こんにちは。研究開発部のMengsay Loemです。現在は、帳票から情報を抽出・構造化する「データ化技術」の研究開発に取り組んでいます。
本記事では、Sansanにおける、Vision-Language Model(VLM)を用いた視覚的質問応答(VQA)による帳票からの情報抽出技術を紹介します。VLMをプロダクトで使えるレベルまで高めるために、どのように性能改善に取り組んできたか、その道のりと得られた知見を共有したいと思います。
帳票からの情報抽出とその課題
Sansanでは、内製の事前学習済みVLMをVQAタスクに応用し、帳票から情報を抽出する取り組みを行っています。具体的には、帳票画像に対して質問を投げかけ、その回答として必要な情報を抽出する手法です。
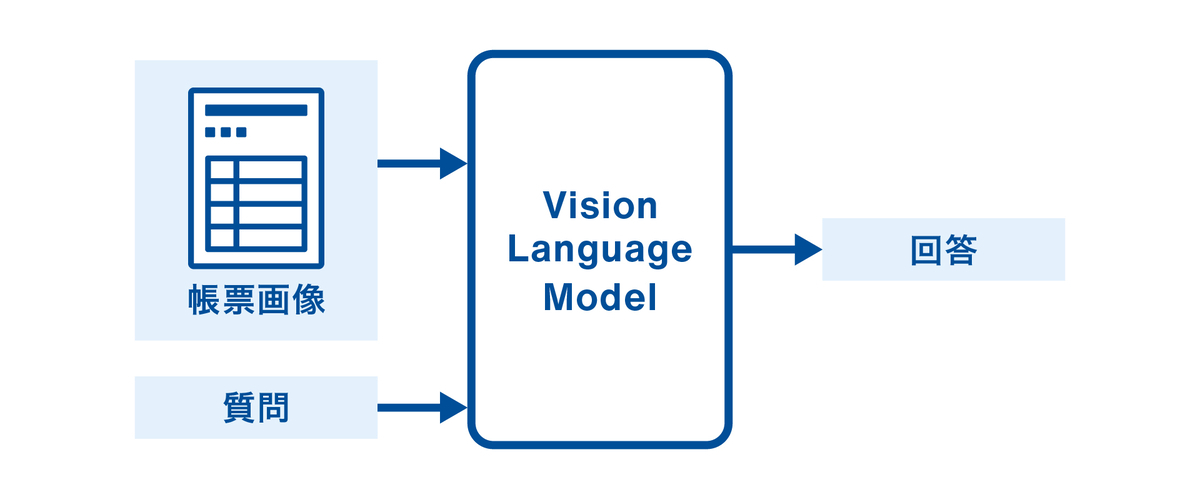
帳票からの情報抽出で課題となるのは、入力画像の多様性です。帳票は、ページ数やフォーマットが多様で、同じ項目でも場所や書き方が異なります。また、項目同士には意味的な依存関係もあるため、個別に抽出するよりも文脈を活かす学習設計が重要です。
本記事では、VLMのファインチューニングを通じて、いかに精度と学習効率を向上させてきたかをお伝えします。
とにかく大量データで押し切る
最初に我々が着手したのは、データ数をひたすら増やすアプローチです。大量の学習データを使うことで以下のことを狙っていました。
- 多様な帳票レイアウトへの汎化を実現する
- 特にレアケースの学習頻度を上げる
- 過学習を抑制する
その結果、学習データを増やせばモデルの性能が上がっていくことが確認されました。しかし、単純に学習データを増やすと、学習時間・計算リソースが増大するという課題に直面しました。この課題を乗り越えるため、次のステップとして、より効率的な学習設計を模索しました。
VQAにおける質問方法を工夫する
初期のアプローチでは、1つの帳票画像に対して複数の質問-回答ペアを用意し、各エポックでランダムに1つだけの質問-回答ペアをサンプリングして学習していました。この手法をSeparated VQAと呼ぶことにします。
Separated VQAでは、項目ごとに分離されているため、個別分析がしやすい反面、学習効率にはまだ改善余地がありました。具体的には、各画像に対してK個の項目があり、全体でN件の学習データが用意できたとします。この場合、1エポックあたりの1項目に関する学習(パラメータ更新)はN/K回になってしまい、1枚の画像から学習できる情報量が少ないです。また、各項目の抽出は独立して学習されるため、項目同士の関係性を生かしきれない可能性もあります。
