この記事は、Bill One 開発 Unit ブログリレー 2025 の第 2 弾になります!

こんにちは、技術本部 Bill One Engineering Unit の藪下(@yatsbashy)です。
今回はマイクロサービス間の非同期メッセージングで発生していたつらみの改善についてご紹介したいと思います。
マイクロサービスが増えると、メッセージング基盤の運用の手間も比例して増えていきます。Bill One では、Google Cloud Pub/Sub のデッドレター管理を見直し、BigQuery サブスクリプションを活用したシンプルかつ拡張性の高い設計へ刷新しました。
目次
- 目次
- 1. はじめに:Bill One のメッセージ処理とデッドレター
- 2. 改善が必要だった理由
- 3. 現在のアーキテクチャ
- 4. 比較した選択肢とトレードオフ
- 5. まとめ
- 6. 参考
- Sansan技術本部ではカジュアル面談を実施しています
1. はじめに:Bill One のメッセージ処理とデッドレター
Bill One では複数のマイクロサービスが連携しながら処理を行っています。連携基盤のひとつとして Google Cloud Pub/Sub による非同期メッセージングを採用しています。
Pub/Sub は高スループットかつ疎結合な通信を実現できる一方、メッセージ処理に失敗した(=デッドレター / dead letter)場合をどう扱うかが運用上の要点になります。失敗メッセージを放置すればデータ整合性や再送制御に影響し、逆に過剰なログ/アラート運用はチームの負荷になります。
本記事では、Bill One がこのデッドレター管理をどのように改善し、現在どのように運用しているかを解説します。
2. 改善が必要だった理由
当初、Bill One では Cloud Run functions(旧称:Cloud Functions)と Cloud Datastore を組み合わせた独自の仕組みで、デッドレターメッセージの保存と再送を行っていました。
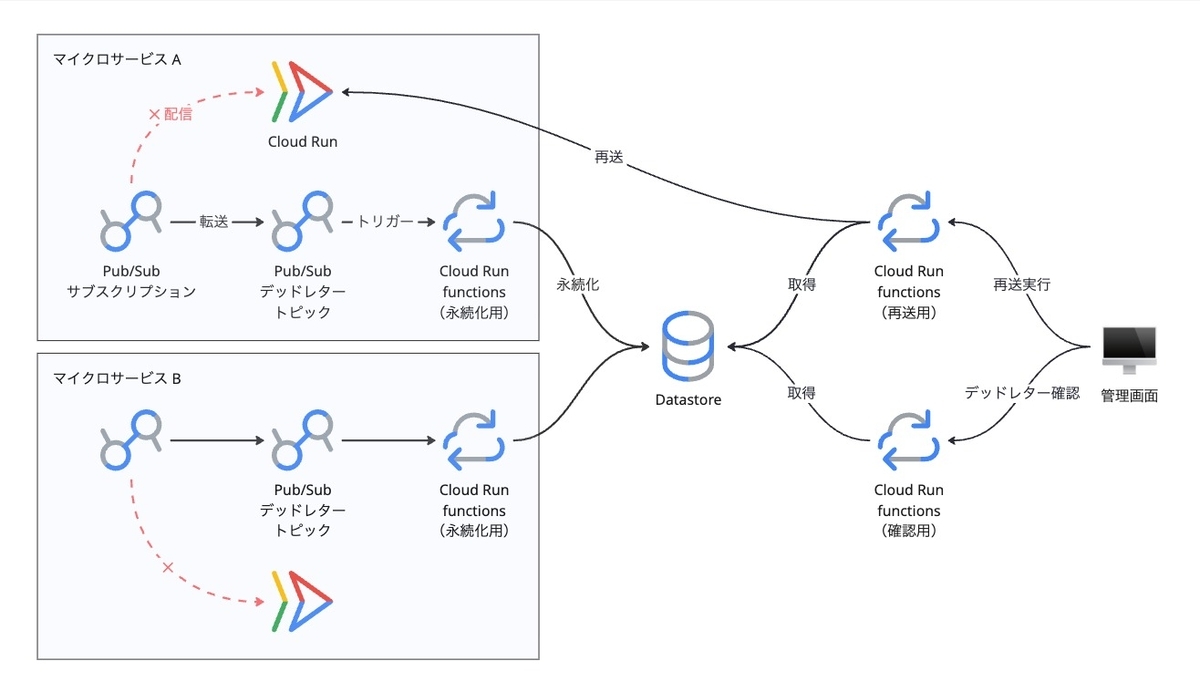
各マイクロサービスの Pub/Sub サブスクリプションごとにデッドレタートピックを用意し、そのトピックをトリガーに Cloud Run functions が Datastore へメッセージを永続化します。運用管理画面からメッセージを確認・再送するために、Datastore から取得する関数と、マイクロサービスへ再送する関数を実装していました。
小規模な構成では合理的でしたが、サービスが増えるにつれて次の課題が顕在化しました。
- マイクロサービス追加時にデッドレタートピックの作成が漏れる。
- 関数の数がマイクロサービスとともに増えるため、その分デプロイ時間も伸びて運用負荷が高くなる。
- 共通ロジックや型定義が関数ごとに分散し、修正やテストの整備が難しい。
- Datastore の 1 MB制限により、Pub/Sub の最大メッセージサイズ(10 MB)と不整合が生じる。
最初はシンプルだった設計が、スケールとともに複雑化していきました。そこでデッドレターの扱いを根本から再設計することにしました。
3. 現在のアーキテクチャ
上記の課題を解消するため、BigQuery サブスクリプションを利用した共通デッドレタートピック構成に移行しました。これにより、各マイクロサービスが発行する Pub/Sub メッセージのデッドレターを 1 つの共通トピックに集約し、保存までをマネージドで実行できるようになりました。
Datastore へ永続化するための Cloud Run functions を個別に管理する必要がなくなり、運用コストを大きく削減しました。さらに、メッセージの取得/再送用の運用 API を Cloud Run functions の単一サービスとして提供し、管理対象を減らしました。
アーキテクチャ概要

