Bill One 開発 Unit ブログリレー2024の第4弾になります!

こんにちは。技術本部 Bill One Engineering Unitの向井です。
Bill Oneは急速にサービスの規模を拡大しており、それにあわせてトラフィックやデータ量も急激に増加しています。 特にサービスのローンチから最も長い歴史をもつ請求書受領の機能はこの傾向が顕著であり、さまざまな問題が発生しています。
そのひとつがデータベースのパフォーマンスです。 サービスのローンチからしばらくの間は、主に参照系のクエリにおいてパフォーマンス問題が発生していました。 この問題に対してはスロークエリにひとつずつ対処することで解消してきました。
しかし、最近は傾向が変わってきました。 参照系のクエリの性能は比較的安定しているものの、更新系のクエリでピークタイムにパフォーマンス問題が発生するようになりました。
この内容は次のイベントでも共有させていただいたのですが、より詳しくご紹介します。なお、本記事はSansan Advent Calendar 2024の9日目の記事です。
発生した事象
Bill Oneはマイクロサービスアーキテクチャを採用しています。 そして、各マイクロサービスは基本的にはアプリケーション基盤としてCloud Run*1を、データストアにはCloud SQL for PostgreSQL*2を採用しています。
発生した事象は前述の通り、ピークタイムに一部の更新系のクエリで負荷が集中したタイミングにパフォーマンスが悪化するというものでした。 問題が発生した請求書受領の機能は月初にリクエスト数がピークを迎えるため、このタイミングで発生する傾向がありました。
Bill Oneでは非同期イベントの発行にTransactional Outboxパターンを採用しており、イベントの発行を保証する仕組みはデータベースに依存しています。 具体的には、次の流れでイベントを処理することでイベントが確実に発行されることを保証しています。
- あるトランザクション内でイベントが発生すると、その処理の最後で「イベント発行予約テーブル」にイベントの内容を書き込む
- トランザクションを閉じたあとで、Cloud Tasksのタスクを発行し、イベントが発生したことを自身(同じアプリケーション)に通知する
- イベント発生の通知を受け取ると、別のトランザクション内で次の処理を実行する
- イベント発行予約テーブルから「イベント発行済テーブル」へのレコードの移し替え
- イベントの内容に応じた処理を実行するためのメッセージをCloud TasksやCloud Pub/Subに発行する*3
- イベントメッセージを受け取ったアプリケーションが処理を実行する