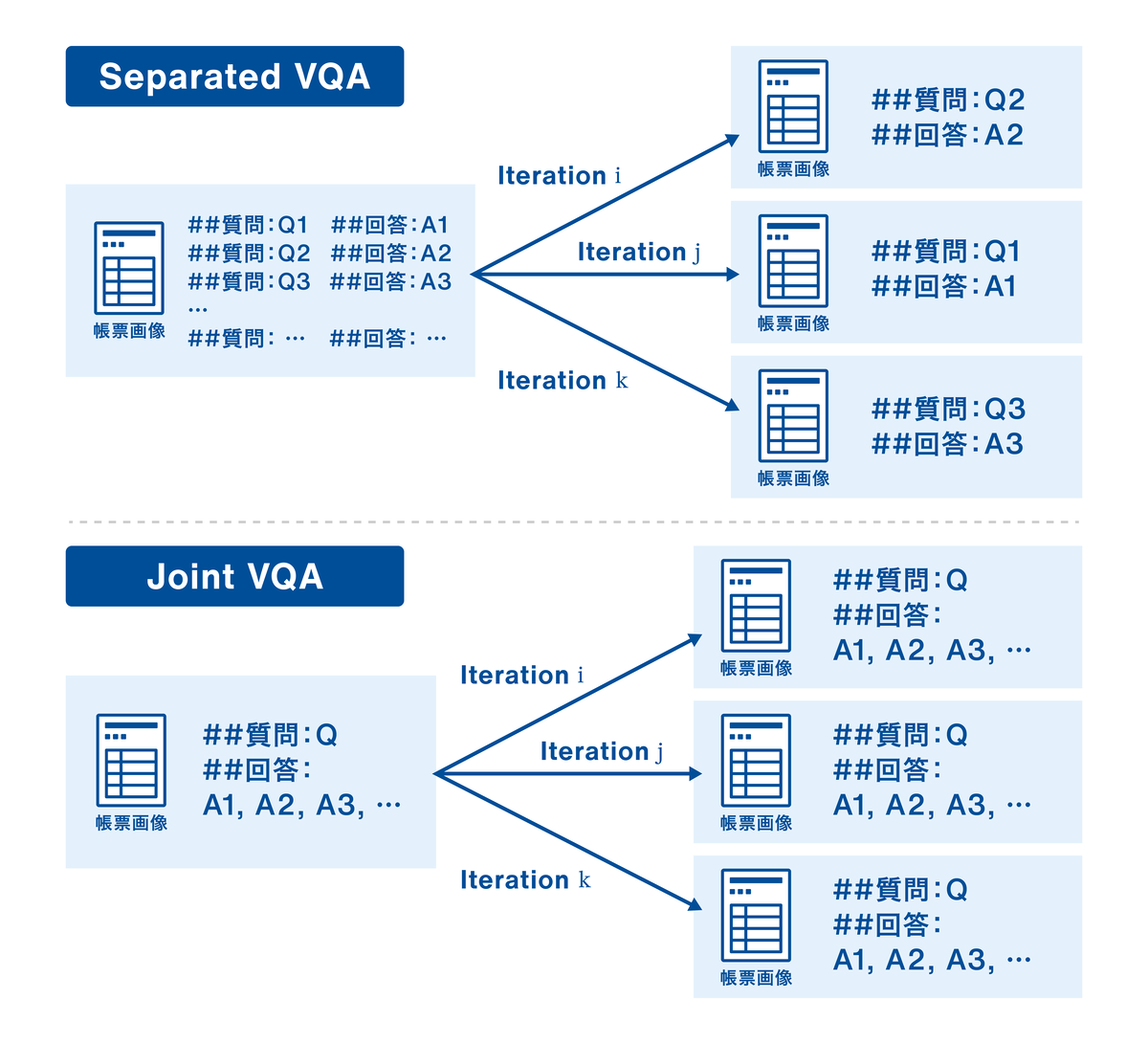
そこで、我々が次に試したのは、複数項目を1つの質問にまとめて回答させるJoint VQA方式です。上の図の下部にあるようにデータセットの形式にして学習を行いました。Joint VQAの場合は、一枚の入力画像から複数項目の出力を同時に学習するため、1エポックあたりの1項目に関する学習(パラメータ更新)はN回になり、Separated VQAのK倍になります。つまり、同じデータ量からより多くの学習信号を引き出すことになり、学習の効率化につながりました。また、厳密な検証は別で必要ですが、関連する項目をまとめて一つの質問-回答にすることで、モデルが項目間の関係性を同時に学習してくれる可能性も考えられます。
より良い入力を扱えるように
学習データの増加や質問形式の工夫により、情報抽出の精度を高水準で維持しながら、カバー率(抽出対象データに対して正しく抽出できる割合)も大幅に向上させることができました。しかし、まだいくつかの課題が残っています。
- 細かい文字の誤認識や、存在しない情報を生成してしまう(いわゆるハルシネーション)
- 入力画像が1枚に限定されており、複数ページの帳票への対応が不十分
ハルシネーションは、VLMを用いたVQAという生成的アプローチの特性上、完全には避けられない現象です。しかし、だからこそ「できる限り正しく」情報を抽出するための工夫が重要になります。生成モデルの限界を理解しつつ、実運用において「どこまで精度とカバー率を高められるか」という課題に取り組んでいます。そこで、「より良い視覚情報(解像度の向上)」と「現実に即した構造(複数ページ入力)」の2点を軸に改善を進めました。
ひとつ目の策として着目したのが入力画像の解像度向上です。帳票に記載された細かな文字や、かすれた文字列を正しく読み取るために、より高解像度の視覚入力が有効だと考え、画像サイズを拡大しました。その結果、小さな文字や補足説明といった細かい情報の読み取り精度が向上し、情報抽出の精度を底上げできました。