各マイクロサービスは通常トピック経由でメッセージを発行し、サブスクリプションは配信失敗時に共通デッドレタートピックへメッセージを自動転送します。BigQuery サブスクリプションがこのトピックを購読し、メッセージを BigQuery テーブルへ永続化します。運用時は管理画面から Cloud Run functions を呼び出し、BigQuery からメッセージを取得・再送します。
構成上のポイント
1. デッドレタートピックを全サービスで共有
以前はマイクロサービスごとにデッドレタートピックを作成していましたが、現在はプロジェクト全体で 1 つの共通トピックに統合しました。Pub/Sub 側でデッドレターメッセージにサブスクリプション名がメタデータとして付与されるため、どのサービスから発生したメッセージかは後段で容易に識別できます。これにより、新しいサービス追加時もトピック作成が不要になり、設定ミスを防止できました。
2. BigQuery へのマネージドな永続化
従来の Datastore への永続化をやめ、BigQuery サブスクリプションを採用しました。理由は大きく次の2つです。
- Pub/Sub の最大 10 MB のメッセージサイズへの対応
- メッセージを永続化する Cloud Run functions の廃止
BigQuery の行サイズは最大 100 MB ですので、Datastore では対応できなかったサイズのメッセージも保存できるようになりました。BigQuery サブスクリプションはトピックへ発行されたメッセージを自動で BigQuery テーブルへエクスポートしてくれるので、これまで自前実装していた Cloud Run functions が不要になりました。
またメッセージとメタデータに対して BigQuery の SQL による柔軟な検索・分析ができるようになったのもポイントです。
3. 運用 API を単一の Cloud Run functions に統合
従来は「取得」「再送」で別実装でしたが、これらを Cloud Run functions の単一サービスに統合しました。
ルーティングによって複数の機能を 1 つのサービスに実装することでコードの分散を防ぎ、ロジックや型定義を共通化しました。こうして実装時に変更漏れが発生するリスクとデプロイ手間を同時に抑制しています。
4. 比較した選択肢とトレードオフ
採用した方針以外にも選択肢がありました。その中からいくつかご紹介します。
お見送り:デッドレター専用のマイクロサービスを構築
Bill One のマイクロサービスは Cloud Run で運用しているため、デッドレターメッセージの永続化や再送のための専用サービスを Cloud Run functions で構築する案も検討しました。
しかし、デッドレターの発生頻度は低く、必要機能も限定的でした。そこで、永続化はマネージド(BigQuery サブスクリプション)に任せ、運用機能は最小の Cloud Run functions に集約する方針を採用しました。
お見送り:Cloud Storage サブスクリプションを使用
BigQuery と同様、デッドレターメッセージをマネージドに保存する方法として Cloud Storage サブスクリプションも候補でした。
Datastore の 1 MB 制限を回避できる一方、メッセージがオブジェクトとして保存されるため、メタデータを含めた検索/分析の実効性では BigQuery に軍配が上がりました。
総括:採用方針が最適だった理由
共通デッドレタートピック + BigQuery サブスクリプション + 単一 Cloud Run functions という構成は、以下を最小コストで同時に満たすと判断しました。
- 保守点の削減(自作永続化の廃止、運用機能の集約)
- スケール対応(新サービス追加時の配線/設定手数の最小化)
- データ実用性(10 MB までのメッセージ、SQL による横断分析/抽出)
Datastore の 1 MB 制限や複数関数の管理といったボトルネックを根本解消し、運用のシンプルさと拡張性の両立を実現できました。
5. まとめ
マイクロサービスが増えるほど、デッドレター運用は後回しになりがちです。私たちは当初の「サービスごとのデッドレタートピックと Cloud Run functions と Datastore」という構成から、共通デッドレタートピック + BigQuery サブスクリプション + 単一の Cloud Run functions に切り替えました。その結果、運用の手数を減らし、新しいサービスの追加にも素早く対応できるようになりました。
今後も、監視や再送フローの使い勝手を継続的に見直し、運用コストを着実に減らしていきます。
6. 参考
- Pub/Sub ドキュメント | Google Cloud Documentation
- Cloud Run 関数のドキュメント | Cloud Run functions | Google Cloud Documentation
Sansan技術本部ではカジュアル面談を実施しています

Sansan技術本部では中途の方向けにカジュアル面談を実施しています。Sansan技術本部での働き方、仕事の魅力について、現役エンジニアの視点からお話しします。「実際に働く人の話を直接聞きたい」「どんな人が働いているのかを事前に知っておきたい」とお考えの方は、ぜひエントリーをご検討ください。