として記載しました。
COSのバージョンの自動更新についても、長らくデフォルトで有効でしたが、つい最近のマイルストーン117から既定で無効になりました(参考)。従って、cos-XXX-lts という指定を今後行うにあたっては、少なくとも2年に1回はCOSバージョンを明示的に上げて指定しなおすことが求められます。
逆に言えば cos-stable かつ自動更新ONにしておけば、とりあえずはメンテナンス不要で放置できそうに思えます。つい最近までのデフォルトはこの仕様でしたし、楽ですからそれでいいやと考えてしまいますが、リスクは理解する必要があります。というか最近問題を踏んでしまいました。
COS向けGPUドライバのインストール失敗事例
前述の通り、sudo cos-extensions install gpu というコマンド一発でGPUドライバのインストールが完了します。この処理では、リージョンによりますが gs://cos-tools-asia/ というGoogle Cloudが管理する一般公開のStorageバケットから必要なドライバ類を入手するようになっています。中はCOSのバージョンによってフォルダが切られており、例として gs://cos-tools-asia/18613.75.89/nvidia-drivers-535.104.05.tgz というようなパスからドライバが取得されます。
先日我々が踏んでしまった問題は、「このStorageの宛先がNotFoundのため、GPUドライバインストールに失敗し、新規インスタンスが一切立ち上がらない」というものでした。なぜ急にそうなったかといえば、COSのバージョンが自動的に上がった、かつ、Google側の問題でたまたまそのCOSバージョンに対応するGPUドライバが未配置だった というのが原因とみています。
サポートに問い合わせしつつ、ほどなくドライバファイルがStorageに配置されて事なきを得ました。cos-stable を使いかつ自動更新している以上はあまり文句は言えないのだと考えており、この点からも、自分たちでも動作検証したLTS版のCOSを長期間固定して使い続けるのが良いということになります *9 。COSはCompute EngineのみならずGKEでも基盤となる技術ですから、GKEをお使いの方々も留意されると良いと思います。
*1:MIGやインスタンステンプレートの定まったアイコンが無いようで、ご容赦ください。
*2:AWSの場合、EC2のオートスケーリンググループあたりにこのような機能は無いと思いますので、発想に至らずノーマークでした。
*3:カナリアというには割合が多い (50%) 図になっていますが。
*5:本案件の作業をしている頃はGCR (Google Container Registry) が現役でしたが、本記事ではGARとして話を単純化します。
*6:apt-get upgradeが主要因に思われます。
*7:cos-stable という指定の是非は、本記事の最後に述べます。
*8:従来Spinnakerインスタンス内にあったスクリプトファイルはバージョン管理されていませんでした。
*9:後から gs://cos-tools-asia/ のデータが消されてしまう可能性は考えないものとします。