もう一つの策として、入力画像が1枚のみというモデルの制約に着目し、これを改善しました。実際のビジネス現場で扱う帳票は2ページ以上にわたることが少なくありません。例えば書類では、1ページ目に主要情報が集約され、2ページ目以降に詳細情報や補足説明などが記載されているケースがよくあります。これらを1枚の画像だけ(あるいは1枚ずつ)で処理するのでは、正確な情報抽出のカバー率に本質的な限界があります。そこで、最大4ページまでのマルチページ入力に対応するようにしました。技術的には、動画版のVLMで実現されている構造を流用し、複数枚の画像を扱う構造にモデルを改修しました。その結果、全体のカバー率をさらに向上させることができました。
確信度ベース再学習による実運用最適化
入力画像の解像度向上や複数ページ対応により、視覚的な情報量の不足による抽出ミスを一定程度改善できました。しかし、次に見えてきたボトルネックは、モデル自身が「正しい予測をしているにもかかわらず、自信がないためにその回答を捨ててしまう」という現象です。
このような「確信度が低い予測」に着目し、モデルの性能をさらに実運用レベルへと引き上げるための再学習を実施しました。
なぜ「確信度の低い予測」に注目するのか?
現行のモデルは、全体としては閾値を設けなくてもそこそこ高い正解率を達成しています。しかし、実運用では、予測の確信度(スコア)がある一定の閾値を下回った場合には、その出力を破棄するルールを設けています。このため、信頼できる出力に限定すると、実際のカバー率は一定の割合まで低下してしまいます。
つまり、正しく答えているのに、自信がないから出力されないという『もったいない』予測が多く存在しており、ここに改善の余地があると考えました。
確信度が低下する要因は大きく2つ
1. 学習データにほとんど登場しないパターン
例えば、外国語で記入された書類や特殊なレイアウトなどが該当します。これらはデータ全体に占める割合が小さいため、対応してもカバー率の改善幅は限定的です。さらに、事前検出が難しいケースも多く、一般的な対処が困難な状況です。
2. よくあるパターンだが、微妙な差異が存在するケース
具体的な例として、既知のテンプレートに似ているものの、文字の配置や表の形状がわずかに異なるケースや、画質やフォントの揺らぎによる違いが挙げられます。このような「似ているけど微妙に違う」ケースでは、モデルの確信度が下がってしまい、結果的に出力が捨てられてしまいます。ただし、これらは学習済み知識に近い領域であるため、少量の追加データで改善が見込めるポイントでもあります。
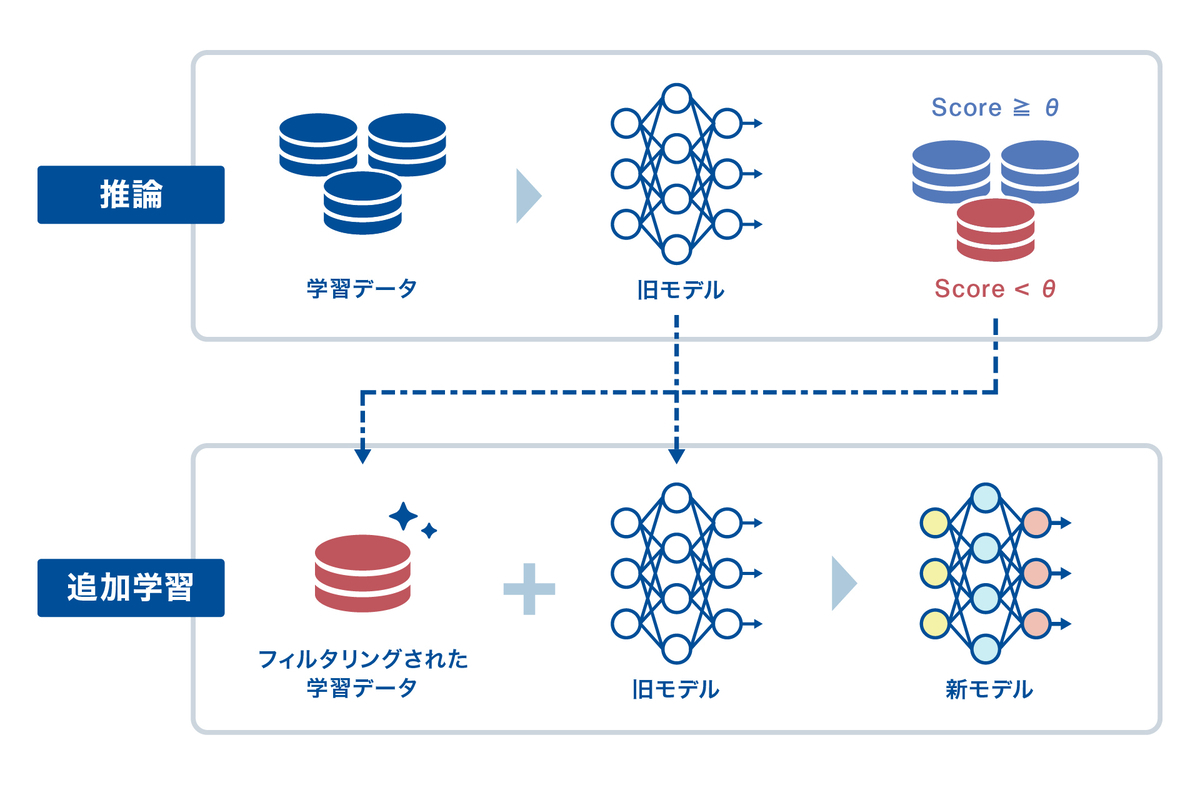