今回の話の本質からは外れますが、2をトランザクション外で実行しているのは、Cloud TasksのAPIエラーが発生したときにユーザーの操作を失敗させないためです。 イベント発行予約テーブルは処理が順調に進んでいればレコードが存在しないはずなので、定期的にテーブルを監視することでユーザー体験と安定性の両立を狙っています。
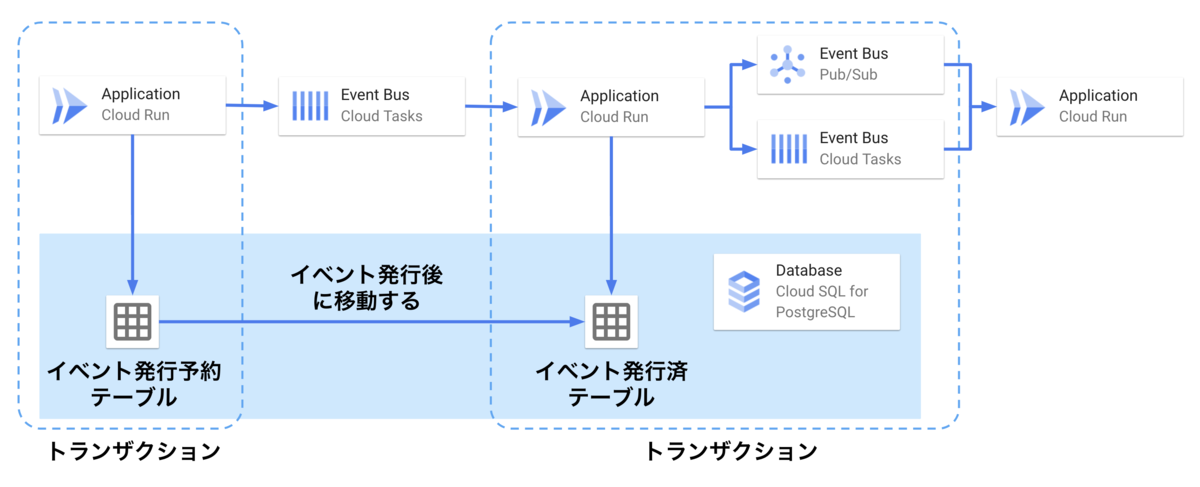
今回の問題が発生したクエリには、このイベント発行済テーブルも含まれており、非同期イベントの処理遅延が問題発覚の起点となりました。
パフォーマンス劣化の原因調査
今回の問題が発生したデータベースには次の特徴がありました。
- データベースはCloud SQL for PostgreSQLを採用している
- インデックスは基本的にB-Tree Indexを使用している
- 各テーブルの主キーは基本的にUUID v4を使用している
また、すべてのテーブルの物理サイズを合計すると数百GB程度あり、インデックスは単体で数十GB程度のものがありました。 それぞれのサイズは次のクエリで確認できます。
-- テーブルのサイズ SELECT objectname, PG_RELATION_SIZE(objectname::regclass) AS bytes, PG_SIZE_PRETTY(PG_RELATION_SIZE(objectname::regclass)) AS display_bytes FROM (SELECT tablename AS objectname FROM pg_tables WHERE schemaname = :schema) AS objectlist ORDER BY bytes DESC; -- インデックスのサイズ SELECT objectname, PG_RELATION_SIZE(objectname::regclass) AS bytes, PG_SIZE_PRETTY(PG_RELATION_SIZE(objectname::regclass)) AS display_bytes FROM (SELECT indexname AS objectname FROM pg_indexes WHERE schemaname = :schema) AS objectlist ORDER BY bytes DESC;
Cloud Runに対する調査
まずはアプリケーションがボトルネックになっていないかを調査しました。 リクエスト数がピークとなる月初と、相対的に少ない月中のHTTPメソッドごとのレイテンシを比較したのが次の図です。
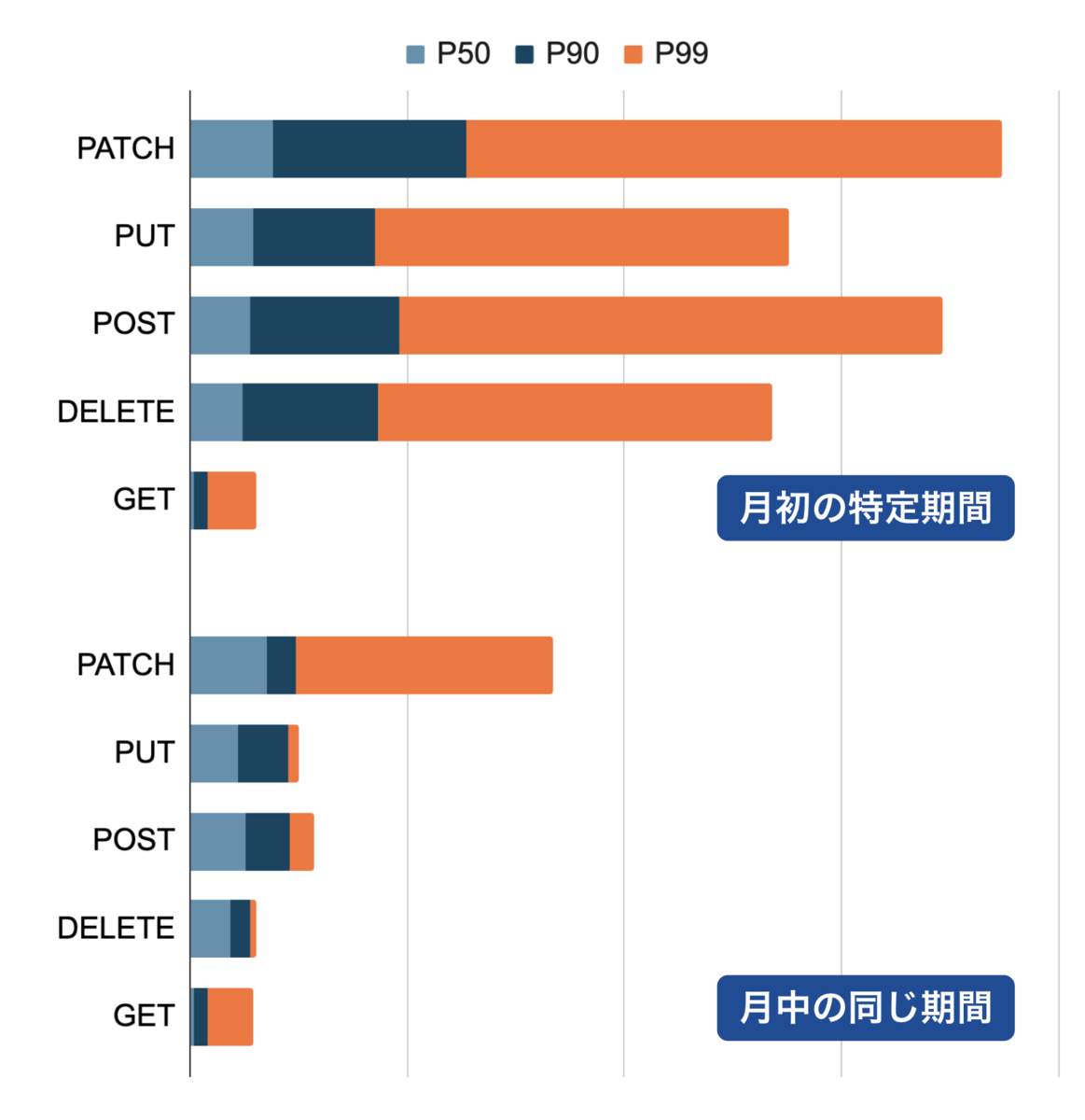
GETには大きな変化はないものの、その他のデータベースへの書き込みが発生しうるHTTPメソッドではレイテンシが大きくなっていました。
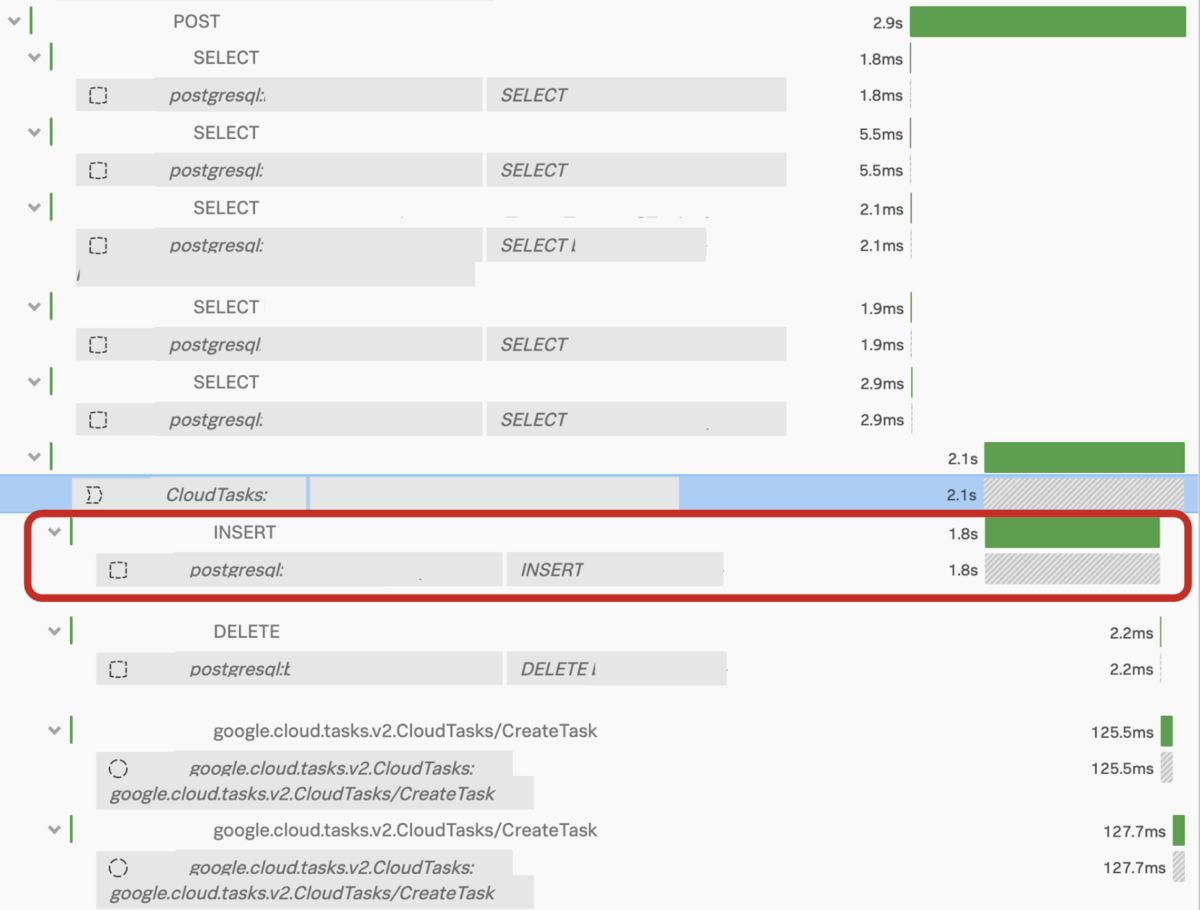
