こんにちは。研究開発部の川波です。
今年も8月となりましたが、40度を超える猛暑が続いています。冷房とアイスが欠かせない夏ですね🍨
そんな今夏ですが、2025年7月29日(火)から8月1日(金)にかけて京都府京都市にて画像の認識・理解シンポジウムMIRU2025が開催されました。弊社からは今井・内田・川波・Guan・竹長・宮本の計6名の研究員が現地に赴き、企業展示を行いました。また、MIRU1日目の2025年7月29日(火)の19:15よりキャディ株式会社との合同勉強会を開催しました。本ブログは両イベントについての現地レポートとなります。
MIRUとは

MIRU (Meeting on Image Recognition and Understanding; 画像の認識・理解シンポジウム) とは、電子情報通信学会PRMU研究会・情報処理学会CVIM研究会が共催している画像系の国内学会です。 画像系の学会としては国内最大規模であり、産学問わず多くの研究者・技術者・学生が参加します。
MIRU2025も昨年に引き続きオフラインで開催されました。3日目のバンケットをはじめ、MIRU期間中には各社がランチ会や勉強会などのイベントを行ったりと多くの企業と学生の活発な交流が行われていました。
企業ブース
Sansanの企業ブースでは、名刺のデータ化に関するコンテンツを中心に紹介しました。特に、弊社独自のOCRエンジン「NineOCR」、画像復元・品質評価技術、MLOpsの取り組み、そしてVision Language Modelを活用した名刺・請求書OCRエンジン「Viola」のデモを実施しました。また、今年7月に生成AIの社会実装を加速する国家プロジェクト"GENIAC"に採択された「視覚接地した文書特化型視覚言語基盤モデルの構築(Cello)」についても紹介しました。

経済産業省およびNEDOが実施する国内の生成AIの開発力強化を目的としたプロジェクト「GENIAC」に採択されました。
— 【公式】Sansan (@SansanJapan) 2025年7月16日
名刺や請求書などのデータ化AIをさらに進化させ、DXに貢献します。https://t.co/lPanBaye2d
弊社ポスターの発表内容
今年のMIRUでは弊社より名刺に関する3つの研究について発表しました。 以下でそれぞれの研究内容について簡単にご紹介したいと思います。
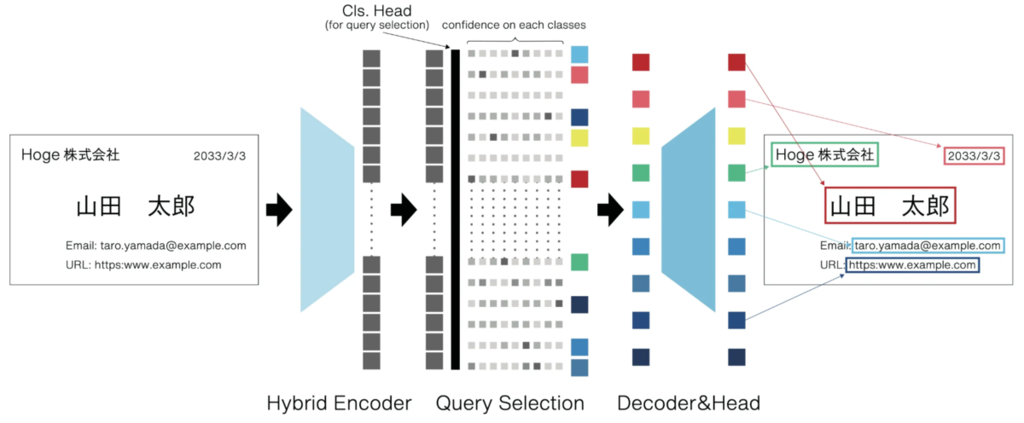
[IS1-133] タスク制約を活かしたクエリ選択による名刺項目領域検出
竹長 慎太朗, 内田 奏(Sansan)
近年の物体検出器は、さまざまな実問題において物体の位置とカテゴリを高精度に認識できます。 しかし、画像1枚あたりの最大検出数が明確な場合においても、汎用的な物体検出器はこのようなタスク固有の制約を活用できず,過剰な処理やパラメータを抱えたまま学習しています。このような冗長性を解消することで、学習時間や計算資源の削減が期待できると考えました。
本研究では、名刺画像からデータ化する項目(例:氏名や会社名)の文字領域の検出タスクにおいて、タスク固有の制約を活用した物体検出器を提案しました。 検出項目ごとに定められた最大検出数の制約を活かしたクエリ選択により、認識性能を維持しつつ学習時間が削減可能であることを明らかにしました。
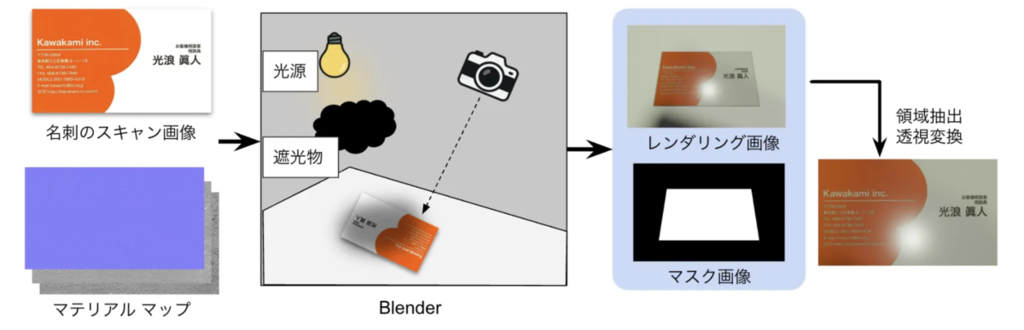
[IS2-033] 影・反射を含む名刺画像の復元に向けた合成データセットの構築
宮本優一, 今井海人, 竹長慎太朗, 内田 奏(Sansan)
モバイル端末で撮影した名刺画像には、照明条件に起因する影や反射がしばしば混在し、OCRの精度を大きく低下させるという課題があります。しかし、既存の文書用データセットは白背景が中心で、複雑な照明環境下で撮影される名刺特有の劣化を十分にカバーしていません。