そこで、既存データセットに対し、モデルの推論時にスコアが低かったサンプルを自動で抽出し、それらを用いて再学習を行いました。意図としては以下の通りです:
- 微差によるスコア低下は、追加学習で埋めやすく、改善リターンが大きい
- 正解率は高いのに採用されないという非効率を減らすことで、カバー率向上が見込める
- 大量データの新規収集やアノテーションを行わず、コスト効率よく改善できる
再学習後、以前はスコア不足で破棄されていたケースの多くが確信度閾値を上回るようになり、実運用で採用可能な出力が増加しました。これは、予測内容そのものを大きく変えるのではなく、「既に持っている知識を正しく“自信を持って”出力できるようになった」とも言えます。
このように、推論時のスコア傾向に基づく再学習は、精度の底上げではなく、実際に使える出力の最大化という観点で非常に有効なアプローチとなりました。
よりスケーラブルで柔軟なモデル構築に向けて
現行モデルは一定の成果を上げている一方で、構造的な制限(最大トークン長・固定画像サイズ)によって、特定条件下で性能が頭打ちになるケースが確認されています。
こうした入力側の制約を技術的に緩和・解消する2つの施策に取り組んでいます。
長文入力対応:最大トークン長の拡張
書類によっては、詳細な説明が付随するケースが存在し、入力テキストがモデルのトークン上限を超えることがあります。その結果、一部情報がトリミングされ、モデルの判断材料が不足するという課題が生じていました。そこで、以下のような方針でこの課題への対応を模索しています:
- Position Embeddings(位置埋め込み)の上限を拡張し、長文テキストの切り捨てを防止
- 既存モデルの重みを活かしつつ拡張に対応(事前学習からの再構築は不要)
- (コスト効率よく)トークン数の上限変更を前提にした再ファインチューニングを実施
このような改良により、モデルが文書全体を把握できるようになり、情報欠落による性能劣化を抑制でき、スケーラブルで現場の文書特性に即した柔軟な対応力のあるモデル設計が可能になると期待できます。
実際に検証中の拡張手法では、以下の図のように、最大トークン数の拡張により、長い出力テキストを扱うタスクで性能が向上することが確認されています。
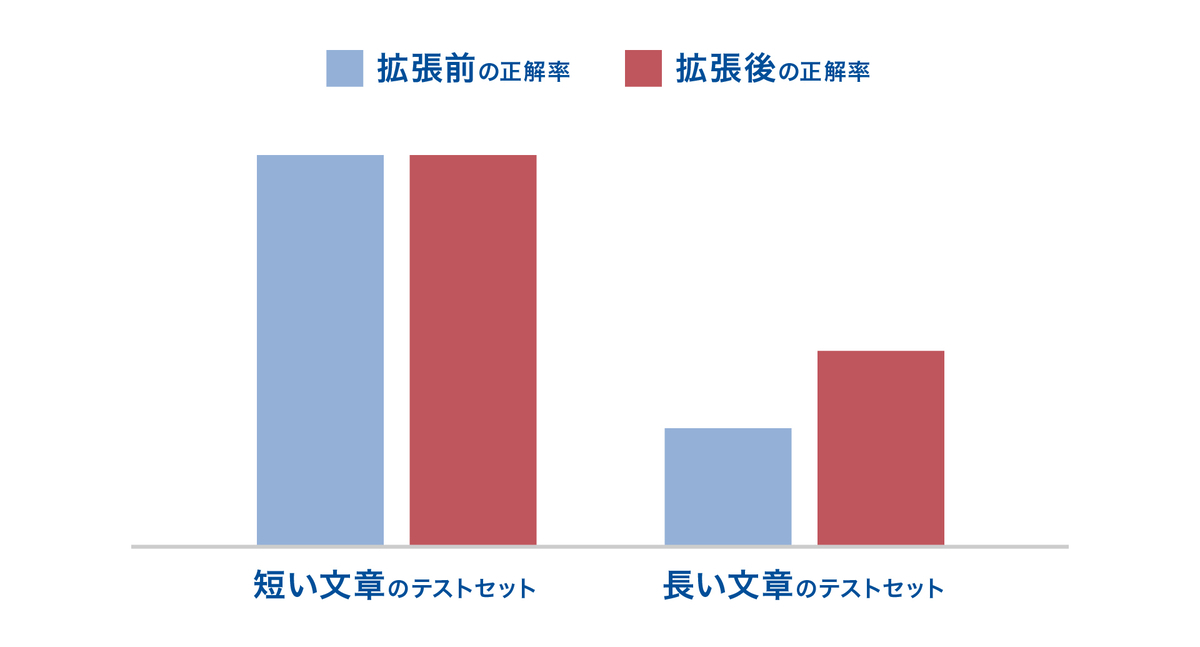
動的な画像サイズ入力:リサイズによる情報損失を避けるために