そこで、特にレイテンシの悪化が顕著なAPIを探すと、非同期イベントの処理で使用しているイベント発行済テーブルへの書き込み性能が特に悪化していました。 Bill Oneではマイクロサービス環境における分散トレーシングや、アプリケーションのメトリクスをSplunkに集めることで調査に利用できる環境を整備しています。 次の図はSplunkでアプリケーションの処理時間の流れを可視化したものです。 イベント発行済テーブルへのINSERTに大きく時間がかかっていることがわかりました。
Cloud SQLの調査
イベント発行済テーブルへの書き込みに時間がかかっていることがわかったので、次にデータベースのメトリクスを確認します。 次のクエリでインデックスごとのキャッシュヒット率を出します。 *4
SELECT i.relname, i.indexrelname, (idx_blks_hit - idx_blks_read)::numeric / idx_blks_hit AS ratio FROM pg_statio_user_indexes i WHERE idx_blks_hit != 0 ORDER BY i.relname, i.indexrelname;
すると次の結果が得られ、イベント発行済テーブルのPrimary Keyのキャッシュヒット率が特に悪いとわかりました。
| relname | indexrelname | ratio |
|---|---|---|
| イベント発行済テーブル | インデックス A (Primary Key) | 0.6018625336 |
| イベント発行済テーブル | インデックス B | 0.7935121353 |
| テーブル A | インデックス C | 0.8842985261 |
| テーブル B | インデックス D | 0.9144033732 |
| テーブル C | インデックス E | 0.9233941076 |
キャッシュヒット率低下の原因
キャッシュヒット率が下がっていたインデックスは、UUID v4の値を保存するUUID型のカラムに対するB-Treeインデックスとして構成されています。 また、このテーブルは非同期イベントの発行処理に使用していますが、発行後のイベントしか記録しないため、SELECTは実行されず常にINSERTのみが実行されるテーブルでした。 加えて、ログのような位置づけでデータが蓄積されるため、すべてのテーブルの中で最もレコード数が多いテーブルでもありました。
B-Treeインデックスは木構造となっており、末端部分に値がソートしてブロックごとに保存される仕組みとなっています。 このインデックス対象のカラムの値にはUUID v4を使用していたため、大量の書き込みを実行するにはインデックスの多くのブロックをインデックス再構築のためにキャッシュする必要があります。