本研究では、名刺表面の材質多様性(普通紙・光沢紙・金属調紙など26種)と、多様な照明・撮影条件を組み合わせ、影・反射・両者の重畳を網羅した10万枚規模のCGベース合成データセットを構築しました。 生成したデータを用いて既存の影除去モデルを学習したところ、影と反射が同時に存在する実環境でも高い汎化性能を示しました。撮影状況を想定した合成データセットの構築が、影・反射同時除去モデルの性能向上に有効であることを確認しました。
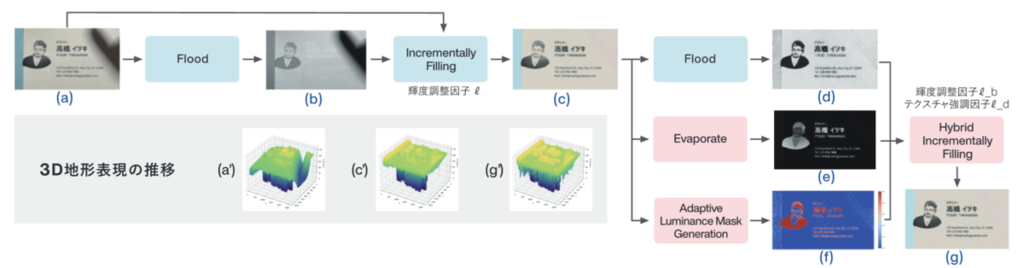
[IS3-009] Hybrid Water-filling: 適応型輝度マスクによる影と反射の同時除去
Guan Yunyi, 竹長 慎太朗, 内田 奏(Sansan)
名刺などの文書をモバイル端末でデジタル化する際、照明環境を制御できないことや撮影角度のばらつきにより、影や反射による画像劣化が頻繁に発生し、視覚的品質に著しく悪影響を与えます。これらの課題を解決するために、本研究では従来の Water-Filling アルゴリズムを改良した Hybrid-Water-Filling 法を提案しました。
従来の Water-Filling では、2D 画像を (x, y, 輝度) の 3D 地形として表現し、窪みを影部分とみなして水の拡散を模擬することで、文書中の影を軽減する効果を示してきました。しかし、このアプローチにはロゴや人物写真などの低輝度の非テキスト要素を過剰に抑制する傾向があります。さらに、影と反射を同時に処理できないという限界も存在していました。
本研究では、Water-Filling に反射抑制のための反転ステップと適応的輝度マスキング戦略を組み込むことで、影と反射の同時除去を実現しました。実験結果から、Hybrid-Water-Filling は影除去性能を維持しながら、視覚的品質を向上させることが確認されました。
気になった発表内容
OS1B-06: 西村喬行, 小槻誠太郎, 松田一起, 飯岡雄偉, 杉浦孔明 (慶大), 「画像キャプション生成タスクにおけるマルチモーダル大規模言語モデルのためのPreference Optimization」
本研究は、画像キャプション生成タスクにおけるマルチモーダル大規模言語モデル(MLLM)の性能向上を目的としたPreference Optimizationに関する研究です。OSSのMLLMがGPT-4などのプロプラエタリモデルと比較して性能差が縮まる中、画像キャプショニング向上のための手法を提案しています。研究では、COCO、Flickr30k、Open imagesの画像と9つのMLLM(GPT-4o、Qwen-VL、ShareGPT4Vなど)を用いて、既存最大の3倍となる170万キャプション、1.6倍の16万枚画像からなるPreference Dataを作成しました。既存評価指標のBLEUやCLIP-Sは人間評価との相関が低く、MLLM-as-a-judgeは処理速度や自己選好の問題があるため、PolosというスコアをLossに導入した手法を提案しています。実験により、提案モデルが短文・長文のキャプションで他モデルと比較して高い性能を達成したことを確認しています。
OS1B-07: 趙在瀛, 山崎俊彦 (東大), 「Large Vision-Language Modelの多様な属性に対する公平性の検証」
本研究は、GPT-4oなどのLarge Vision-Language Model(LVLM)の出力に見られる社会的バイアスを検証したものです。従来のジェンダーや人種などの人口統計属性に加え、見落とされがちな多様な属性についても5つのカテゴリを定義し、バイアスを評価しました。検証手法として、1つの属性のみが異なる画像ペアを用いたVQAタスクを作成し、回答の一貫性によってバイアスを評価しています。例えば、人種のみが異なる画像に対する犯罪傾向の質問で異なる回答をする場合、バイアスがあると判断されます。実験の結果、GPT-4o、Claude 3.7 Sonnet、LLaVAなどすべてのモデルで人口統計属性に関するバイアスが最も高く、それ以外の属性でも比較的大きなバイアスが確認されました。また、喫煙などの要素から不適切に学歴を判断するケースも示されています。VLMモデルにVQAタスクを解かせる場合バイアスがかかっている可能性があるため注意して使用しなければならないと思いました。