これまでのモデルでは、入力画像を固定サイズにリサイズして処理してきました。これは実装の簡便性を優先した設計でしたが、特に文字認識や位置に依存する情報抽出タスクでは、リサイズによる画質劣化が精度低下の原因となることがあります。
そこで、元の画像解像度を保持したまま、あるいは動的に適切な解像度で処理できる柔軟な画像入力方式の導入を検討しています。これにより、特に細かい文字や位置関係が重要なフィールド(例:品目リストや注釈など)の認識精度向上が期待されます。
Takeaways
今回のプロジェクトを通じて、いくつかの重要な学びがありました。
- 最も大きかったのは、「モデルの構造そのものはもちろん重要だが、それより、データの与え方(formulation)の方も性能に与える影響が大きい」という実感です。Separated VQA から Joint VQA へ移行したことで、当初試みていたどのモデル構造の改良よりも大きな改善が得られました。「何を使って学ばせるか」以上に、「どう教えるか」がモデル性能を左右する、そんな手応えがありました。
- また、小さな改善の積み重ねが最終的に大きな差を生むということも、改めて実感しました。画像解像度の向上、複数ページの取り込み、確信度の低い予測のフィルタリングなど、個々の施策は控えめな効果に見えましたが、積み重ねていくことで全体としての性能向上につながることが分かりました。
最後に
この取り組みに携わる中で、理想と現実のギャップを乗り越えながらモデルを育てる難しさと面白さを深く体感することができました。同時に、研究開発とは論文やモデル構造に限らず、訓練設計・データ設計・評価指標・運用性といった周辺の設計が極めて重要であるという気づきも改めて意識しました。
今回のように、「なんとなくのモデル改善」ではなく、明確な課題意識と構造的な工夫に基づく改良を重ねることで、より実用的で、拡張性のあるシステムを構築できるという手応えがあります。
この記事が、同じように日々試行錯誤を重ねている皆さんにとって、新たな視点やモチベーションの種となれば嬉しいです。
Sansan技術本部ではカジュアル面談を実施しています

Sansan技術本部では中途の方向けにカジュアル面談を実施しています。Sansan技術本部での働き方、仕事の魅力について、現役エンジニアの視点からお話しします。「実際に働く人の話を直接聞きたい」「どんな人が働いているのかを事前に知っておきたい」とお考えの方は、ぜひエントリーをご検討ください。