しかし、Bill Oneは読み込みの処理のほうが多かったために、書き込みにしか使用しないインデックスはメモリに配置されにくく、結果としてキャッシュヒット率の低下を招いたものと考えられます。
対策の検討
パフォーマンス問題の原因がデータ構造の特性によるキャッシュヒット率の低下とあたりをつけたので、次の対策を実施しました。
- テーブルのデータ量を削減する
- UUID v7やULIDなどの時系列でソート可能なIDをPrimary Keyに使用する
現時点では採用しなかった案も含めて、実装コストとメリット・デメリットを整理しました。
| 実装コスト | Pros | Cons | |
|---|---|---|---|
| テーブルのデータ量を削減する | 低 | 簡単に実行できる。 | 定期的に REINDEXしなければ、インデックスの断片化が進む。 |
| UUID v7やULIDなどの時系列でソート可能なIDをPrimary Keyに使用する | 低 | UUID v7の場合、すでにPrimary Keyの型にUUIDを使用していればテーブルの構成変更が発生しない。 | 人間が見て区別するときの視認性が悪い。 |
| Partition Tableを使って古いデータと新しいデータを分割する | 中 | アプリケーション側の実装は変わらない。 | 既存テーブルから変換することはできない。パーティションを定期的に追加する運用が必要になる。 |
| リードレプリカを使って読み込みと書き込みをわける | 高 | 書き込みと読み込みの責務を分けられるので、リソース割り当てが最適化される。 | Bill Oneではリードレプリカを使用しない構成を取っており、レプリケーションラグを考慮した実装への変更が必要になる。 |
| RDB以外の分散したキーに強いデータベースを使用する | 高 | データの増加によるパフォーマンス劣化が発生しなくなる。 | Google Cloud ではDatastore(DatastoreモードのFirestore)が候補となり、アプリケーションの実装変更が必要になる。Transactional Outbox パターンを実現する仕組みを整備する必要がある。 |
これらの案は、実装コストが大きいものほど効果が見込めそうではありました。 しかし、今回はなるべく早く問題を解決したかったことから対応コストの低いデータ量の削減とUUID v7への変更を進めました。
テーブルのデータ量を削減する
これは最もシンプルな方法でした。 レコード数を削減することでインデック自体を小さくしてしまい、キャッシュ効率を上げるというものです。 対象としていたテーブルは処理の瞬間の整合性を担保するために必要なもので、以降はログとしてしか使わないため一定以上古いデータは削除する判断が取れました。
UUID v7やULIDなどの時系列でソート可能なIDをPrimary Keyに使用する