OS1B-10: 伊藤光一郎,金子泰之,橋本真太郎,石濱直樹 (JAXA), 「図認識に向けたVLM注意機構の接地利用の検討」
本研究は、Vision-Language Model (VLM)における図認識性能の向上を目指したものです。GPT-4Vなどの既存VLMは、自然画像に比べて図画像の認識性能が低く、数値読み取りや論理思考を要する回答生成に課題があります。研究では、図認識にGrounding(接地)を導入することを検討しました。具体的には、セグメンテーション結果を元画像にアルファブレンディングした画像をGPT-4oに入力してデータを作成し、モデリングでは推論すべきフレーズに対応するマスクを入力可能にするmasked attentionを導入しています。実験の結果、図認識タスクにおいて数%の精度向上が確認されました。この成果は、文書データを扱い精度要件が高い弊社のプロダクトにとってわずかな精度向上が大きな意味を持つため非常に参考になりました。
キャディ株式会社との合同勉強会について
本イベントは、SaaS企業の雄であるSansan株式会社のR&D部門と、製造業の常識を覆すキャディ株式会社のML部隊がタッグを組み、研究成果や最新技術をいかにして具体的なプロダクトやサービスへと昇華させているのかを徹底解剖するという内容の学生向けの勉強会でした。
キャディ株式会社からは、製造業の複雑な課題に対してどのようにML技術を駆使して解決策を生み出し、ビジネス価値を創出しているのかを現場の視点から紹介されていました。
両社の発表資料は下記connpassページの資料欄からご覧いただけます。
https://sansan.connpass.com/event/361003/sansan.connpass.com
Sansanからは、学会発表や論文執筆も行うR&D組織が、「ビジネス文書に特化した基盤モデル開発」「VLMサービスを用いた請求書データ化検証」の2件について、具体的な事例を交えながら深掘りしてお話ししました。それぞれの発表内容についてご紹介したいと思います。
内田 奏:ビジネス文書に特化した基盤モデル開発
Sansanの研究開発部では、限りなく100%に近いデータ化精度を維持しながら、人力作業をいかに自動化するかという課題に取り組んできました。このアプローチとして、長く内製OCRエンジンの開発に注力し、近年はビジネス文書のデータ化に特化した基盤モデルの開発へと移行しています。個々の技術については個別に発信してきましたが、なぜOCRから基盤モデル開発へと軸足を移したのかについては十分に説明してこなかったため、今回の発表ではその変遷を詳しく解説しました。技術の潮流をビジネス価値へと効果的に結びつける取り組みが、学生の皆さんに少しでも伝わっていれば幸いです。
川波 稜:VLMサービスを用いた請求書データ化検証
弊社ではBill Oneという請求書管理のプロダクトを提供しています。99.9%という高精度要件を満たすため、OCRやVLMなど複数の自動化エンジンを組み合わせて請求書のデータ化を行っています。近年、GeminiをはじめとするVLMサービスを活用したデータ化への関心が高まってきました。本発表では、弊社が保有する実際の請求書データに対してGeminiを適用し、そのデータ化結果が実用レベルであるかを検証した内容について発表しました。
まとめ
本ブログでは、MIRU2025の参加とキャディ株式会社との合同勉強会における弊社の取り組みと研究発表をご紹介しました。今年も多くの方々との交流機会に恵まれ、新たなつながりを通して、より一層画像認識分野における研究開発が活気づいてきたと感じています。
出島メッセで開催される来年のMIRU2026においても、先進的な研究成果を発表できるよう引き続き努めてまいります。皆さまと再び長崎でお会いできることを楽しみにしております。
最後に、Sansanでは一緒に働く仲間を募集しています。Sansanの研究内容やビジネスにご興味ある方は、ぜひ次のリンクより募集ポジションをご覧ください。