UUID v7やULIDはともに128bitの時系列でソート可能なデータ型である特徴があります。 時系列でソート可能なデータ型を採用することでB-Treeインデックス上の再構築が必要なブロックを局所的にでき、キャッシュの効率が改善することを期待しました。
UUID v7とULIDの特性は似ているものの、ULIDを採用したときの次の課題があったため、UUID v7を採用しました。
- PostgreSQLの標準データ型でサポートされていない(アプリケーション側でUUID形式に変更することで使用はできる)
- UUID型への変換に追加のコストが発生する
- 文字列型で保存する場合、ストレージ効率が低下する
PostgreSQLのUUID型はUUID v4とUUID v7を同様に扱えるため、テーブルに対する変更はなく、アプリケーション側のUUID生成処理の差し替えのみで実装できています。
対策をとった結果
UUID v7への移行後、Primary Keyのインデックスに対するキャッシュヒット率に顕著な改善が見られました。
| キャッシュヒット率 | |
|---|---|
| UUID v7移行前 | 60% |
| UUID v7移行後 | 93% |
これにより、INSERTのパフォーマンスが改善され、非同期イベントの処理の安定性が向上しました。
まとめ
INSERTのみが大量に発生するテーブルのPrimary KeyをUUID v4からUUID v7に移行することで、INSERTのパフォーマンスを大幅に改善できました。 単純なINSERTでも、データ型やインデックスの特性を適切に扱うことで、データベースのリソースを効率よく使えます。 UUID v7は単一の書き込みデータベースが存在する環境では効果を発揮しましたが、シャーディングをしている環境ではUUID v4のもつ分散性の相性が良い場面もあります。 データベースの構成やデータ型、インデックスの種類に応じて適切に選択していく必要があります。
今後は、今回見送った方法の中でも効果の見込まれる方法を採用し、よりスケーラビリティの高い構成としていくことを考えています。
宣伝
Bill One 開発 Unit ブログリレー2024はまだまだ続きます!
ブログリレーの最新の投稿について@SansanTechでお知らせしますので、ぜひフォローしてください。
*1:https://cloud.google.com/run?hl=ja
*2:https://cloud.google.com/sql/docs/postgres?hl=ja
*3:Bill Oneではイベントの大量発行や流量制限などの特性に応じてCloud TasksとCloud Pub/Subを使い分けています。
*4:https://www.postgresql.jp/document/16/html/monitoring-stats.html